
RDD编程之序列化与依赖关系
序列化
在实际开发中会自定义一些对RDD的操作,此时需要注意的是:
-
初始化工作是在Driver端进行的
-
实际运行程序是在Executor端进行的
这就涉及到了进程通信,是需要序列化的。
可以简单的认为SparkContext代表Driver。
1 | package cn.lagou.sparkcore |
备注:
-
如果在方法、函数的定义中引用了不可序列化的对象,也会导致任务不能序列化
-
延迟创建的解决方案较为简单,适用性广
RDD依赖关系
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。
RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,可根据这些信息来重新运算和恢复丢失的数据分区。
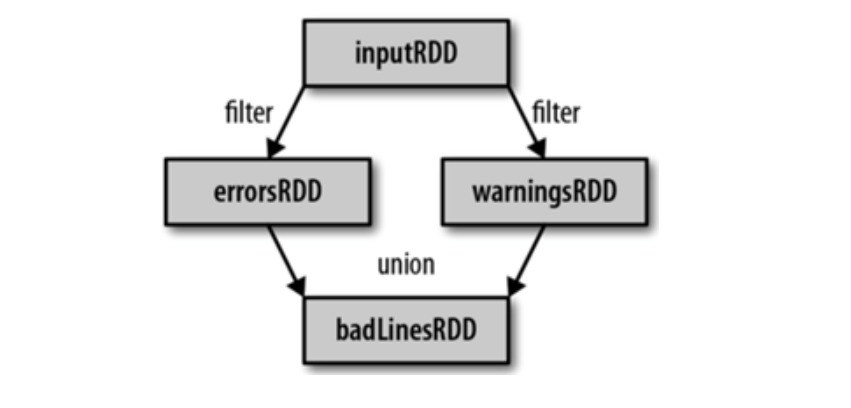
RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。 依赖有2个作用:其一用来解决数 据容错;其二用来划分stage。
窄依赖:1:1 或 n:1
宽依赖:n:m;意味着有 shuffle
要能够准确、迅速的区分哪些算子是宽依赖;
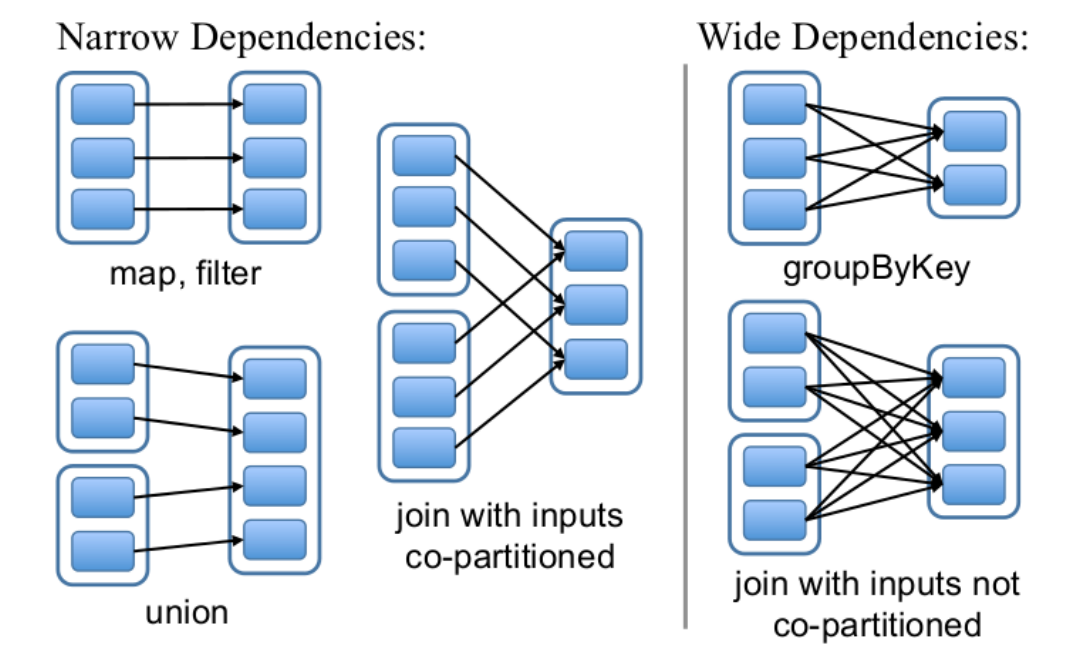
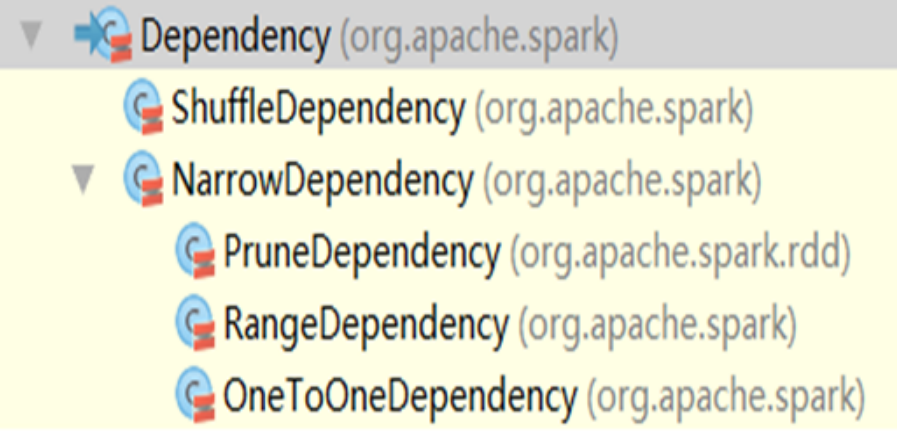
DAG(Directed Acyclic Graph) 有向无环图。原始的RDD通过一系列的转换就就形成了DAG,根据RDD之间的依赖关系的不同将DAG划分成不同的Stage:
-
对于窄依赖,partition的转换处理在Stage中完成计算
-
对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算
-
宽依赖是划分Stage的依据
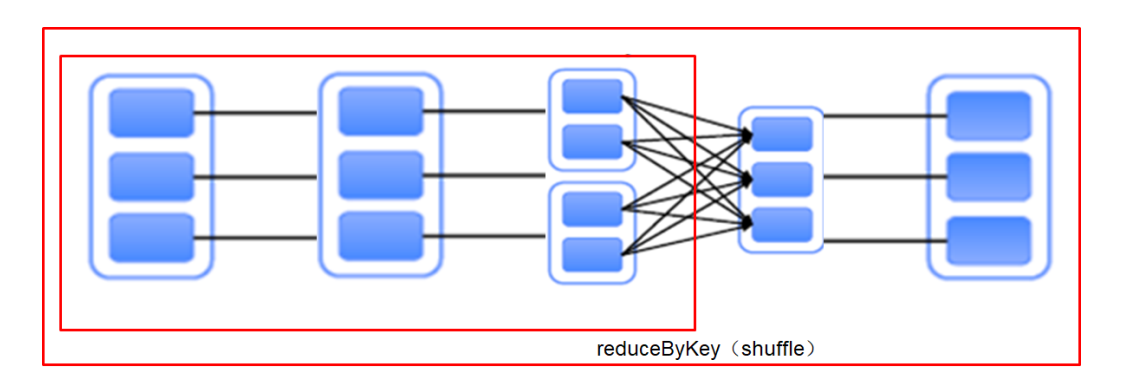
RDD任务切分中间分为:Driver programe、Job、Stage(TaskSet)和Task
-
Driver program:初始化一个SparkContext即生成一个Spark应用
-
Job:一个Action算子就会生成一个Job
-
Stage:根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage
-
