UDF & UDAF
UDF
UDF(User Defined Function),自定义函数。函数的输入、输出都是一条数据记录,类似于Spark SQL中普通的数学或字符串函数。实现上看就是普通的Scala函数;
用Scala编写的UDF与普通的Scala函数几乎没有任何区别,唯一需要多执行的一个步骤是要在SQLContext注册它。
1 2 3 def len(bookTitle: String):Int = bookTitle.length spark.udf.register("len", len _) val booksWithLongTitle = spark.sql("select title, author from books where len(title) > 10")
编写的UDF可以放到SQL语句的fields部分,也可以作为where、groupBy或者having子句的一部分。
也可以在使用UDF时,传入常量而非表的列名。稍稍修改一下前面的函数,让长度10作为函数的参数传入:
1 2 3 def lengthLongerThan(bookTitle: String, length: Int): Boolean = bookTitle.length > length spark.udf.register("longLength", lengthLongerThan _) val booksWithLongTitle = spark.sql("select title, author from books where longLength(title, 10)")
若使用DataFrame的API,则以字符串的形式将UDF传入:
1 val booksWithLongTitle = dataFrame.filter("longLength(title, 10)")
DataFrame的API也可以接收Column对象,可以用符号来包裹一个字符串表示一个 C o l u m n 。 符号来包裹一个字符串表示一个Column。 符号来包裹一个字符串表示一个 C o l u mn 。
1 2 3 4 5 6 7 import org.apache.spark.sql.functions._ val longLength = udf((bookTitle: String, length: Int) => bookTitle.length > length) import spark.implicits._ val booksWithLongTitle = dataFrame.filter(longLength($"title", lit(10)))
完整示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 package cn.lagou.sparksqlimport org.apache.spark.sql.expressions.UserDefinedFunction import org.apache.spark.sql.{Row , SparkSession }object UDF def main Array [String ]): Unit = { val spark = SparkSession .builder() .appName(this .getClass.getCanonicalName) .master("local[*]" ) .getOrCreate() spark.sparkContext.setLogLevel("WARN" ) import spark.implicits._ import spark.sql val data = List (("scala" , "author1" ), ("spark" , "author2" ), ("hadoop" , "author3" ), ("hive" , "author4" ), ("strom" , "author5" ), ("kafka" , "author6" )) val df = data.toDF("title" , "author" ) df.createTempView("books" ) def len1 String ): Int = str.length spark.udf.register("len1" , len1 _) import org.apache.spark.sql.functions._ val len2: UserDefinedFunction = udf(len1 _) df.select($"title" , $"author" , len2($"title" )).show df.filter(len2($"title" )>5 ).show df.map{case Row (title: String , author: String ) => (title, author, title.length)}.show spark.stop() } }
UDAF
UDAF(User Defined Aggregation Funcation),用户自定义聚合函数。函数本身作用于数据集合,能够在聚合操作的基础上进行自定义操作(多条数据输入,一条数据输出);类似于在group by之后使用的sum、avg等函数;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 数据如下: id, name, sales, discount, state, saleDate 1, "Widget Co", 1000.00, 0.00, "AZ", "2019-01- 01" 2, "Acme Widgets", 2000.00, 500.00, "CA", "2019-02- 01" 3, "Widgetry", 1000.00, 200.00, "CA", "2020-01- 11" 4, "Widgets R Us", 2000.00, 0.0, "CA", "2020-02- 19" 5, "Ye Olde Widgete", 3000.00, 0.0, "MA", "2020-02- 28" 最后要得到的结果为: (2020年的合计值 – 2019年的合计值) / 2019年的合计值 (6000 - 3000) / 3000 = 1 执行以下SQL得到最终的结果: select userFunc(sales, saleDate) from table1; 即计算逻辑在userFunc中实现
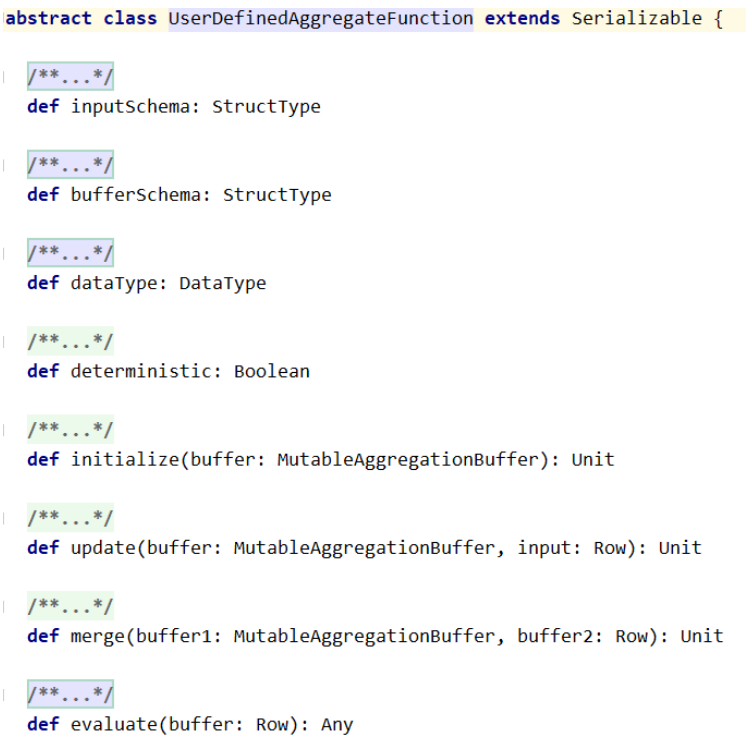
普通的UDF不支持数据的聚合运算。如当要对销售数据执行年度同比计算,就需要对当年和上一年的销量分别求和,然后再利用公式进行计算。此时需要使用UDAF,Spark为所有的UDAF定义了一个父类 UserDefinedAggregateFunction 。要继承这个类,需要实现父类的几个抽象方法:
