
核心交易分析之缓慢变化维与周期性事实表
缓慢变化维
缓慢变化维(SCD;Slowly Changing Dimensions)。在现实世界中,维度的属性随着时间的流失发生缓慢的变化(缓慢是相对事实表而言,事实表数据变化的速度比维度表快)。
处理维度表的历史变化信息的问题称为处理缓慢变化维的问题,简称SCD问题。处理缓慢变化维的方法有以下几种常见方式:
-
保留原值
维度属性值不做更改,保留原始值。
如商品上架售卖时间:一个商品上架售卖后由于其他原因下架,后来又再次上架,此种情况产生了多个商品上架售卖时间。如果业务重点关注的是商品首次上架售卖时间,则采用该方式。
-
直接覆盖
修改维度属性为最新值,直接覆盖,不保留历史信息。
如商品属于哪个品类:当商品品类发生变化时,直接重写为新品类。
-
增加新属性列
在维度表中增加新的一列,原先属性列存放上一版本的属性值,当前属性列存放当前版本的属性值,还可以增加一列记录变化的时间。
缺点:只能记录最后一次变化的信息。

-
快照表
每天保留一份全量数据。
简单、高效。缺点是信息重复,浪费磁盘空间。
适用范围:维表不能太大
使用场景多,范围广;一般而言维表都不大。
-
拉链表
拉链表适合于:表的数据量大,而且数据会发生新增和变化,但是大部分是不变的(数据发生变化的百分比不大),且是缓慢变化的(如电商中用户信息表中的某些用户基本属性不可能每天都变化)。主要目的是节省存储空间。
适用场景:
-
表的数据量大
-
表中部分字段会被更新
-
表中记录变量的比例不高
-
需要保留历史信息
-
维表拉链表应用案例
创建表加载数据(准备工作)
-
创建原始表与拉链表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22-- 用户信息
DROP TABLE IF EXISTS test.userinfo;
CREATE TABLE test.userinfo(
userid STRING COMMENT '用户编号',
mobile STRING COMMENT '手机号码',
regdate STRING COMMENT '注册日期'
) COMMENT '用户信息'
PARTITIONED BY (dt string)
row format delimited fields terminated by ',';
-- 拉链表(存放用户历史信息)
-- 拉链表不是分区表;多了两个字段start_date、end_date
DROP TABLE IF EXISTS test.userhis;
CREATE TABLE test.userhis(
userid STRING COMMENT '用户编号',
mobile STRING COMMENT '手机号码',
regdate STRING COMMENT '注册日期',
start_date STRING,
end_date STRING
)
COMMENT '用户信息拉链表'
row format delimited fields terminated by ','; -
创建本地数据文件(/data/lagoudw/data/userinfo.dat)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19cd /data/lagoudw/data
vim userinfo.dat
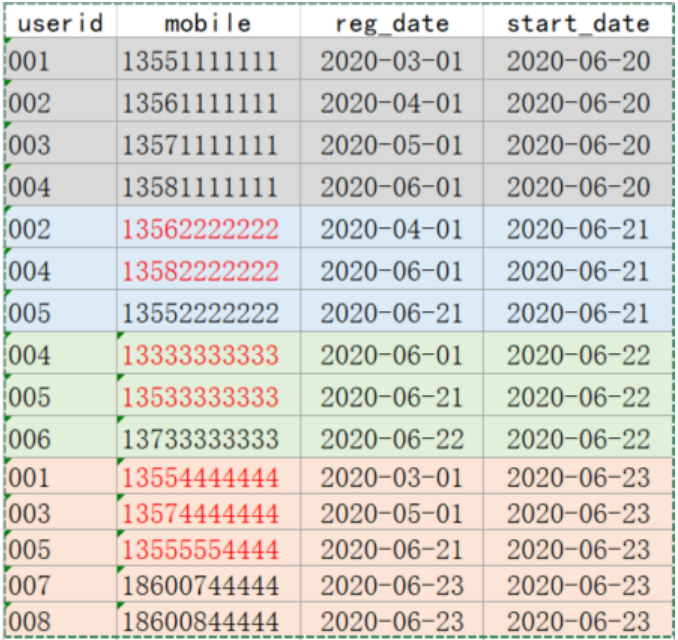
001,13551111111,2020-03-01,2020-06-20
002,13561111111,2020-04-01,2020-06-20
003,13571111111,2020-05-01,2020-06-20
004,13581111111,2020-06-01,2020-06-20
002,13562222222,2020-04-01,2020-06-21
004,13582222222,2020-06-01,2020-06-21
005,13552222222,2020-06-21,2020-06-21
004,13333333333,2020-06-01,2020-06-22
005,13533333333,2020-06-21,2020-06-22
006,13733333333,2020-06-22,2020-06-22
001,13554444444,2020-03-01,2020-06-23
003,13574444444,2020-05-01,2020-06-23
005,13555554444,2020-06-21,2020-06-23
007,18600744444,2020-06-23,2020-06-23
