-- 这些参数也可以设置在hive-site.xml中 SET hive.support.concurrency = true; SET hive.exec.dynamic.partition.mode = nonstrict; SET hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager; -- Hive 0.x and 1.x only, 更高版本的hive是默认开启的 SET hive.enforce.bucketing = true;
-- 创建表用于更新。满足条件:内部表、ORC格式、分桶、设置表属性 create table zxz_data( name string, nid int, phone string, ntime date ) clustered by(nid) into 5 buckets stored as orc tblproperties('transactional'='true');
-- 创建临时表,用于向分桶表插入数据 create table temp1( name string, nid int, phone string, ntime date ) row format delimited fields terminated by ",";
-- 向临时表加载数据;向事务表中加载数据 load data local inpath '/home/hadoop/data/zxz_data.txt' overwrite into table temp1; insert into table zxz_data select * from temp1;
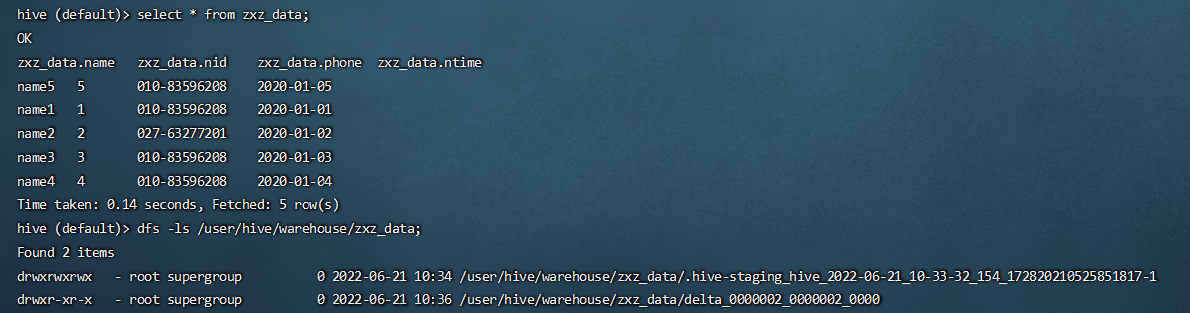
-- 检查数据和文件 select * from zxz_data; dfs -ls /user/hive/warehouse/mydb.db/zxz_data;
1 2 3
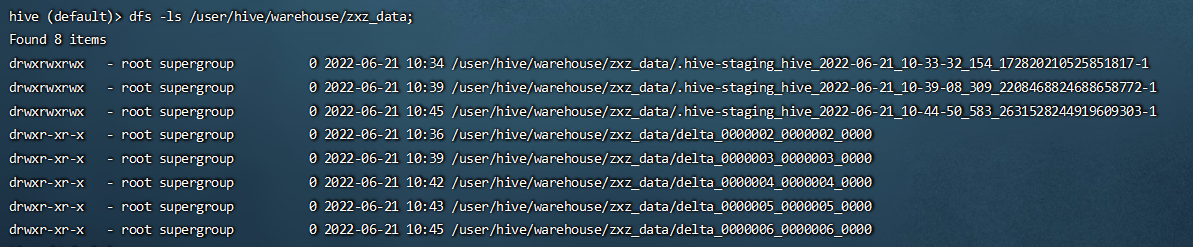
-- DML 操作 delete from zxz_data where nid = 3; dfs -ls /user/hive/warehouse/mydb.db/zxz_data;





 wechat
wechat alipay
alipay


