
Hive数据存储文件格式
Hive支持的存储数的格式主要有:TEXTFILE(默认格式) 、SEQUENCEFILE、RCFILE、ORCFILE、PARQUET。
textfile为默认格式,建表时没有指定文件格式,则使用TEXTFILE,导入数据时会直接把数据文件拷贝到hdfs上不进行处理;
sequencefile,rcfile,orcfile格式的表不能直接从本地文件导入数据,数据要先导入到textfile格式的表中, 然后再从表中用insert导入sequencefile、rcfile、orcfile表中
行存储与列存储
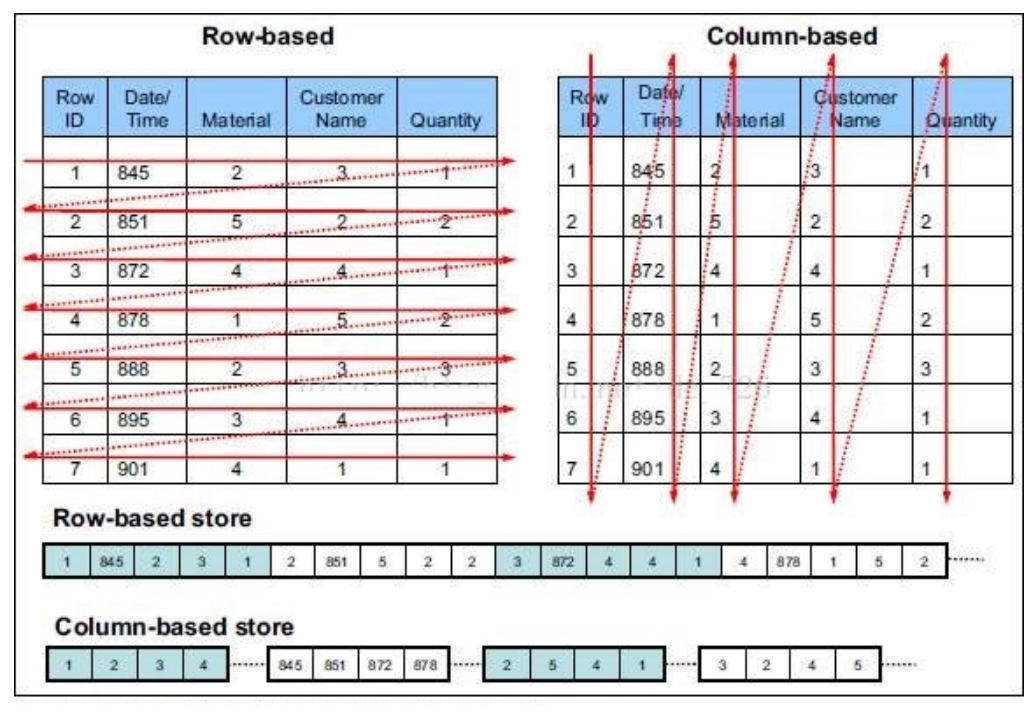
行式存储下一张表的数据都是放在一起的,但列式存储下数据被分开保存了。
行存储
优点:数据被保存在一起,insert和update更加容易
缺点:选择(selection)时即使只涉及某几列,所有数据也都会被读取
列存储
优点:查询时只有涉及到的列会被读取,效率高
缺点:选中的列要重新组装,insert/update比较麻烦
TEXTFILE、SEQUENCEFILE 的存储格式是基于行存储的;
ORC和PARQUET 是基于列式存储的。
TextFile
Hive默认的数据存储格式,数据不做压缩,磁盘开销大,数据解析开销大。 可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,从而无法对数据进行并行操作。
1 | create table if not exists uaction_text( |
SEQUENCEFILE
SequenceFile是Hadoop API提供的一种二进制文件格式,其具有使用方便、可分割、可压缩的特点。 SequenceFile支持三种压缩选择:none,record,block。Record压缩率低,一般建议使用BLOCK压缩。
RCFile
RCFile全称Record Columnar File,列式记录文件,是一种类似于SequenceFile的键值对数据文件。RCFile结合列存储和行存储的优缺点,是基于行列混合存储的RCFile。
RCFile遵循的“先水平划分,再垂直划分”的设计理念。先将数据按行水平划分为行组,这样一行的数据就可以保证存储在同一个集群节点;然后在对行进行垂直划分。
