可变和不可变集合
根据容器中元素的组织方式和操作方式,可以分为有序和无序、可变和不可变等不同的容器类别 ;
不可变集合 是指集合内的元素一旦初始化完成就不可再进行更改,任何对集合的改变都将生成一个新的集合;
可变集合 提供了改变集合内元素的方法;
Scala同时支持可变集合和不可变集合,主要下面两个包:
对于几乎所有的集合类,Scala都同时提供了可变和不可变的版本。
Scala优先采用不可变集合 ,不可变集合元素不可更改,可以安全的并发访问。
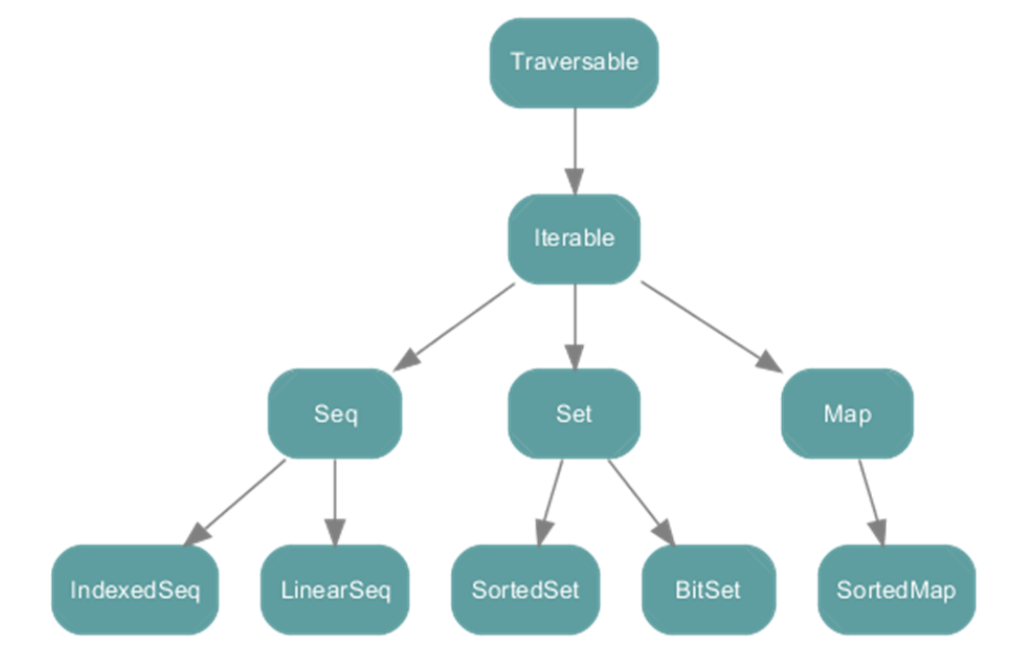
Scala集合有三大类:Seq(序列)、Set(集)、Map(映射);
所有的集合都扩展自Iterable特质。
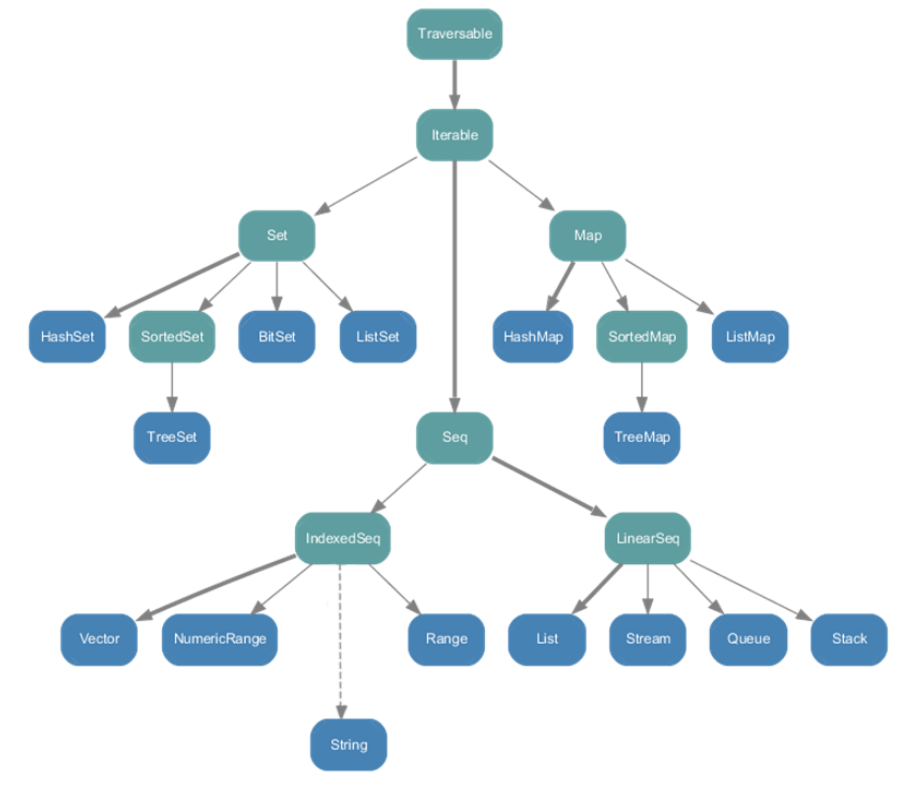
immutable不可变集合:
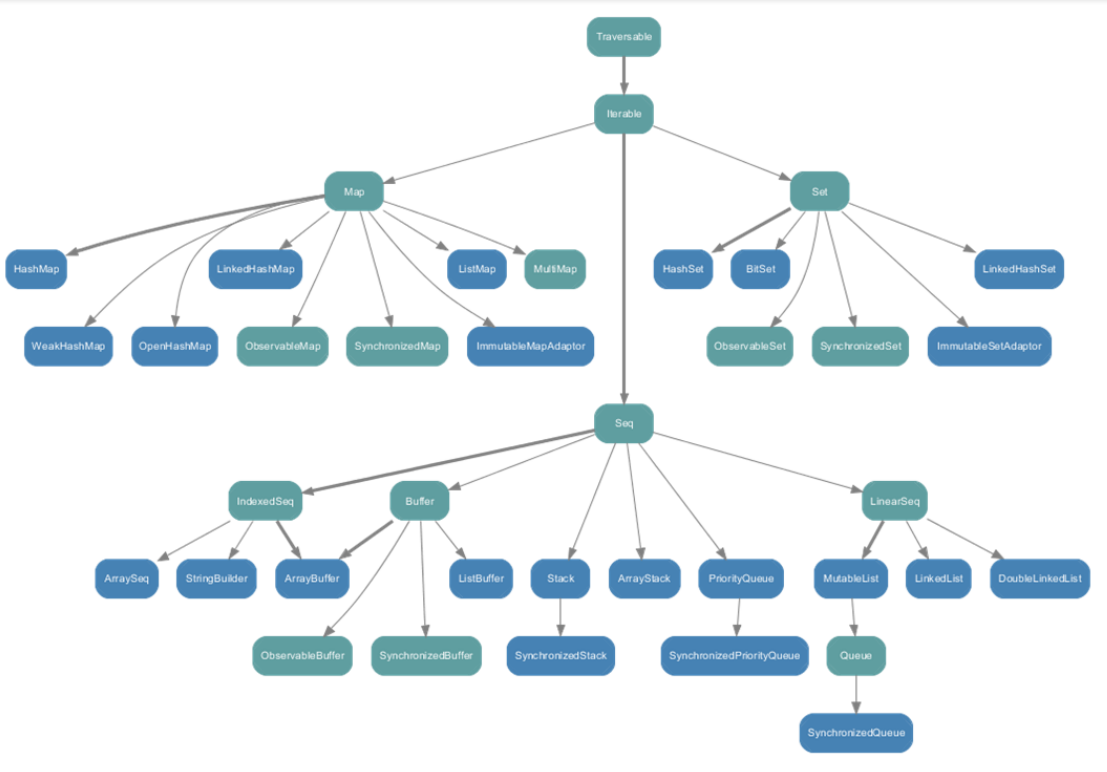
mutable可变集合:
小结:
String属于IndexedSeq;
Queue队列和Stack堆这两个经典的数据结构属于LinearSeq;
Map体系下有一个SortedMap,说明Scala中的Map是可以支持排序的;
mutable可变集合中Seq中的Buffer下有ListBuffer,它相当于可变的List列表;
List列表属于Seq中的LinearSeq;
Seq
Seq代表按照一定顺序排列的元素序列;
该序列是一种特别的可迭代集合,包含可重复的元素;
元素的顺序是确定的,每个元素对应一个索引值;
Seq提供了两个重要的子特质:
List
List代表元素顺序固定的不可变的链表,它是Seq的子类,在Scala编程中经常使用。
List是函数式编程语言中典型的数据结构,与数组类似,可索引、存放类型相同的元素。
List一旦被定义,其值就不能改变。
List列表有头部和尾部的概念,可以分别使用head和tail方法来获取:
这体现出列表具有递归的链表结构。
Scala定义了一个空列表对象Nil,定义为List[Nothing]
借助 Nil 可将多个元素用操作符 :: 添加到列表头部,常用来初始化列表;
操作符 ::: 用于拼接两个列表;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 package lagou.cn.part09object ListDemo def main Array [String ]): Unit = { val list1 = 1 :: 2 :: 3 :: 4 :: Nil val list2 = 5 :: 6 :: 7 :: 8 :: Nil val list3=list1:::list2 println(list3.head) println(list3.tail) println(list3.init) println(list3.last) val list4=List (4 ,2 ,6 ,1 ,7 ,9 ) println(quickSort(list4)) } def quickSort List [Int ]):List [Int ]={ list match { case Nil =>Nil case head::tail=> val (less,greater) =tail.partition(_<head) quickSort(less):::head::quickSort(greater) } } }
Queue
队列Queue是一个先进先出的结构。
队列是一个有序列表,在底层可以用数组或链表来实现。
先进先出的原则,就是先存入的数据,要先取出,后存入的数据后取出。
在Scala中,有scala.collection.mutable.Queue和scala.collection.immutable.Queue,一般来说,我们使用的是scala.collection.mutable.Queue
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 package lagou.cn.part09import scala.collection.mutableobject QueueDemo def main Array [String ]): Unit = { val queue1=new mutable.Queue [Int ]() println(queue1) queue1 +=1 queue1 ++=List (2 ,3 ,4 ) println(queue1) val dequeue=queue1.dequeue() println(dequeue) println(queue1) queue1.enqueue(5 ,6 ,7 ) println(queue1) println(queue1.head) println(queue1.last) } }