Task:Stage是一个TaskSet,将Stage划分的结果发送到不同的Executor执行即为一个Task
-
Task是Spark中任务调度的最小单位;每个Stage包含许多Task,这些Task执行的计算逻辑相同的,计算的数据是不同的
注意:Driver programe->Job->Stage-> Task每一层都是1对n的关系。
1 | // 窄依赖 |
-
再谈WordCount
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59scala> val rdd1 = sc.textFile("/wcinput/wc.txt")
rdd1: org.apache.spark.rdd.RDD[String] = /wcinput/wc.txt MapPartitionsRDD[11] at textFile at <console>:24
scala> val rdd2 = rdd1.flatMap(_.split("\\s+"))
rdd2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[12] at flatMap at <console>:25
scala> val rdd3 = rdd2.map((_, 1))
rdd3: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[13] at map at <console>:25
scala> val rdd4 = rdd3.reduceByKey(_+_)
rdd4: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[14] at reduceByKey at <console>:25
scala> val rdd5 = rdd4.sortByKey()
rdd5: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[17] at sortByKey at <console>:25
scala> rdd5.count
res7: Long = 5
// 查看RDD的血缘关系
scala> rdd1.toDebugString
res8: String =
(2) /wcinput/wc.txt MapPartitionsRDD[11] at textFile at <console>:24 []
