idea创建maven项目,添加scala项目框架,创建scala源文件夹,pom文件添加依赖
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 <dependencies > <dependency > <groupId > org.scala-lang</groupId > <artifactId > scala-library</artifactId > <version > ${scala.version}</version > </dependency > <dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-core_2.12</artifactId > <version > ${spark.version}</version > </dependency > </dependencies > <build > <pluginManagement > <plugins > <plugin > <groupId > net.alchim31.maven</groupId > <artifactId > scala-maven-plugin</artifactId > <version > 3.2.2</version > </plugin > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-compiler-plugin</artifactId > <version > 3.5.1</version > </plugin > </plugins > </pluginManagement > <plugins > <plugin > <groupId > net.alchim31.maven</groupId > <artifactId > scala-maven-plugin</artifactId > <executions > <execution > <id > scala-compile-first</id > <phase > process-resources</phase > <goals > <goal > add-source</goal > <goal > compile</goal > </goals > </execution > <execution > <id > scala-test-compile</id > <phase > process-test-resources</phase > <goals > <goal > testCompile</goal > </goals > </execution > </executions > </plugin > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-compiler-plugin</artifactId > <executions > <execution > <phase > compile</phase > <goals > <goal > compile</goal > </goals > </execution > </executions > </plugin > <plugin > <groupId > org.apache.maven.plugins</groupId > <artifactId > maven-shade-plugin</artifactId > <version > 2.4.3</version > <executions > <execution > <phase > package</phase > <goals > <goal > shade</goal > </goals > <configuration > <filters > <filter > <artifact > *:*</artifact > <excludes > <exclude > META-INF/*.SF</exclude > <exclude > META-INF/*.DSA</exclude > <exclude > META-INF/*.RSA</exclude > </excludes > </filter > </filters > </configuration > </execution > </executions > </plugin > </plugins > </build >
WordCount - scala
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 package cn.lagou.sparkcoreimport org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object ScalaWordCount def main Array [String ]): Unit = { val conf = new SparkConf ().setAppName("ScalaWordCount" ) val sc = new SparkContext (conf) sc.setLogLevel("WARN" ) val lines: RDD [String ] = sc.textFile(args(0 )) val words: RDD [String ] = lines.flatMap(line => line.split("\\s+" )) val wordsMap: RDD [(String , Int )] = words.map(x => (x, 1 )) val result: RDD [(String , Int )] = wordsMap.reduceByKey(_ + _) result.foreach(println) sc.stop() } }
备注:打包上传服务器运行,使用spark-submit提交集群运行
