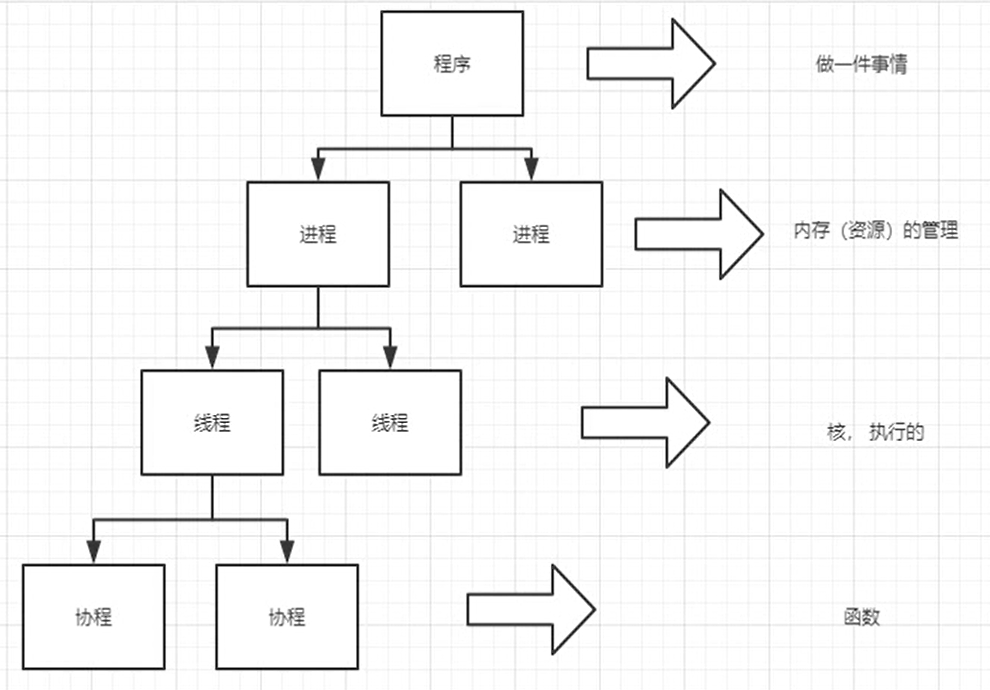
进程线程
每一个程序的执行,都至少要包含一个进程;一个进程里面至少要包含一个线程
以下程序有四个进程,四个线程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| from multiprocessing import Process
import time
def tell_me_your_name(name):
print('start:', name)
time.sleep(2)
print('end:', name)
if __name__ == '__main__':
start_time = time.time()
p1 = Process(target=tell_me_your_name, args=('caicaicai',))
p2 = Process(target=tell_me_your_name, args=('zizizi',))
p3 = Process(target=tell_me_your_name, args=('ningningning',))
p1.start()
p2.start()
p3.start()
p1.join()
p2.join()
p3.join()
print(time.time() - start_time)
|
新建线程的时间比新建进程的时间短,并发时,切换的速度比进程快
以下程序有1个进程,四个线程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| import threading
import time
def tell_me_your_name(name):
print('start:', name)
time.sleep(2)
print('end:', name)
if __name__ == '__main__':
start_time = time.time()
t1 = threading.Thread(target=tell_me_your_name, args=('xiaoxiao',))
t2 = threading.Thread(target=tell_me_your_name, args=('xingxing',))
t3 = threading.Thread(target=tell_me_your_name, args=('jiajia',))
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
print(time.time()-start_time)
|
进程池
每一个任务一个进程,100个任务的情况下,限制进程的数量.如果我们的任务更多,10000个,频繁的创建进程和销毁进程,也会造成性能损失,所以引入进程池的概念
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| import time
from multiprocessing import Pool
def tell_me_your_name(name):
print('start:', name)
time.sleep(2)
print('end:', name)
if __name__ == '__main__':
start_time = time.time()
pool = Pool(processes=3)
names = ['xiaoxiao', 'tongtong', 'ningning', 'chongchong']
for name in names:
print(name)
pool.apply_async(func=tell_me_your_name, args=(name,))
pool.close()
pool.join()
print(time.time() - start_time)
|
协程
-
不需要多启动进程或者线程
-
进程和线程的切换回比较耗时
-
协程不需要cpu的切换功能
-
yield的实现方式,如: yield XXX 或 xxx = yield / send
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| import gevent
from gevent import monkey
import time
import requests
monkey.patch_all()
def tell_me_your_name(name):
print('start:', name)
response = requests.get('http://www.baidu.com', verify=False)
print('end:', name)
if __name__ == '__main__':
g1 = gevent.spawn(tell_me_your_name, 'adam')
g2 = gevent.spawn(tell_me_your_name, 'eva')
g3 = gevent.spawn(tell_me_your_name, 'bob')
g4 = gevent.spawn(tell_me_your_name, 'alice')
gevent.joinall([g1, g2, g3, g4])
|
代理
代理相关的网站: 1. 66ip.cn, 2. data5u.com, 3. xicidaili.com, 4. goubanjia.com, 5. xdaili.cn, 6. kuaidaili.com, 7. cn-proxy.com, 8. proxy-list.org66ip.cn, 9. data5u.com, 10. xicidaili.com, 11. goubanjia.com, 12. xdaili.cn, 13. kuaidaili.com, 14. cn-proxy.com, 15. proxy-list.org
1
2
3
4
5
6
7
8
9
10
11
12
| import requests
proxy = '59.57.148.221'
proxies = {
'http': 'http://' + proxy+':9999',
'https': 'https://' + proxy+':9999'
}
try:
res = requests.get('http://httpbin.org/get', proxies=proxies)
print(res.text)
except requests.exceptions.ConnectionError as e:
print('error', e.args)
|
1
2
3
4
5
6
7
| from selenium import webdriver
proxy = '59.57.148.221'
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--proxy-server=http://' + proxy+":9999")
browser = webdriver.Chrome(chrome_options=chrome_options)
res = browser.get('https://www.baidu.com/s?wd=ip')
|

 wechat
wechat alipay
alipay