| /wcinput/wc.txt HadoopRDD[10] at textFile at <console>:24 []
scala> rdd5.toDebugString
res9: String =
(2) ShuffledRDD[17] at sortByKey at <console>:25 []
+-(2) ShuffledRDD[14] at reduceByKey at <console>:25 []
+-(2) MapPartitionsRDD[13] at map at <console>:25 []
| MapPartitionsRDD[12] at flatMap at <console>:25 []
| /wcinput/wc.txt MapPartitionsRDD[11] at textFile at <console>:24 []
| /wcinput/wc.txt HadoopRDD[10] at textFile at <console>:24 []
// 查看依赖
scala> rdd1.dependencies
res10: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.OneToOneDependency@793ede88)
scala> rdd1.dependencies(0).rdd
res11: org.apache.spark.rdd.RDD[_] = /wcinput/wc.txt HadoopRDD[10] at textFile at <console>:24
scala> rdd5.dependencies
res12: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.ShuffleDependency@76ca2fa7)
scala> rdd5.dependencies(0).rdd
res13: org.apache.spark.rdd.RDD[_] = ShuffledRDD[14] at reduceByKey at <console>:25
// 查看最佳优先位置
scala> val hadoopRDD = rdd1.dependencies(0).rdd
hadoopRDD: org.apache.spark.rdd.RDD[_] = /wcinput/wc.txt HadoopRDD[10] at textFile at <console>:24