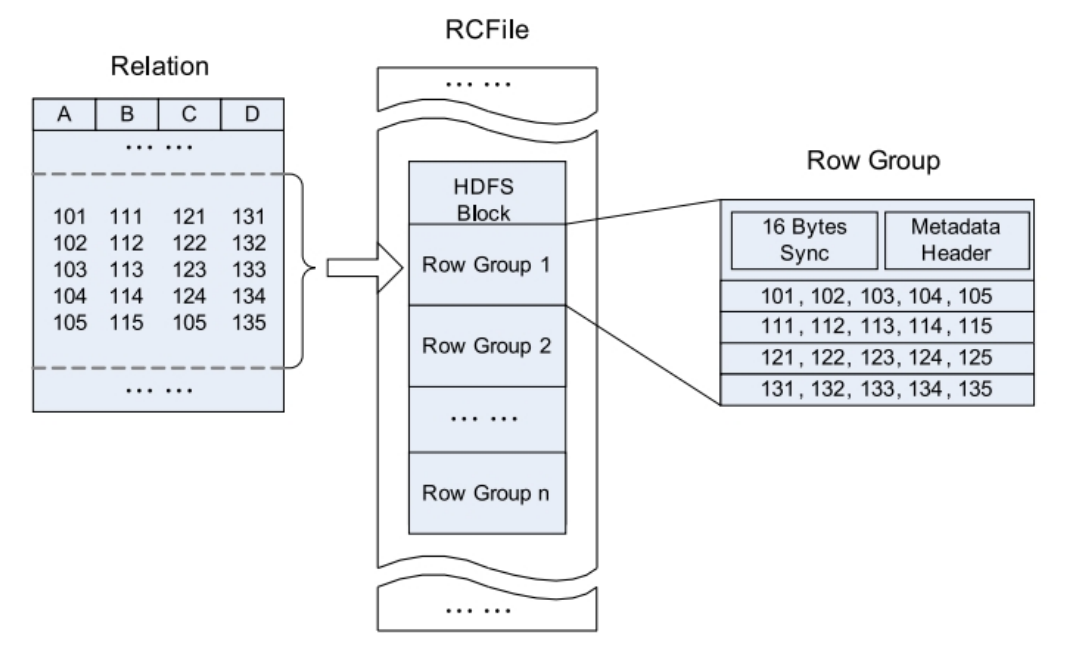
一张表可以包含多个HDFS block
在每个block中,RCFile以行组为单位存储其中的数据
row group又由三个部分组成用于在block中分隔两个row group的16字节的标志区
存储row group元数据信息的header
实际数据区,表中的实际数据以列为单位进行存储
ORCFile
ORC File,它的全名是Optimized Row Columnar (ORC) file,其实就是对RCFile做了一些优化,在hive 0.11中引入的存储格式。这种文件格式可以提供一种高效的方法来存储Hive数据。它的设计目标是来克服Hive其他格式的缺陷。运用ORC File可以提高Hive的读、写以及处理数据的性能。
ORC文件结构由三部分组成:
文件脚注(file footer):包含了文件中 stripe 的列表,每个stripe行数,以及每个列的数据类型。还包括每个列的最大、最小值、行计数、求和等信息
postscript:压缩参数和压缩大小相关信息
条带(stripe):ORC文件存储数据的地方。在默认情况下,一个stripe的大小为250MBIndex Data:一个轻量级的index,默认是每隔1W行做一个索引。包括该条带的一些统计信息,以及数据在stripe中的位置索引信息
Rows Data:存放实际的数据。先取部分行,然后对这些行按列进行存储。对每个列进行了编码,分成多个stream来存储
Stripe Footer:存放stripe的元数据信息
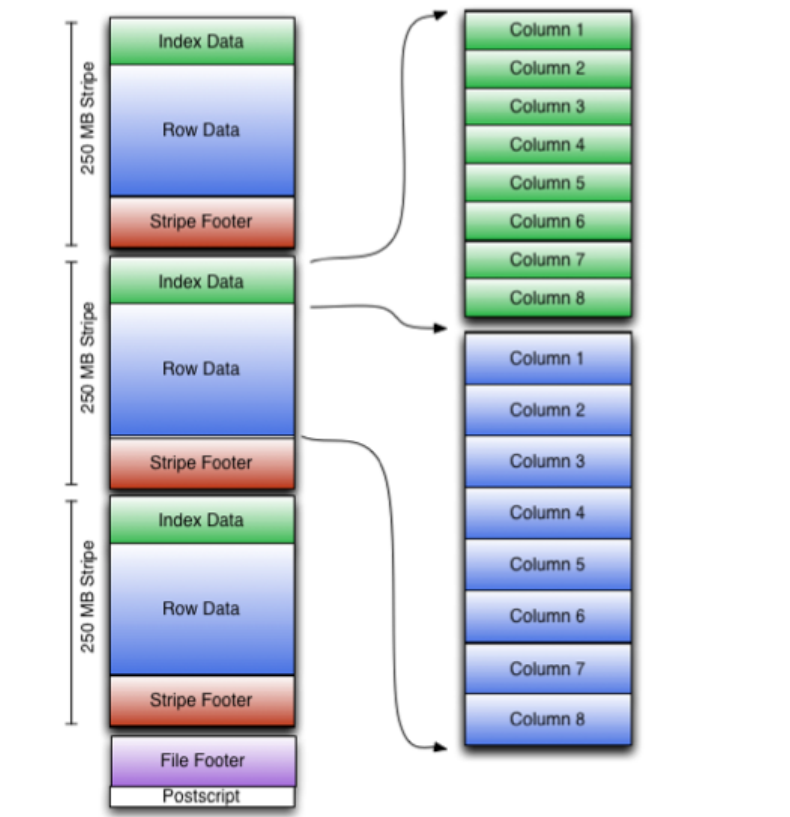
ORC在每个文件中提供了3个级别的索引:文件级、条带级、行组级。借助ORC提供的索引信息能加快数据查找和读取效率,规避大部分不满足条件的查询条件的文件和数据块。使用ORC可以避免磁盘和网络IO的浪费,提升程序效率,提升整个集群的工作负载。
1 | create table if not exists uaction_orc( |
Parquet