008,18600844444,2020-06-23,2020-06-23 -
静态分区数据加载
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30# 创建/data/lagoudw/data/userinfo0620.dat,内容如下
001,13551111111,2020-03-01,2020-06-20
002,13561111111,2020-04-01,2020-06-20
003,13571111111,2020-05-01,2020-06-20
004,13581111111,2020-06-01,2020-06-20
# 静态分区数据加载,hive执行
load data local inpath '/data/lagoudw/data/userinfo0620.dat' into table test.userinfo partition(dt='2020-06-20');
# 创建/data/lagoudw/data/userinfo0621.dat,内容如下
002,13562222222,2020-04-01,2020-06-21
004,13582222222,2020-06-01,2020-06-21
005,13552222222,2020-06-21,2020-06-21
# 静态分区数据加载,hive执行
load data local inpath '/data/lagoudw/data/userinfo0621.dat' into table test.userinfo partition(dt='2020-06-21');
# 创建/data/lagoudw/data/userinfo0622.dat,内容如下
004,13333333333,2020-06-01,2020-06-22
005,13533333333,2020-06-21,2020-06-22
006,13733333333,2020-06-22,2020-06-22
# 静态分区数据加载,hive执行
load data local inpath '/data/lagoudw/data/userinfo0622.dat' into table test.userinfo partition(dt='2020-06-22');
# 创建/data/lagoudw/data/userinfo0623.dat,内容如下
001,13554444444,2020-03-01,2020-06-23
003,13574444444,2020-05-01,2020-06-23
005,13555554444,2020-06-21,2020-06-23
007,18600744444,2020-06-23,2020-06-23
008,18600844444,2020-06-23,2020-06-23
# 静态分区数据加载,hive执行
load data local inpath '/data/lagoudw/data/userinfo0623.dat' into table test.userinfo partition(dt='2020-06-23'); -
动态分区数据加载:分区的值是不固定的,由输入数据确定
1
2
3
4
5
6
7
8
9
10
11
12
13
14-- 创建中间表(非分区表)
drop table if exists test.tmp1;
create table test.tmp1 as select * from test.userinfo;
-- tmp1 非分区表,使用系统默认的字段分割符'\001'
alter table test.tmp1 set serdeproperties('field.delim'=',');
-- 向中间表加载数据
load data local inpath '/data/lagoudw/data/userinfo.dat' into table test.tmp1;
-- 从中间表向分区表加载数据
set hive.exec.dynamic.partition.mode=nonstrict;
insert into table test.userinfo partition(dt)
select * from test.tmp1; -
与动态分区相关的参数
-
hive.exec.dynamic.partition,表示开启动态分区功能
-
Default Value: false prior to Hive 0.9.0;
-
true in Hive 0.9.0 and later Added In: Hive 0.6.0
Whether or not to allow dynamic partitions in DML/DDL.