Set
Set(集合)是没有重复元素的对象集合,Set中的元素是唯一的;
Set分为可变的和不可变的集合;
默认情况下,使用的是不可变集合(引用 scala.collection.immutable.Set);
使用可变集合,需要引用 scala.collection.mutable.Set 包;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 package lagou.cn.part09object SetDemo def main Array [String ]): Unit = { val set = Set (1 , 2 , 3 , 4 , 5 , 6 ) set.drop(1 ) println(set) import scala.collection.mutable.Set val mutableSet = Set (3 , 4 , 5 ) mutableSet.add(7 ) println(mutableSet) mutableSet.remove(7 ) println(mutableSet) mutableSet += 8 mutableSet -= 3 println(mutableSet) println(Set (1 , 2 , 3 ) & Set (2 , 3 , 4 )) println(Set (1 , 2 , 3 ).intersect(Set (2 , 3 , 4 ))) println(Set (1 ,2 ,3 ) ++ Set (2 ,3 ,4 )) println(Set (1 ,2 ,3 ) | Set (2 ,3 ,4 )) println(Set (1 ,2 ,3 ).union(Set (2 ,3 ,4 ))) println(Set (1 ,2 ,3 ) -- Set (2 ,3 ,4 )) println(Set (1 ,2 ,3 ) &~ Set (2 ,3 ,4 )) println(Set (1 ,2 ,3 ).diff(Set (2 ,3 ,4 )) ) } }
Map
Map(映射)是一系列键值对的容器;Scala 提供了可变的和不可变的两种版本的Map,分别定义在包 scala.collection.mutable 和 scala.collection.immutable 里;
默认情况下,Scala中使用不可变的 Map;
如果要使用可变Map,必须导入scala.collection.mutable.Map; 在Map中,键的值是唯一的,可以根据键来对值进行快速的检索。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 package lagou.cn.part09import scala.collection.mutableobject MapDemo def main Array [String ]): Unit = { val map1 = Map ("a" -> 1 , "b" -> 2 ) val map2 = Map (("a" , 1 ), ("b" , 2 )) map1.keys.foreach(println(_)) map1.values.foreach(println(_)) val num: Option [Int ] = map1.get("c" ) num match { case None => println("None" ) case Some (x) => println(x) } val num2: Int = map1.getOrElse("d" , 0 ) println(num2) val map3 = scala.collection.mutable.Map ("a" -> 1 , "b" -> 2 ) println(map3) map3("a" ) = 10 println(map3) map3("c" ) = 3 println(map3) map3 += ("d" -> 4 , "f" -> 5 ) println(map3) map3 -= "d" println(map3) val kv: mutable.Map [Int , String ] = for ((k, v) <- map3) yield (v, k) println(kv) map3.map(x=>(x._2,x._1)).foreach(println(_)) val a=Array (1 ,2 ,3 ) val b=Array ("a" ,"b" ,"c" ) val c: Array [(Int , String )] = a.zip(b) val d: Map [Int , String ] = a.zip(b).toMap println(d) } }
