
Hive元数据管理
Metastore
在Hive的具体使用中,首先面临的问题便是如何定义表结构信息,跟结构化的数据映射成功。所谓的映射指的是一种对应关系。在Hive中需要描述清楚表跟文件之间的映
射关系、列和字段之间的关系等等信息。这些描述映射关系的数据的称之为Hive的元数据。该数据十分重要,因为只有通过查询它才可以确定用户编写sql和最终操作文
件之间的关系。
Metadata即元数据。元数据包含用Hive创建的database、table、表的字段等元信息。元数据存储在关系型数据库中。如hive内置的Derby、第三方如MySQL等。
Metastore即元数据服务,是Hive用来管理库表元数据的一个服务。有了它上层的服务不用再跟裸的文件数据打交道,而是可以基于结构化的库表信息构建计算框架。
通过Metastore服务将Hive的元数据暴露出去,而不是需要通过对Hive元数据库mysql的访问才能拿到Hive的元数据信息;
Metastore服务实际上就是一种thrift服务,通过它用户可以获取到Hive元数据,并且通过thrift获取元数据的方式,屏蔽了数据库访问需要驱动,url,用户名,密码等细节
Metastore三种配置方式
1. 内嵌模式
内嵌模式使用的是内嵌的Derby数据库来存储元数据,也不需要额外起Metastore服务。数据库和Metastore服务都嵌入在主Hive Server进程中。这个是默认的,配置简单,但是一次只能一个客户端连接,适用于用来实验,不适用于生产环境。
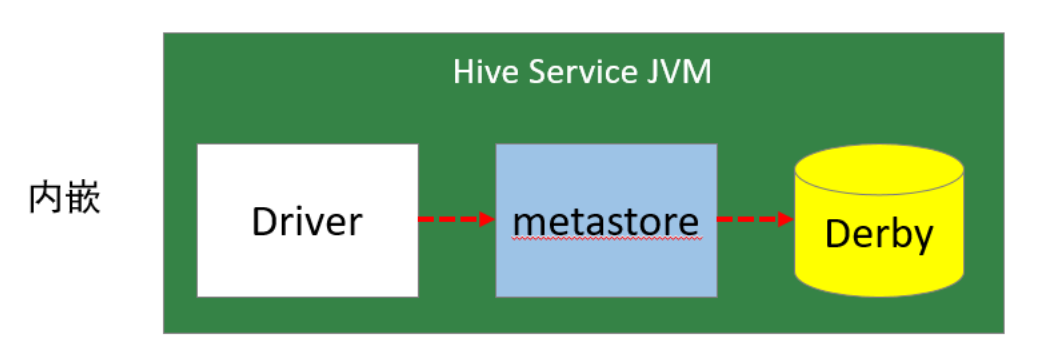
优点:配置简单,解压hive安装包 bin/hive 启动即可使用;
缺点:不同路径启动hive,每一个hive拥有一套自己的元数据,无法共享。
2. 本地模式
本地模式采用外部数据库来存储元数据,目前支持的数据库有:MySQL、Postgres、Oracle、MS SQL Server。教学中实际采用的是MySQL。
本地模式不需要单独起metastore服务,用的是跟Hive在同一个进程里的metastore服务。也就是说当启动一个hive 服务时,其内部会启动一个metastore服务。Hive根据 hive.metastore.uris 参数值来判断,如果为空,则为本地模式。
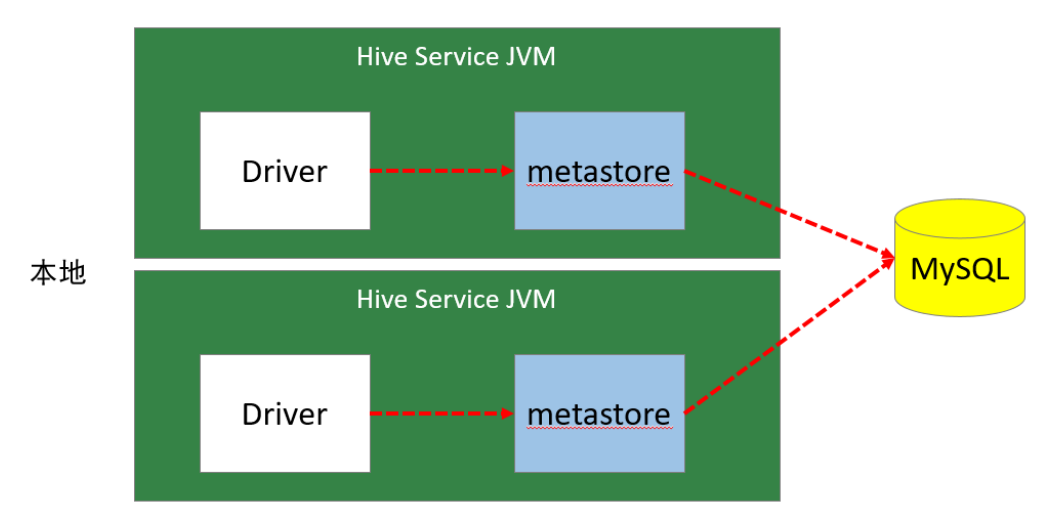