1 2 3 4 5 6 # 进入上传的jar的目录,执行spark-submit命令,最后文件为hdfs目录 # local方式执行 spark-submit --master local[*] --class cn.lagou.sparkcore.WordCount original-sparkcoreDemo-1.0-SNAPSHOT.jar /wcinput/* # yarn方式执行 spark-submit --master yarn --class cn.lagou.sparkcore.WordCount original-LagouBigData-1.0-SNAPSHOT.jar /wcinput/*
WordCount - java
Spark提供了:Scala、Java、Python、R语言的API;
对 Scala 和 Java 语言的支持最好;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import org.apache.spark.SparkConf;import org.apache.spark.api.java.JavaPairRDD;import org.apache.spark.api.java.JavaRDD;import org.apache.spark.api.java.JavaSparkContext;import scala.Tuple2;import java.util.Arrays;public class JavaWordCount { public static void main (String[] args) { SparkConf conf = new SparkConf ().setAppName("JavaWordCount" ).setMaster("local[*]" ); JavaSparkContext jsc = new JavaSparkContext (conf); jsc.setLogLevel("warn" ); JavaRDD<String> lines = jsc.textFile("file:///C:\\Project\\LagouBigData\\data\\wc.txt" ); JavaRDD<String> words = lines.flatMap(line -> Arrays.stream(line.split("\\s+" )).iterator()); JavaPairRDD<String, Integer> wordsMap = words.mapToPair(word -> new Tuple2 <>(word, 1 )); JavaPairRDD<String, Integer> results = wordsMap.reduceByKey((x, y) -> x + y); results.foreach(elem -> System.out.println(elem)); jsc.stop(); } }
备注:
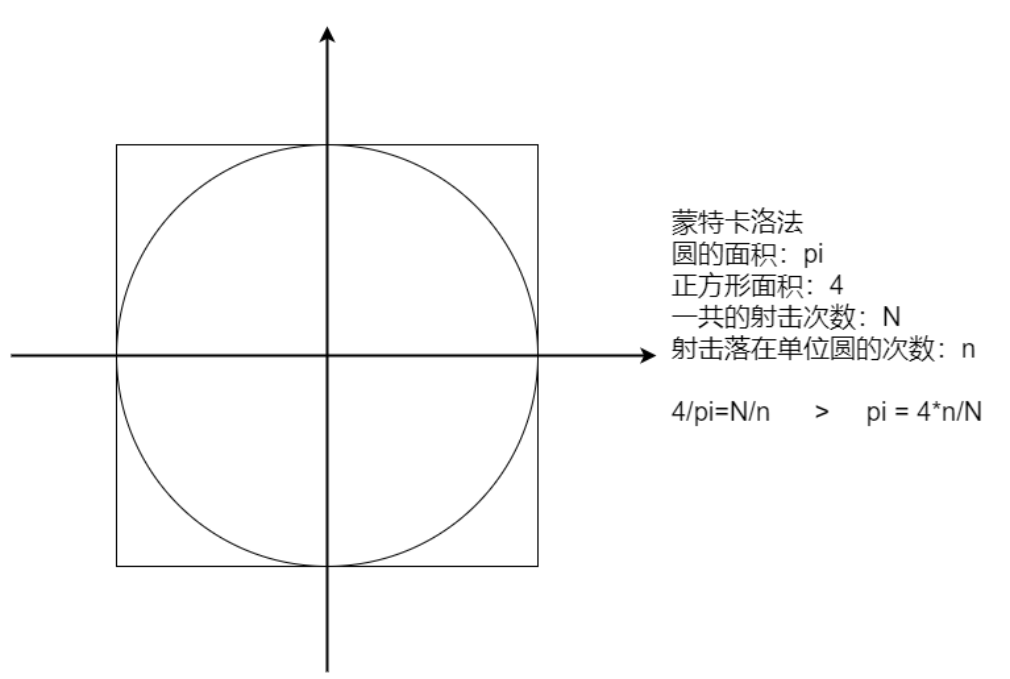
计算圆周率
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 package cn.lagou.sparkcoreimport org.apache.spark.{SparkConf , SparkContext }import scala.math.randomobject SparkPi def main Array [String ]): Unit = { val conf = new SparkConf ().setAppName(this .getClass.getCanonicalName).setMaster("local[*]" ) val sc = new SparkContext (conf) sc.setLogLevel("WARN" ) val slices = if (args.length > 0 ) args(0 ).toInt else 10 val N = 100000000 val count = sc.makeRDD(1 to N , slices).map(idx => { val (x, y) = (random, random) if (x*x + y*y <= 1 ) 1 else 0 }).reduce(_+_) println(s"Pi is roughly ${4.0 * count / N} " ) sc.stop() } }
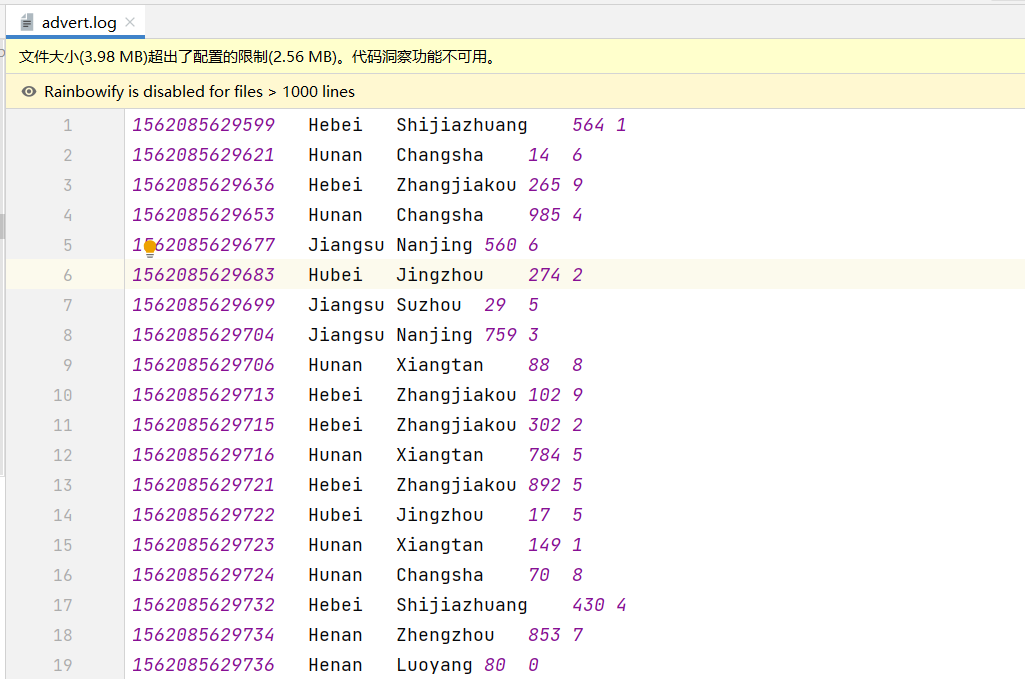
广告数据统计
数据格式:timestamp province city userid adid 时间点 省份 城市 用户 广告
需求: 1、统计每一个省份点击TOP3的广告ID 2、统计每一个省份每一个小时的TOP3广告ID
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 package cn.lagou.sparkcoreimport org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object AdStat def main Array [String ]): Unit = { val conf = new SparkConf ().setAppName(this .getClass.getCanonicalName).setMaster("local[*]" ) val sc = new SparkContext (conf) sc.setLogLevel("WARN" ) val N = 3 val lines: RDD [String ] = sc.textFile("file:///C:\\Users\\Administrator\\IdeaProjects\\sparkcoreDemo\\data\\advert.log" ) val rawRDD: RDD [(String , String , String )] = lines.map(line => { val arr: Array [String ] = line.split("\\s+" ) (arr(0 ), arr(1 ), arr(4 )) }) println("--------------------------------------------------------------" ) rawRDD.map { case (_, province, adid) => ((province, adid), 1 ) }.reduceByKey(_ + _).map { case ((province, adid), count) => (province, (adid, count)) }.groupByKey().mapValues(_.toList.sortWith(_._2 > _._2).take(N )).foreach(println) println("--------------------------------------------------------------" ) rawRDD.map { case (time, province, adid) => ((getHour(time), province, adid), 1 ) }.reduceByKey(_ + _).map { case ((hour, province, adid), count) => ((hour, province), (adid, count)) }.groupByKey().mapValues(_.toList.sortWith(_._2 > _._2).take(N )).foreach(println) sc.stop() } def getHour String ): String = { import org.joda.time.DateTime val datetime = new DateTime (timelong.toLong) datetime.getHourOfDay.toString } }
在Java 8出现前的很长时间内成为Java中日期时间处理的事实标准,用来弥补JDK的不足。
Joda 类具有不可变性,它们的实例无法被修改。(不可变类的一个优点就是它们是线程安全的)
在 Spark Core 程序中使用时间日期类型时,不要使用 Java 8 以前的时间日期类型,线程不安全。
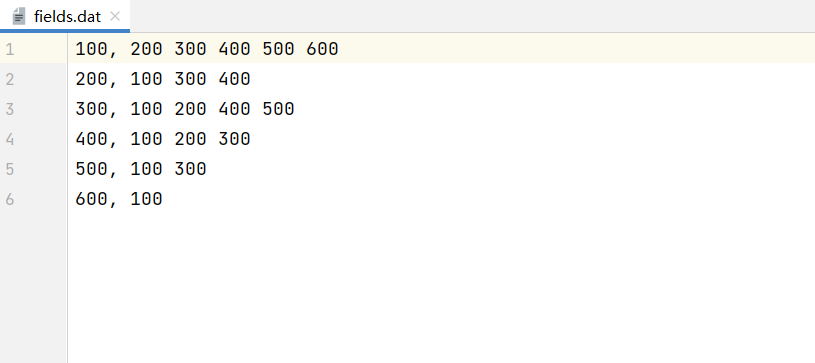
找共同好友
第一列表示用户,后面的表示该用户的好友
要求:1、查找两两用户的共同好友 2、最后的结果按前两个id号有序排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 package cn.lagou.sparkcoreimport org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object FindFriends def main Array [String ]): Unit = { val conf = new SparkConf ().setAppName(this .getClass.getCanonicalName.init).setMaster("local[*]" ) val sc = new SparkContext (conf) sc.setLogLevel("WARN" ) val lines: RDD [String ] = sc.textFile("file:///C:\\Users\\Administrator\\IdeaProjects\\sparkcoreDemo\\data\\fields.dat" ) val friendsRDD: RDD [(String , Array [String ])] = lines.map { line => val fields: Array [String ] = line.split("," ) val userId = fields(0 ).trim val friends: Array [String ] = fields(1 ).trim.split("\\s+" ) (userId, friends) } println("*****************************************************************" ) friendsRDD.cartesian(friendsRDD) .filter { case ((id1, _), (id2, _)) => id1 < id2 } .map{case ((id1, friends1), (id2, friends2)) => ((id1, id2), friends1.intersect(friends2).sorted.toBuffer) }.sortByKey() .collect().foreach(println) println("*****************************************************************" ) friendsRDD.flatMapValues(friends => friends.combinations(2 )) .map{case (k, v) => (v.mkString(" & " ), Set (k))} .reduceByKey(_ | _) .sortByKey() .collect().foreach(println) sc.stop() } }
Super WordCount
要求:将单词全部转换为小写,去除标点符号(难),去除停用词(难);最后按照 count 值降序保存到文件,同时将全部结果保存到MySQL(难);标点符号和停用词可以自定义。
停用词:语言中包含很多功能词。与其他词相比,功能词没有什么实际含义。最普遍的功能词是[限定词](the、a、an、that、those),介词(on、in、to、from、over等)、代词、数量词等。
Array[(String, Int)] => scala jdbc => MySQL