集合常用算子
map、foreach & mapValues
集合对象都有 foreach、map 算子。
两个算子的共同点在于:都是用于遍历集合对象,并对每一项执行指定的方法;
两个算子的差异点在于:
foreach无返回值(准确说返回void),用于遍历集合
map返回集合对象,用于将一个集合转换成另一个集合
1 2 3 4 5 6 7 8 9 val numlist = (1 to 10 ).toListnumlist.foreach(elem=>print(elem+" " )) numlist.foreach(print _) numlist.foreach(print) numlist.map(_ > 2 ) numlist.map(_ * 2 )
操作 Map集合时,mapValues用于遍历value,是map操作的一种简化形式;
1 2 3 4 5 6 7 8 9 10 val map = Range (20 , 0 , -2 ).zipWithIndex.toMapmap.map(elem => (elem._1, elem._2 + 100 )) map.map{case (k,v) => (k, v+100 )} map.mapValues(_+100 )
flatten & flatMap
flatten的作用是把嵌套的结构展开,把结果放到一个集合中;
在 flatMap 中传入一个函数,该函数对每个输入都返回一个集合(而不是一个元素),最后把生成的多个集合“拍扁”成为一个集合;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 scala> val lst1 = List(List(1,2), List(3,4)) lst1: List[List[Int]] = List(List(1, 2), List(3, 4)) scala> lst1.flatten res5: List[Int] = List(1, 2, 3, 4) // flatten 把一个字符串的集合展开为一个字符集合,因为字符串本身就是字符的集合 scala> val lst4 = List("Java", "hadoop") lst4: List[String] = List(Java, hadoop) scala> lst4.flatten res8: List[Char] = List(J, a, v, a, h, a, d, o, o, p) // flatten 有效的处理 Some 和 None 组成的集合。它可以展开Some元素形成一个新的集合,同时去掉 None元素 scala> val x = Array(Some(1), None, Some(3), None) x: Array[Option[Int]] = Array(Some(1), None, Some(3), None) // 方法很多,flatten最简单 scala> x.flatten res9: Array[Int] = Array(1, 3) scala> x.collect{case Some(i) => i} res10: Array[Int] = Array(1, 3) scala> x.filter(!_.isEmpty).map(_.get) res11: Array[Int] = Array(1, 3)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 // 下面两条语句等价 val lst = List(List(1,2,5,6),List(3,4)) // 将 lst 中每个元素乘2,最后作为一个集合返回 // 此时 flatMap = flatten + map //List(1,2,5,6,3,4) lst.flatten.map(_*2) lst.flatMap((x: List[Int]) => x.map(_*2)) lst.flatMap(_.map(_*2)) // 将字符串数组按空格切分,转换为单词数组 val lines = Array("Apache Spark has