-
-
hive.exec.dynamic.partition.mode
-
Default Value: strict
-
Added In: Hive 0.6.0
In strict mode, the user must specify at least one static partition in case the user accidentally overwrites all partitions. In nonstrict mode all partitions are allowed to be dynamic.
Set to nonstrict to support INSERT … VALUES, UPDATE, and DELETE transactions (Hive 0.14.0 and later).
strict:最少需要有一个是静态分区
nonstrict:可以全部是动态分区
-
-
hive.exec.max.dynamic.partitions
-
Default Value: 1000
-
Added In: Hive 0.6.0
Maximum number of dynamic partitions allowed to be created in total.
表示一个动态分区语句可以创建的最大动态分区个数,超出报错
-
-
hive.exec.max.dynamic.partitions.pernode
-
Default Value: 100
-
Added In: Hive 0.6.0
Maximum number of dynamic partitions allowed to be created in each mapper/reducer node.
表示每个mapper / reducer可以允许创建的最大动态分区个数,默认是100,超出则会报错。
-
-
hive.exec.max.created.files
-
Default Value: 100000
-
Added In: Hive 0.7.0
Maximum number of HDFS files created by all mappers/reducers in a MapReduce job.
表示一个MR job可以创建的最大文件个数,超出报错。
-
-
拉链表的实现
userinfo(分区表) => userid、mobile、regdate => 每日变更的数据(修改的+新增的) / 历史数据(第一天)
userhis(拉链表)=> 多了两个字段 start_date / end_date
1 | -- 1、userinfo初始化(2020-06-20)。获取历史数据 |
处理拉链表的脚本(测试脚本):
创建/data/lagoudw/data/userzipper.sh
1 | !/bin/bash |
拉链表的使用:
1 | -- 查看拉链表中最新数据(2020-06-23以后的数据) |
拉链表的回滚
1 | 06-20拉链表数据(sh xxx.sh 2020-06-20;在2020-06-21日凌晨发出命令): |
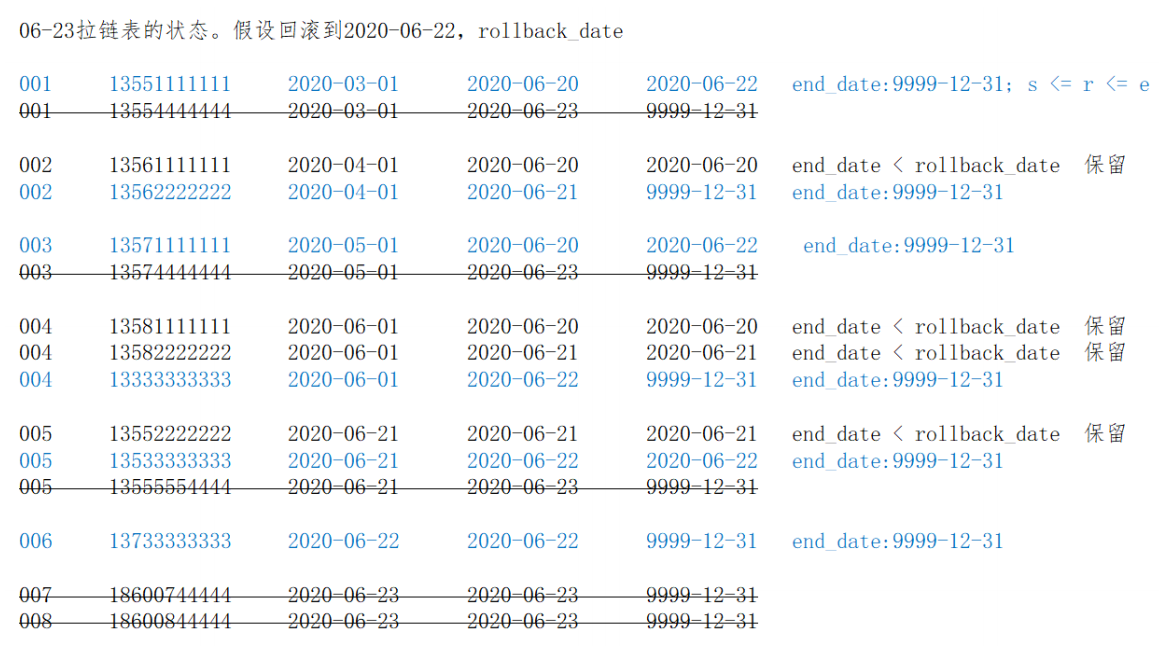
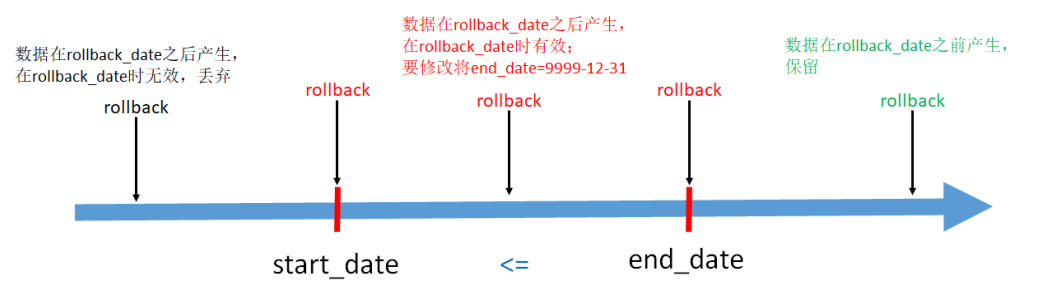
由于种种原因需要将拉链表恢复到 rollback_date 那一天的数据。此时有:
-
end_date < rollback_date,即结束日期 < 回滚日期。表示该行数据在 rollback_date 之前产生,这些数据需要原样保留
-
start_date <= rollback_date <= end_date,即开始日期 <= 回滚日期 <= 结束日期。这些数据是回滚日期之后产生的,但是需要修改。将end_date 改为 9999-12-31
-
其他数据不用管
-