scala> hadoopRDD.preferredLocations(hadoopRDD.partitions(0))
res14: Seq[String] = ArraySeq(Linux121, Linux123, Linux122)
# 使用 hdfs 命令检查文件情况
[root@Linux121 ~]# hdfs fsck /wcinput/wc.txt -files -blocks -locations
Connecting to namenode via http://Linux121:50070/fsck?ugi=root&files=1&blocks=1&locations=1&path=%2Fwcinput%2Fwc.txt
FSCK started by root (auth:SIMPLE) from /192.168.91.121 for path /wcinput/wc.txt at Tue Aug 30 03:17:24 WEST 2022
/wcinput/wc.txt 108 bytes, 1 block(s): OK
0. BP-364958193-192.168.91.121-1654312458375:blk_1073743340_2518 len=108 Live_repl=3 [DatanodeInfoWithStorage[192.168.91.122:50010,DS-544bf1f7-21d4-4544-aa02-97ea359d927c,DISK], DatanodeInfoWithStorage[192.168.91.123:50010,DS-03aedb89-d6e4-4a26-b1e2-85c8d2991d4f,DISK], DatanodeInfoWithStorage[192.168.91.121:50010,DS-422e34a0-a422-443a-87d8-a46d92e8ab90,DISK]]问题:上面的WordCount中一共几个job,几个Stage,几个Task?

本例中整个过程分为1个job,3个Stage;6个Task
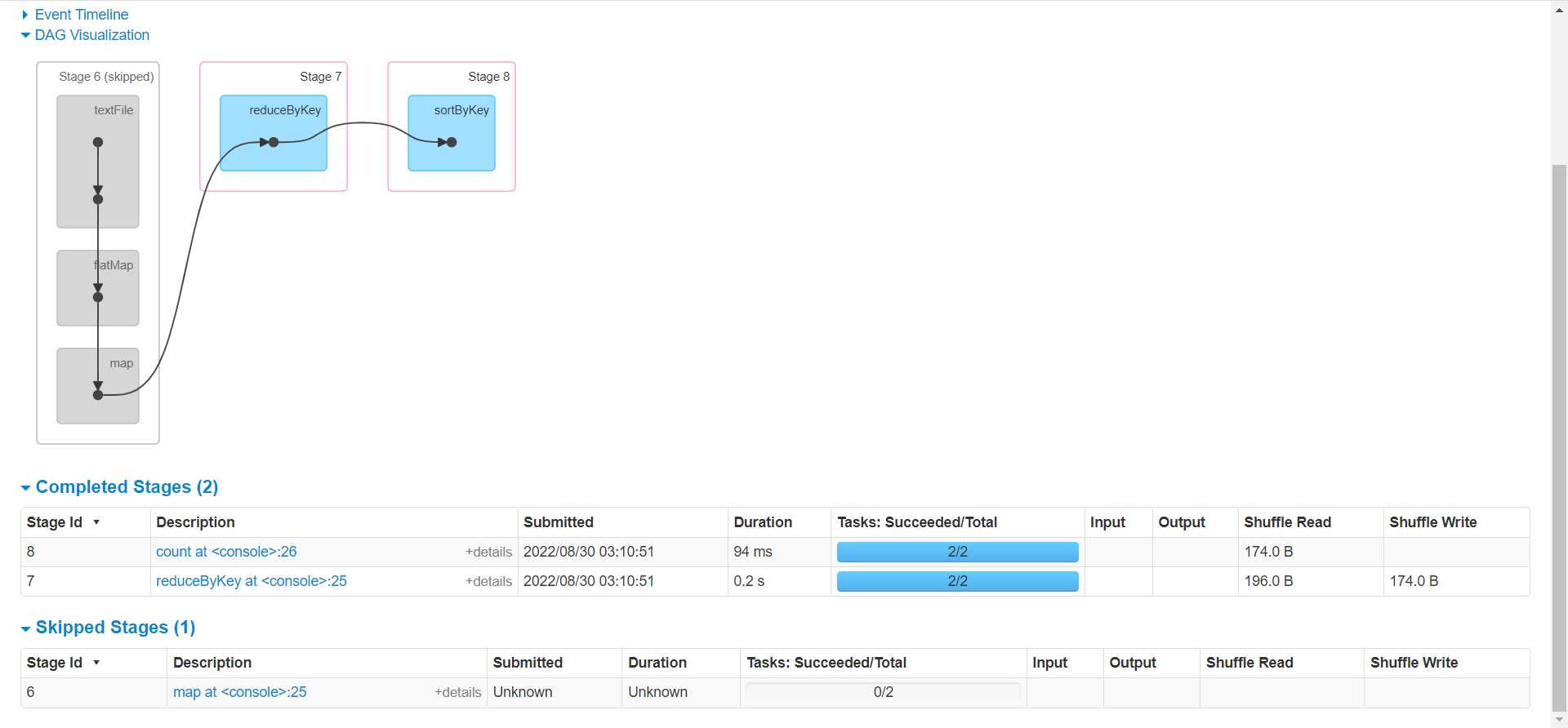
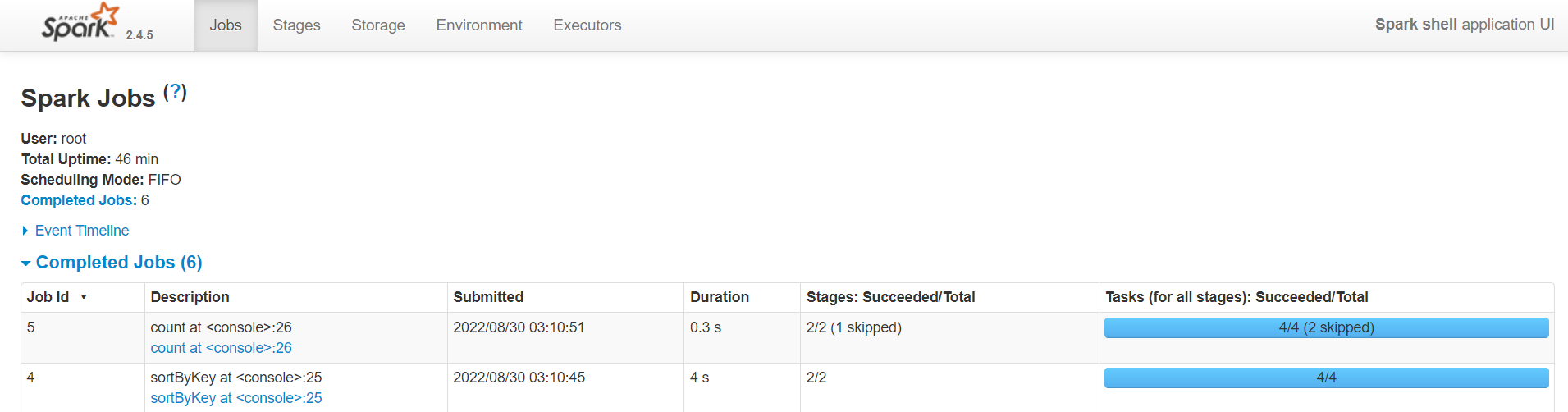
为什么这里显示有2个job?参见RDD编程之分区与分区器博客文章
 wechat
wechat alipay
alipay