inputSchema用于定义与DataFrame列有关的输入样式
bufferSchema用于定义存储聚合运算时产生的中间数据结果的Schema
dataType标明了UDAF函数的返回值类型
deterministic是一个布尔值,用以标记针对给定的一组输入,UDAF是否总是生成相同的结果
initialize对聚合运算中间结果的初始化
update函数的第一个参数为bufferSchema中两个Field的索引,默认以0开始
UDAF的核心计算都发生在update函数中;update函数的第二个参数input
Row对应的并非DataFrame的行,而是被inputSchema投影了的行
merge函数负责合并两个聚合运算的buffer,再将其存储到MutableAggregationBuffer中
evaluate函数完成对聚合Buffer值的运算,得到最终的结果
UDAF-类型不安全
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 package cn.lagou.sparksqlimport org.apache.log4j.{Level , Logger }import org.apache.spark.sql.expressions.{MutableAggregationBuffer , UserDefinedAggregateFunction }import org.apache.spark.sql.types.{DataType , DoubleType , StringType , StructType }import org.apache.spark.sql.{Row , SparkSession }class TypeUnsafeUDAF extends UserDefinedAggregateFunction override def inputSchema StructType = new StructType ().add("sales" , DoubleType ).add("saleDate" , StringType ) override def bufferSchema StructType = new StructType ().add("year2019" , DoubleType ).add("year2020" , DoubleType ) override def dataType DataType = DoubleType override def deterministic Boolean = true override def initialize MutableAggregationBuffer ): Unit = { buffer.update(0 , 0.0 ) buffer.update(1 , 0.0 ) } override def update MutableAggregationBuffer , input: Row ): Unit = { val sales = input.getAs[Double ](0 ) val saleYear = input.getAs[String ](1 ).take(4 ) saleYear match { case "2019" => buffer(0 ) = buffer.getAs[Double ](0 ) + sales case "2020" => buffer(1 ) = buffer.getAs[Double ](1 ) + sales case _ => println("Error!" ) } } override def merge MutableAggregationBuffer , buffer2: Row ): Unit = { buffer1(0 ) = buffer1.getAs[Double ](0 ) + buffer2.getAs[Double ](0 ) buffer1(1 ) = buffer1.getAs[Double ](1 ) + buffer2.getAs[Double ](1 ) } override def evaluate Row ): Double = { if (math.abs(buffer.getAs[Double ](0 )) < 0.000000001 ) 0.0 else (buffer.getAs[Double ](1 ) - buffer.getAs[Double ](0 )) / buffer.getAs[Double ](0 ) } } object TypeUnsafeUDAFTest def main Array [String ]): Unit = { Logger .getLogger("org" ).setLevel(Level .WARN ) val spark = SparkSession .builder() .appName(s"${this.getClass.getCanonicalName} " ) .master("local[*]" ) .getOrCreate() val sales = Seq ( (1 , "Widget Co" , 1000.00 , 0.00 , "AZ" , "2019-01-02" ), (2 , "Acme Widgets" , 1000.00 , 500.00 , "CA" , "2019-02-01" ), (3 , "Widgetry" , 1000.00 , 200.00 , "CA" , "2020-01-11" ), (4 , "Widgets R Us" , 2000.00 , 0.0 , "CA" , "2020-02-19" ), (5 , "Ye Olde Widgete" , 3000.00 , 0.0 , "MA" , "2020-02-28" )) val salesDF = spark.createDataFrame(sales).toDF("id" , "name" , "sales" , "discount" , "state" , "saleDate" ) salesDF.createTempView("sales" ) val userFunc = new TypeUnsafeUDAF spark.udf.register("userFunc" , userFunc) spark.sql("select userFunc(sales, saleDate) as rate from sales" ).show() spark.stop() } }
UDAF-类型安全