Apache Parquet是Hadoop生态圈中一种新型列式存储格式,它可以兼容Hadoop生态圈中大多数计算框架(Mapreduce、Spark等),被多种查询引擎支持(Hive、Impala、Drill等),与语言和平台无关的。
Parquet文件是以二进制方式存储的,不能直接读取的,文件中包括实际数据和元数据,Parquet格式文件是自解析的。
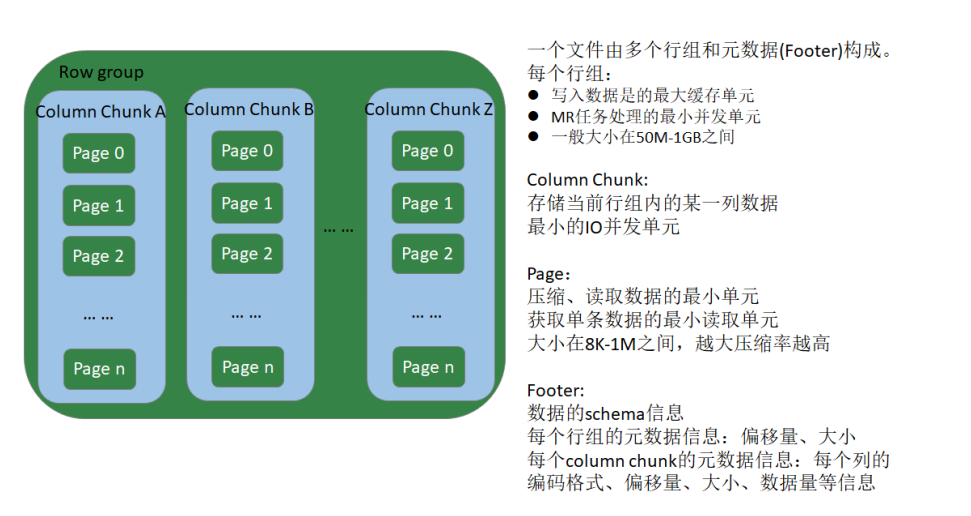
Row group:
-
写入数据时的最大缓存单元
-
MR任务的最小并发单元
-
一般大小在50MB-1GB之间
Column chunk:
-
存储当前Row group内的某一列数据
-
最小的IO并发单元
Page:
-
压缩、读数据的最小单元
-
获得单条数据时最小的读取数据单元
-
大小一般在8KB-1MB之间,越大压缩效率越高
Footer:
-
数据Schema信息
-
每个Row group的元信息:偏移量、大小
-
每个Column chunk的元信息:每个列的编码格式、首页偏移量、首索引页偏移量、个数、大小等信息
1 | create table if not exists uaction_parquet( |
文件存储格式对比测试
-
给 linux123 分配合适的资源。2core;2048M内存
-
适当减小文件的数据量(现有数据约800W,根据自己的实际选择处理100-300W条数据均可)
1 | # 检查文件行数 |
文件压缩比
1 | hive (mydb)> dfs -ls /user/hive/warehouse/mydb.db/ua*; |
ORC > Parquet > text
执行查询时间比
1 | SELECT COUNT(*) FROM uaction_text; |
orc 与 parquet类似 > txt
小结
在生产环境中,Hive表的数据格式使用最多的有三种:TextFile、ORCFile、Parquet。
-
TextFile文件更多的是作为跳板来使用(即方便将数据转为其他格式)
-
有update、delete和事务性操作的需求,通常选择ORCFile
-
没有事务性要求,希望支持Impala、Spark,建议选择Parquet
 wechat
wechat alipay
alipay