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 package cn.lagou.sparkcoreimport org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object SuperWordCount1 private val stopWords = "in on to from by a an the is are were was i we you your he his some any of as can it each" .split("\\s+" ) private val punctuation = "[\\)\\.,:;'!\\?]" def main Array [String ]): Unit = { val conf = new SparkConf ().setAppName(this .getClass.getCanonicalName.init).setMaster("local[*]" ) val sc = new SparkContext (conf) sc.setLogLevel("WARN" ) val lines: RDD [String ] = sc.textFile("file:///C:\\Users\\Administrator\\IdeaProjects\\sparkcoreDemo\\data\\swc.dat" ) lines.flatMap(_.split("\\s+" )) .map(_.toLowerCase) .map(_.replaceAll(punctuation, "" )) .filter(word => !stopWords.contains(word) && word.trim.length>0 ) .map((_, 1 )) .reduceByKey(_+_) .sortBy(_._2, false ) .collect.foreach(println) sc.stop() } }
引入依赖
1 2 3 4 5 <dependency > <groupId > mysql</groupId > <artifactId > mysql-connector-java</artifactId > <version > 5.1.44</version > </dependency >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 package cn.lagou.sparkcoreimport java.sql.{Connection , DriverManager , PreparedStatement }object JDBCDemo def main Array [String ]): Unit = { val str = "hadoop spark java scala hbase hive sqoop hue tez atlas datax grinffin zk kafka" val result: Array [(String , Int )] = str.split("\\s+" ).zipWithIndex val url = "jdbc:mysql://linux123:3306/ebiz?useUnicode=true&characterEncoding=utf-8&useSSL=false" val username = "hive" val password = "12345678" var conn: Connection = null var stmt: PreparedStatement = null val sql = "insert into wordcount values (?, ?)" try { conn = DriverManager .getConnection(url, username, password) stmt = conn.prepareStatement(sql) result.foreach{case (k, v) => stmt.setString(1 , k) stmt.setInt(2 , v) stmt.executeUpdate() } }catch { case e: Exception => e.printStackTrace() } finally { if (stmt != null ) stmt.close() if (conn != null ) conn.close() } } }
MySQL数据库建表
1 create table wordcount(word varchar(30), count int);
未优化的程序:使用 foreach 保存数据,要创建大量的链接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 package cn.lagou.sparkcoreimport java.sql.{Connection , DriverManager , PreparedStatement }import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object SuperWordCount2 private val stopWords = "in on to from by a an the is are were was i we you your he his some any of as can it each" .split("\\s+" ) private val punctuation = "[\\)\\.,:;'!