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 package cn.lagou.sparksqlimport org.apache.log4j.{Level , Logger }import org.apache.spark.sql.expressions.Aggregator import org.apache.spark.sql.{Encoder , Encoders , SparkSession , TypedColumn }case class Sales (id: Int , name1: String , sales: Double , discount: Double , name2: String , stime: String )case class SalesBuffer (var sales2019: Double , var sales2020: Double )class TypeSafeUDAF extends Aggregator [Sales , SalesBuffer , Double ] override def zero SalesBuffer = SalesBuffer (0.0 , 0.0 ) override def reduce SalesBuffer , input: Sales ): SalesBuffer = { val sales: Double = input.sales val year = input.stime.take(4 ) year match { case "2019" => buffer.sales2019 += sales case "2020" => buffer.sales2020 += sales case _ => println("ERROR" ) } buffer } override def merge SalesBuffer , b2: SalesBuffer ): SalesBuffer = { SalesBuffer (b1.sales2019 + b2.sales2019, b1.sales2020 + b2.sales2020) } override def finish SalesBuffer ): Double = { if (math.abs(reduction.sales2019) < 0.0000000001 ) 0.0 else (reduction.sales2020 - reduction.sales2019) / reduction.sales2019 } override def bufferEncoder Encoder [SalesBuffer ] = Encoders .product override def outputEncoder Encoder [Double ] = Encoders .scalaDouble } object TypeSafeUDAFTest def main Array [String ]): Unit = { Logger .getLogger("org" ).setLevel(Level .WARN ) val spark = SparkSession .builder() .appName(s"${this.getClass.getCanonicalName} " ) .master("local[*]" ) .getOrCreate() val sales = Seq ( Sales (1 , "Widget Co" , 1000.00 , 0.00 , "AZ" , "2019-01-02" ), Sales (2 , "Acme Widgets" , 2000.00 , 500.00 , "CA" , "2019-02-01" ), Sales (3 , "Widgetry" , 1000.00 , 200.00 , "CA" , "2020-01-11" ), Sales (4 , "Widgets R Us" , 2000.00 , 0.0 , "CA" , "2020-02-19" ), Sales (5 , "Ye Olde Widgete" , 3000.00 , 0.0 , "MA" , "2020-02-28" )) import spark.implicits._ val ds = spark.createDataset(sales) ds.show val rate: TypedColumn [Sales , Double ] = new TypeSafeUDAF ().toColumn.name("rate" ) ds.select(rate).show spark.stop() } }
访问Hive
在 pom 文件中增加依赖:
1 2 3 4 5 <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.12</artifactId> <version>${spark.version}</version> </dependency>
在 resources中增加hive-site.xml文件,在文件中增加内容:
1 2 3 4 5 6 <configuration> <property> <name>hive.metastore.uris</name> <value>thrift://linux123:9083</value> </property> </configuration>
备注:最好使用 metastore service 连接Hive;使用直连 metastore 的方式时,SparkSQL程序会修改 Hive 的版本信息;
默认Spark使用 Hive 1.2.1进行编译,包含对应的serde, udf, udaf等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 package cn.lagou.sparksqlimport org.apache.spark.sql.{DataFrame , SaveMode , SparkSession }object AccessHive def main Array [String ]): Unit = { val spark = SparkSession .builder() .appName("Demo1" ) .master("local[*]" ) .enableHiveSupport() .config("spark.sql.parquet.writeLegacyFormat" , "true" ) .getOrCreate() val sc = spark.sparkContext sc.setLogLevel("warn" ) spark.table("ods.ods_trade_product_info_backup" ).show spark.close() } }


 wechat
wechat alipay
alipay