1、处理 end_date < rollback_date 的数据,保留
1
2
3select userid, mobile, regdate, start_date, end_date, '1' as tag
from test.userhis
where end_date < '2020-06-22'; -
2、处理 start_date <= rollback_date <= end_date 的数据,设置end_date=9999-12-31
1
2
3select userid, mobile, regdate, start_date, '9999-12-31' as end_date, '2' as tag
from test.userhis
where start_date <= '2020-06-22' and end_date >= '2020-06- 22'; -
3、将前面两步的数据写入临时表tmp(拉链表)
1
2
3
4
5
6
7
8
9
10
11
12drop table test.tmp;
create table test.tmp as
select userid, mobile, regdate, start_date, end_date, '1' as tag
from test.userhis
where end_date < '2020-06-22'
union all
select userid, mobile, regdate, start_date, '9999-12-31' as end_date, '2' as tag
from test.userhis
where start_date <= '2020-06-22' and end_date >= '2020-06- 22';
select * from test.tmp cluster by userid, start_date; -
4、模拟脚本
创建/data/lagoudw/data/zippertmp.sh
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21!/bin/bash
source /etc/profile
if [ -n "$1" ] ;then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
drop table test.tmp;
create table test.tmp as
select userid, mobile, regdate, start_date, end_date, '1' as tag
from test.userhis
where end_date < '$do_date'
union all
select userid, mobile, regdate, start_date, '9999-12-31' as end_date, '2' as tag
from test.userhis
where start_date <= '$do_date' and end_date >= '$do_date';
"
hive -e "$sql"逐天回滚,检查数据;
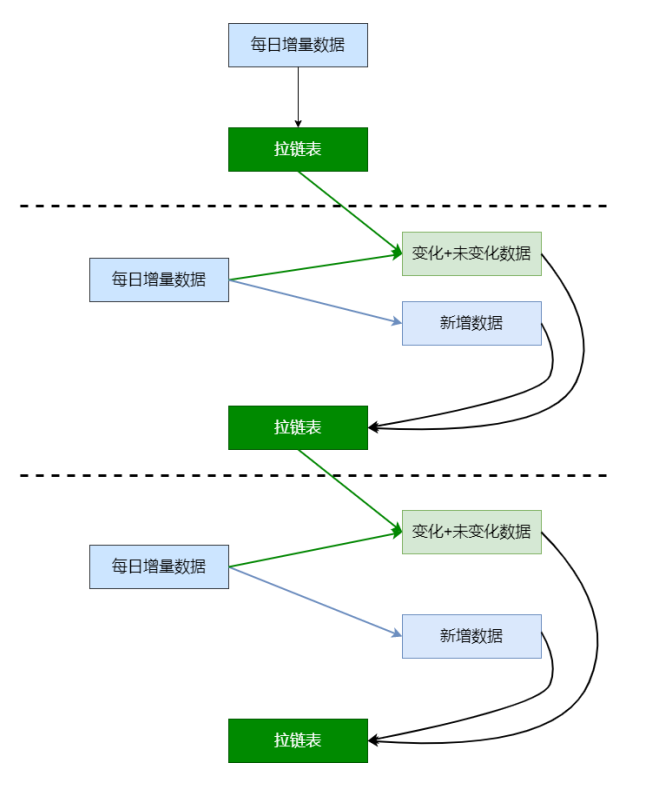
方案二:保存一段时间的增量数据(userinfo),定期对拉链表做备份(如一个月做一次备份);如需回滚,直接在备份的拉链表上重跑增量数据。处理简单。
周期性事实表
有如下订单表,6月20号有3条记录(001/002/003):
| 订单创建日期 | 订单编号 | 订单状态 |
|---|---|---|
| 2020-06-20 | 001 | 创建订单 |
| 2020-06-20 | 002 | 创建订单 |
| 2020-06-20 | 003 | 支付完成 |