优点:配置较简单,本地模式下hive的配置中指定mysql的相关信息即可。
缺点:每启动一次hive服务,都内置启动了一个metastore;在hive-site.xml中暴露 的数据库的连接信息;
3. 远程模式
远程模式下,需要单独起metastore服务,然后每个客户端都在配置文件里配置连接到该metastore服务。远程模式的metastore服务和hive运行在不同的进程里。在生产环境中,建议用远程模式来配置Hive Metastore。
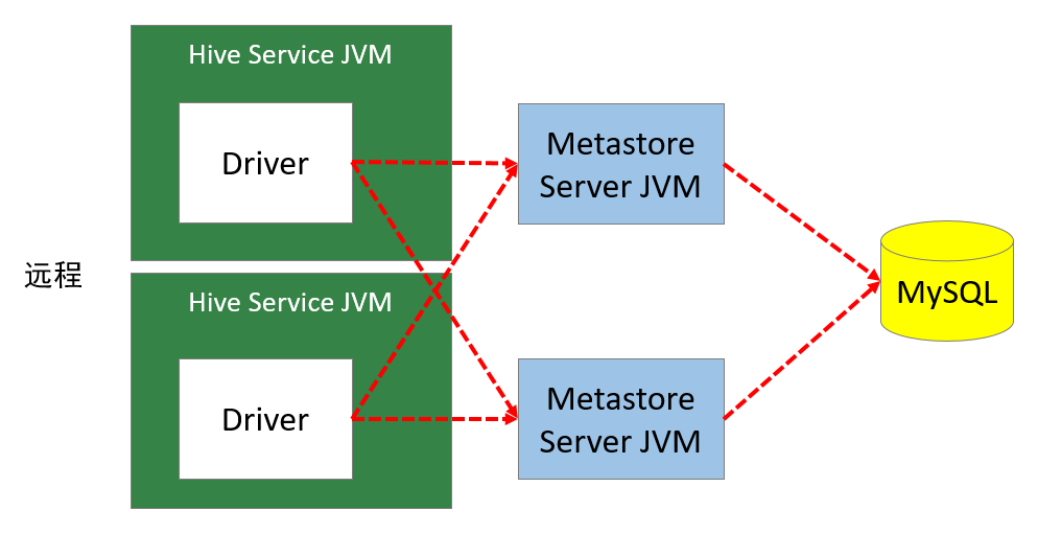
在这种模式下,其他依赖Hive的软件都可以通过Metastore访问Hive。此时需要配置hive.metastore.uris 参数来指定 metastore 服务运行的机器ip和端口,并且需要单独手动启动metastore服务。metastore服务可以配置多个节点上,避免单节点故障导致整个集群的hive client不可用。同时hive client配置多个metastore地址,会自动选择可用节点。
Metastore内嵌模式配置
- 下载软件并解压缩
- 设置环境变量,并使之生效
1 | vim /etc/profile |
- 初始化数据库。
1 | -- 进入解压后的hive的bin下 |

-
进入hive命令行
-
再打开一个窗口,进入hive命令行,发现无法进入
Metastore远程模式配置
配置规划

配置步骤
-
将 Linux123 的 hive 安装文件拷贝到 Linux121、Linux122
1
2
3
4
5
6
7
8
9
10
11-- 进入 Linux123 的hive
cd /opt/lagou/servers
-- 执行远程复制hive
scp -r hive-2.3.7/ Linux121:$PWD
scp -r hive-2.3.7/ Linux122:$PWD
-- 进入环境变量配置文件目录
cd /etc
-- 执行远程复制环境变量文件
scp profile Linux122:$PWD
scp profile Linux122:$PWD1
2
3
4
5-- 进入Linux121重新加载环境变量
source /etc/profile
-- 进入Linux122重新加载环境变量
source /etc/profile -