an advanced DAG execution engine", "Spark offers over 80 high-level operators") // 下面两条语句效果等价 //map算子产生的结果:Array(Array(Apache, Spark, has, an, advanced, DAG, execution, engine), Array(Spark, offers, over, 80, high-level, operators)) // flatten算子产生的结果:Array(Apache, Spark, has, an, advanced, DAG, execution, engine, Spark, offers, over, 80, high-level, operators) lines.map(_.split(" ")).flatten // 此时 flatMap = map + flatten lines.flatMap(_.split(" "))
备注:flatMap = flatten + map 或 flatMap = map + flatten
collect
collect通过执行一个并行计算(偏函数),得到一个新的数组对象
1 2 3 4 5 6 7 8 9 10 11 12 13 object CollectDemo val fun: PartialFunction [Char , Char ] = { case 'a' => 'A ' case x => x } def main Array [String ]): Unit = { val chars = Array ('a', 'b', 'c') val newchars = chars.collect(fun) println("newchars:" + newchars.mkString("," )) } }
reduce
reduce可以对集合当中的元素进行归约操作;
还有 reduceLeft 和 reduceRight ,reduceLeft 从左向右归约,reduceRight 从右向左归约;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 val lst1 = (1 to 10).toList lst1.reduce(_+_) // 为什么这里能出现两个占位符? lst1.reduce(_+_) // 我们说过一个占位符代表一个参数,那么两个占位符就代表两个参数。根据这个思路改写等价的语句 // x类似于buffer,缓存每次操作的数据;y每次操作传递新的集合元素 lst1.reduce((x, y) => x + y) // 利用reduce操作,查找 lst1 中的最大值 lst1.reduce((x,y) => if (x>y) x else y) // reduceLeft、reduceRight lst1.reduceLeft((x,y) => if (x>y) x else y) lst1.reduceRight((x,y) => if (x>y) x else y)
sorted sortwith & sortby
Scala中对于集合的排序有三种方法:sorted、sortBy、sortWith
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 object SortDemo def main Array [String ]): Unit = { val list = List (1 , 9 , 3 , 8 , 5 , 6 ) val numSort: List [Int ] = list.sorted println(numSort) println(list.sortBy(x => x).reverse) print(list.sortWith(_ > _)) } }
与Java集合的转换
使用 scala.collection.JavaConverters 与Java集合交互。它有一系列的隐式转换,添加了asJava和asScala的转换方法。
1 2 3 4 5 import scala.collection.JavaConverters ._val list: Java .util.List [Int ] = List (1 ,2 ,3 ,4 ).asJavaval buffer: scala.collection.mutable.Buffer [Int ] = list.asScala

 wechat
wechat alipay
alipay