6月21日,表中有5条记录。其中新增2条记录(004/005),修改1条记录(001):
| 订单创建日期 | 订单编号 | 订单状态 |
|---|---|---|
| 2020-06-20 | 001 | 支付完成(从创建到支付) |
| 2020-06-20 | 002 | 创建订单 |
| 2020-06-20 | 003 | 支付完成 |
| 2020-06-21 | 004 | 创建订单 |
| 2020-06-21 | 005 | 创建订单 |
6月22日,表中有6条记录。其中新增1条记录(006),修改2条记录(003/005):
| 订单创建日期 | 订单编号 | 订单状态 |
|---|---|---|
| 2020-06-20 | 001 | 支付完成 |
| 2020-06-20 | 002 | 创建订单 |
| 2020-06-20 | 003 | 已发货(从支付到发货) |
| 2020-06-21 | 004 | 创建订单 |
| 2020-06-21 | 005 | 支付完成(从创建到支付) |
| 2020-06-22 | 006 | 创建订单 |
订单事实表的处理方法:
-
只保留一份全量。数据和6月22日的记录一样,如果需要查看6月21日订单001的状态,则无法满足;
-
每天都保留一份全量。在数据仓库中可以在找到所有的历史信息,但数据量大了,而且很多信息都是重复的,会造成较大的存储浪费;
使用拉链表保存历史信息,会有下面这张表。历史拉链表,既能满足保存历史数据的需求,也能节省存储资源。
| 订单创建日期 | 订单编号 | 订单状态 | begin_date | end_date |
|---|---|---|---|---|
| 2020-06-20 | 001 | 创建订单 | 2020-06-20 | 2020-06-20 |
| 2020-06-20 | 001 | 支付完成 | 2020-06-21 | 9999-12-31 |
| 2020-06-20 | 002 | 创建订单 | 2020-06-20 | 9999-12-31 |
| 2020-06-20 | 003 | 支付完成 | 2020-06-20 | 2020-06-21 |
| 2020-06-20 | 003 | 已发货 | 2020-06-22 | 9999-12-31 |
| 2020-06-21 | 004 | 创建订单 | 2020-06-21 | 9999-12-31 |
| 2020-06-21 | 005 | 创建订单 | 2020-06-21 | 2020-06-21 |
| 2020-06-21 | 005 | 支付完成 | 2020-06-22 | 9999-12-31 |
| 2020-06-22 | 006 | 创建订单 | 2020-06-22 | 9999-12-31 |
前提条件
-
订单表的刷新频率为一天,当天获取前一天的增量数据;
-
如果一个订单在一天内有多次状态变化,只记录最后一个状态的信息;
-
订单状态包括三个:创建、支付、完成;
-
创建时间和修改时间只取到天,如果源订单表中没有状态修改时间,那么抽取增量就比较麻烦,需要有个机制来确保能抽取到每天的增量数据;
数仓ODS层有订单表,数据按日分区,存放每天的增量数据:
1 | DROP TABLE test.ods_orders; |
数仓DWD层有订单拉链表,存放订单的历史状态数据:
1 | DROP TABLE test.dwd_orders; |
周期性事实表拉链表的实现
-
1. 全量初始化
1
2
3
4
5
6
7
8
9
10-- 数据文件order1.dat
001,2020-06-20,2020-06-20,创建
002,2020-06-20,2020-06-20,创建
003,2020-06-20,2020-06-20,支付