修改 linux122 上的hive-site.xml。删除配置文件中:MySQL的配置、连接数据库的用户名、口令等信息;增加连接metastore的配置:
1
2
3cd /opt/lagou/servers/hive-2.3.7/conf
vim hive-site.xml1
2
3
4
5<!-- hive metastore 服务地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://Linux121:9083,thrift://Linux123:9083</value>
</property>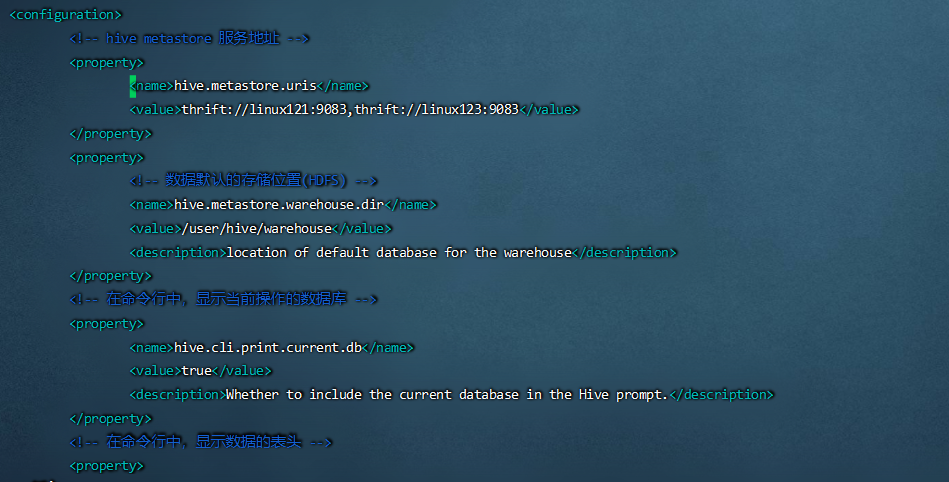
-
在Linux121、Linux123上分别启动 Metastore 服务
1
2
3
4
5
6
7
8# 启动 metastore 服务
nohup hive --service metastore &
# 安装lsof
yum install lsof
# 查询9083端口(metastore服务占用的端口)
lsof -i:9083 -
启动hive。此时client端无需实例化hive的Metastore,启动速度会加快。
1
2-- Linux122 执行
hive -
高可用测试。关闭已连接的Metastore服务,发现hive连到另一个节点的服务上,仍然能够正常使用。
HiveServer2
HiveServer2是一个服务端接口,使远程客户端可以执行对Hive的查询并返回结果。
目前基于Thrift RPC的实现是HiveServer的改进版本,并支持多客户端并发和身份验证,启动hiveServer2服务后,就可以使用jdbc、odbc、thrift 的方式连接。
Thrift是一种接口描述语言和二进制通讯协议,它被用来定义和创建跨语言的服务。它被当作一个远程过程调用(RPC)框架来使用,是由Facebook为“大规模跨语言服务开发”而开发的。
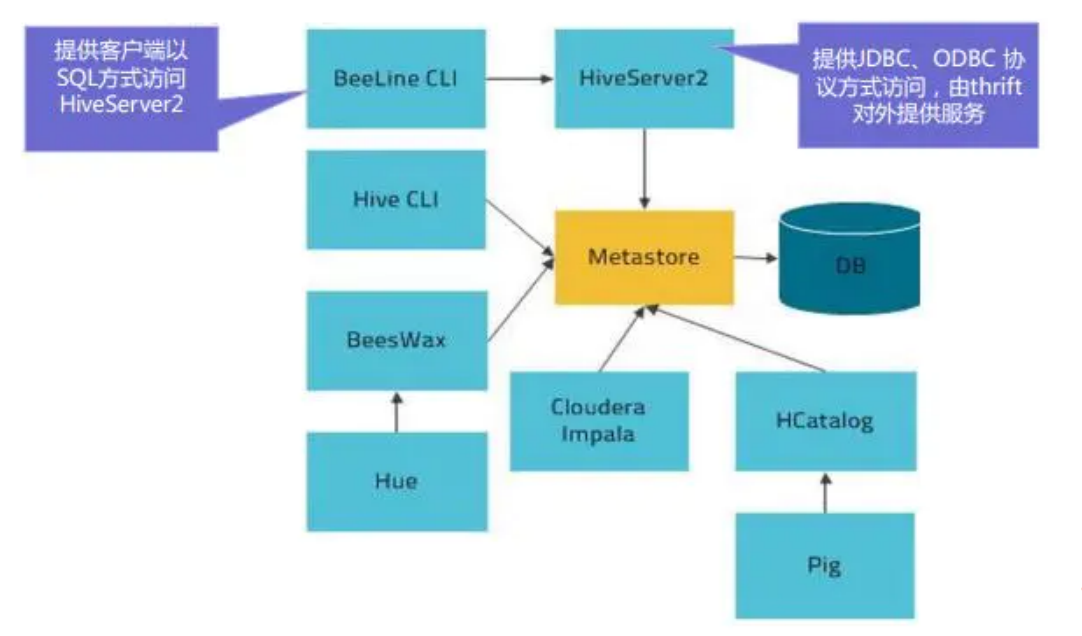
HiveServer2(HS2)是一种允许客户端对Hive执行查询的服务。HiveServer2是HiveServer1的后续 版本。HS2支持多客户端并发和身份验证,旨在为JDBC、ODBC等开放API客户端提供更好的支持。
HS2包括基于Thrift的Hive服务(TCP或HTTP)和用于Web UI 的Jetty Web服务器。