\\?]" private val url = "jdbc:mysql://linux123:3306/ebiz?useUnicode=true&characterEncoding=utf-8&useSSL=false" private val username = "hive" private val password = "12345678" def main Array [String ]): Unit = { val conf = new SparkConf ().setAppName(this .getClass.getCanonicalName.init).setMaster("local[*]" ) val sc = new SparkContext (conf) sc.setLogLevel("WARN" ) val lines: RDD [String ] = sc.textFile("file:///C:\\Project\\LagouBigData\\data\\swc.dat" ) val resultRDD: RDD [(String , Int )] = lines.flatMap(_.split("\\s+" )) .map(_.toLowerCase) .map(_.replaceAll(punctuation, "" )) .filter(word => !stopWords.contains(word) && word.trim.length > 0 ) .map((_, 1 )) .reduceByKey(_ + _) .sortBy(_._2, false ) resultRDD.saveAsTextFile("file:///C:\\Project\\LagouBigData\\data\\superwc" ) resultRDD.foreach{case (k, v) => var conn: Connection = null var stmt: PreparedStatement = null val sql = "insert into wordcount values (?, ?)" try { conn = DriverManager .getConnection(url, username, password) stmt = conn.prepareStatement(sql) stmt.setString(1 , k) stmt.setInt(2 , v) stmt.executeUpdate() }catch { case e: Exception => e.printStackTrace() } finally { if (stmt != null ) stmt.close() if (conn != null ) conn.close() } } sc.stop() } }
优化后的程序:使用 foreachPartition 保存数据,一个分区创建一个链接;cache RDD
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 package cn.lagou.sparkcoreimport java.sql.{Connection , DriverManager , PreparedStatement }import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object SuperWordCount3 private val stopWords: Array [String ] = "in on to from by a an the is are were was i we you your he his some any of as can it each" .split("\\s+" ) private val punctuation = "[\\)\\.,:;'!\\?]" private val url = "jdbc:mysql://linux123:3306/ebiz?useUnicode=true&characterEncoding=utf-8&useSSL=false" private val username = "hive" private val password = "12345678" def main Array [String ]): Unit = { val conf = new SparkConf ().setAppName(this .getClass.getCanonicalName.init).setMaster("local[*]" ) val sc = new SparkContext (conf) sc.setLogLevel("WARN" ) val lines: RDD [String ] = sc.textFile("file:///C:\\Project\\LagouBigData\\data\\swc.dat" ) val resultRDD: RDD [(String , Int )] = lines.flatMap(_.split("\\s+" )) .map(_.toLowerCase) .map(_.replaceAll(punctuation, "" )) .filter(word => !stopWords.contains(word) && word.trim.length > 0 ) .map((_, 1 )) .reduceByKey(_ + _) .sortBy(_._2, false ) resultRDD.cache() resultRDD.saveAsTextFile("file:///C:\\Project\\LagouBigData\\data\\superwc" ) resultRDD.foreachPartition { iter => saveAsMySQL(iter)} sc.stop() } def saveAsMySQL Iterator [(String , Int )]): Unit = { var conn: Connection = null var stmt: PreparedStatement = null val sql = "insert into wordcount values (?, ?)" try { conn = DriverManager .getConnection(url, username, password) stmt = conn.prepareStatement(sql) iter.foreach { case (k, v) => stmt.setString(1 , k) stmt.setInt(2 , v) stmt.executeUpdate() } } catch { case e: Exception => e.printStackTrace() } finally { if (stmt != null ) stmt.close() if (conn != null ) conn.close() } } }


 wechat
wechat alipay
alipay



