requests模块的使用
1 2 3 4 5 6 7 8 9 10 11 12 13 import requestsimport jsonurl = 'https://fanyi.baidu.com/sug' form = { 'kw' : '黄色' , } response = requests.post(url, data=form) res_dict = json.loads(response.text) print (res_dict)
有道翻译的爬取
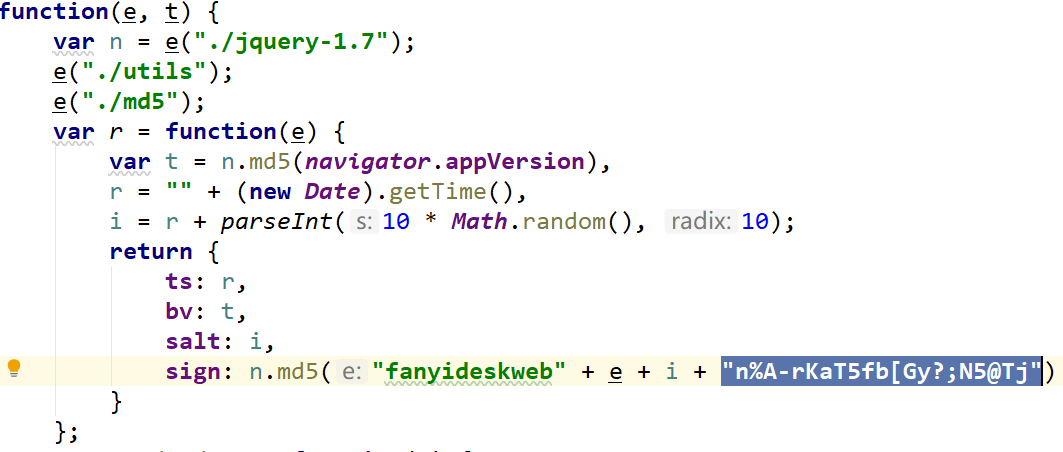
找到翻译内容的network数据所在,点击后面的initiator,找到js,再把js在线格式化,放入python文件同级目录下,打开js,找到加密方法,如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 import requestsimport jsondef translate (key ): import time ts = int (time.time() * 1000 ) import random salt = str (ts + random.randint(0 , 10 )) sign = "fanyideskweb" + key + salt + "n%A-rKaT5fb[Gy?;N5@Tj" import hashlib lmd5 = hashlib.md5() lmd5.update(sign.encode('utf-8' )) sign_md5 = lmd5.hexdigest() form = { 'i' : key, 'from' : 'AUTO' , 'to' : 'AUTO' , 'smartresult' : 'dict' , 'client' : 'fanyideskweb' , 'salt' : salt, 'sign' : sign_md5, 'ts' : ts, 'bv' : '4b1009b506fa4405f21e207abc4459fd' , 'doctype' : 'json' , 'version' : '2.1' , 'keyfrom' : 'fanyi.web' , 'action' : 'FY_BY_REALTIME' , 'typoResult' : 'false' , } headers = { 'Referer' : 'http://fanyi.youdao.com/' , 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36' , 'Cookie' : 'OUTFOX_SEARCH_USER_ID=717705358@10.169.0.83; JSESSIONID=aaaf_u-JXSbTm4g1X5m6w; OUTFOX_SEARCH_USER_ID_NCOO=1759410959.7206407; ___rl__test__cookies=1574324686939' , } url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule' response = requests.post(url, data=form, headers=headers) res_dict = json.loads(response.text) print (res_dict) print (res_dict['translateResult' ][0 ][0 ]['tgt' ]) if __name__ == '__main__' : while True : key = input ('饶氏翻译, 请说出你想翻译的内容:\n' ) if key == 'q' : break translate(key)
微博博主的爬取并保存在数据库
前往微博手机版 ,搜索博主,发现XHR里的ajax的General/Request URL的规律为地址后加&page=
在项目导入依赖,即w3lib,pymysql
创建weibo_test表,新建mysqlhelper.py ,并输入;报错:‘类名’ object has no attribute ‘cursor’,说明cursor不存在,即开始连接就错误了
1 2 CREATE TABLE weibo_test(id int primary key auto_increment, comments_count int, attitudes_count int, created_at varchar(40), `text` text) default charset=utf8mb4;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import pymysqlclass MysqlHelper (object ): def __init__ (self ): self.conn = pymysql.connect(host='localhost' , port=3306 , passwd='123456' , user='root' , db='pymysqls' , charset='utf8mb4' ) self.cursor = self.conn.cursor() def execute_insert_sql (self, sql, data ): self.cursor.execute(sql, data) self.conn.commit() def __del__ (self ): self.cursor.close() self.conn.close() if __name__ == '__main__' : helper = MysqlHelper() insert_sql = 'INSERT INTO weibo_test(comments_count,attitudes_count,created_at,`text`) VALUES(%s, %s, %s, %s)' data = (2 , 3 , '1990-05-14' , '今天有长长了哦' ) helper.execute_insert_sql(insert_sql, data)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 import requestsimport jsonfrom w3lib.html import remove_tagsfrom mysqlhelper import MysqlHelperhelper = MysqlHelper() headers = { 'Accept' : 'application/json, text/plain, */*' , 'MWeibo-Pwa' : '1' , 'Referer' : 'https://m.weibo.cn/u/1312412824?uid=1312412824&t=0&luicode=10000011&lfid=100103type%3D1%26q%3D%E6%9E%97%E5%BF%97%E7%8E%B2' , 'User-Agent' : 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Mobile Safari/537.36' , 'X-Requested-With' : 'XMLHttpRequest' , 'X-XSRF-TOKEN' : '466897' , } def get_one_page_info (url ): response = requests.get(url, headers=headers) res_dict = json.loads(response.text) cards_list = res_dict['data' ]['cards' ] for card in cards_list: if 'mblog' in card: comments_count = card['mblog' ]['comments_count' ] attitudes_count = card['mblog' ]['attitudes_count' ] created_at = card['mblog' ]['created_at' ] text = remove_tags(card['mblog' ]['text' ]) insert_sql = 'INSERT INTO weibo_test(comments_count,attitudes_count,created_at,`text`) VALUES(%s, %s, %s, %s)' data = (comments_count, attitudes_count, created_at, text) helper.execute_insert_sql(insert_sql, data) if __name__ == '__main__' : for i in range (100 ): print (i) url = 'https://m.weibo.cn/api/container/getIndex?uid=1211441627&t=0&luicode=10000011&lfid=100103type%3D1%26q%3D%E5%85%AD%E5%B0%8F%E9%BE%84%E7%AB%A5&type=uid&value=1211441627&containerid=1076031211441627&page={}' .format (i+1 ) get_one_page_info(url)
爬取数据过多,容易被封,不给继续爬取,程序报错如下


 wechat
wechat alipay
alipay