HiveServer2作用:
-
为Hive提供了一种允许客户端远程访问的服务
-
基于thrift协议,支持跨平台
-
跨编程语言对Hive访问,允许远程访问Hive
HiveServer2配置
配置规划
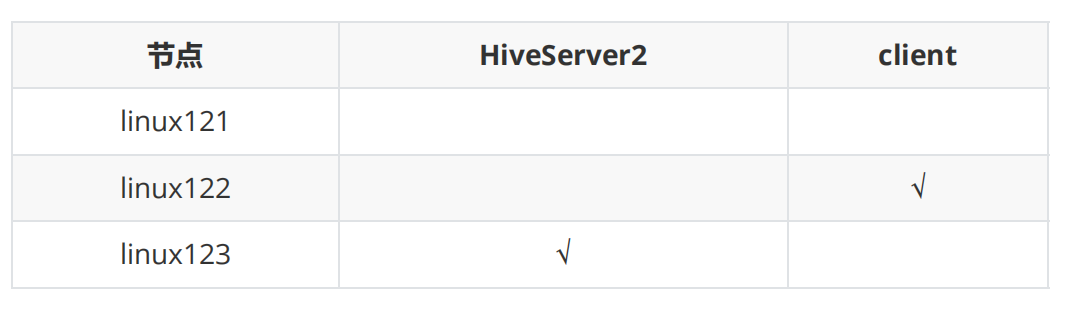
配置步骤
1. 修改集群上的 core-site.xml,增加以下内容
1 | -- 进入Linux121 虚拟机的Hadoop配置文件目录 |
2. 修改 集群上的 hdfs-site.xml,增加以下内容
1 | -- 进入Linux121 虚拟机的Hadoop配置文件目录 |
3. 重启启动Hadoop和yarn
1 | -- Hadoop和yarn 启动中 先关闭再重启 |
4. 启动linux123上的 HiveServer2 服务
1 | # 启动 hiveserver2 服务 |
5. 启动 linux122 节点上的 beeline
Beeline是从 Hive 0.11版本引入的,是 Hive 新的命令行客户端工具。
Hive客户端工具后续将使用Beeline 替代 Hive 命令行工具 ,并且后续版本也会废弃掉 Hive 客户端工具。
1 | -- 进入Linux122 的hive目录下的bin |
HCatalog
HCatalog 提供了一个统一的元数据服务,允许不同的工具如 Pig、MapReduce 等通过 HCatalog 直接访问存储在 HDFS 上的底层文件。HCatalog是用来访问Metastore的Hive子项目,它的存在给了整个Hadoop生态环境一个统一的定义。
HCatalog 使用了 Hive 的元数据存储,这样就使得像 MapReduce 这样的第三方应用可以直接从 Hive 的数据仓库中读写数据。同时,HCatalog 还支持用户在MapReduce 程序中只读取需要的表分区和字段,而不需要读取整个表,即提供一种逻辑上的视图来读取数据,而不仅仅是从物理文件的维度。
HCatalog 提供了一个称为 hcat 的命令行工具。这个工具和 Hive 的命令行工具类似,两者最大的不同就是 hcat 只接受不会产生 MapReduce 任务的命令。
1 | # 进入装有hive的虚拟机中 |
 wechat
wechat alipay
alipay