load data local inpath '/data/lagoudw/data/order1.dat' into table test.ods_orders partition(dt='2020-06-20');
INSERT overwrite TABLE test.dwd_orders
SELECT orderid, createtime, modifiedtime, status, createtime AS start_date, '9999-12-31' AS end_date
FROM test.ods_orders
WHERE dt='2020-06-20'; -
2. 增量抽取
1
2
3
4
5-- 数据文件order2.dat
001,2020-06-20,2020-06-21,支付
004,2020-06-21,2020-06-21,创建
005,2020-06-21,2020-06-21,创建
load data local inpath '/data/lagoudw/data/order2.dat' into table test.ods_orders partition(dt='2020-06-21'); -
3. 增量刷新历史数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30-- 拉链表中的数据分两部实现:新增数据(ods_orders)、历史数据 (dwd_orders)
-- 处理新增数据
SELECT orderid, createtime, modifiedtime, status, modifiedtime AS start_date, '9999-12-31' AS end_date
FROM test.ods_orders where dt='2020-06-21';
-- 处理历史数据。历史数据包括:有修改、无修改的数据
-- ods_orders 与 dwd_orders 进行表连接
-- 连接上,说明数据被修改
-- 未连接上,说明数据未被修改
select A.orderid, A.createtime, A.modifiedtime, A.status, A.start_date,
case when B.orderid is not null and A.end_date>'2020- 06-21'
then '2020-06-20'
else A.end_date
end end_date
from dwd_orders A
left join (select * from ods_orders where dt='2020-06- 21') B on A.orderid=B.orderid;
-- 用以上信息覆写拉链表
insert overwrite table test.dwd_orders
SELECT orderid, createtime, modifiedtime, status, modifiedtime AS start_date, '9999-12-31' AS end_date
FROM test.ods_orders
where dt='2020-06-21'
union all
select A.orderid, A.createtime, A.modifiedtime, A.status, A.start_date,
case when B.orderid is not null and A.end_date>'2020- 06-21'
then '2020-06-20'
else A.end_date
end end_date
from dwd_orders A
left join (select * from ods_orders where dt='2020-06- 21') B on A.orderid=B.orderid;
拉链表小结
 wechat
wechat alipay
alipay