爬虫的五个步骤
a) 需求分析 程序员,人工智能
b) 找到内容相关的网址 程序员
c) 根据网址获取到网址的返回信息 程序(urllib, requests)
d) 定位需要的信息位置 程序(re正则表达式, XPATH, css selector)
e) 存储内容 程序(文件系统open, pymysql, pymongo)
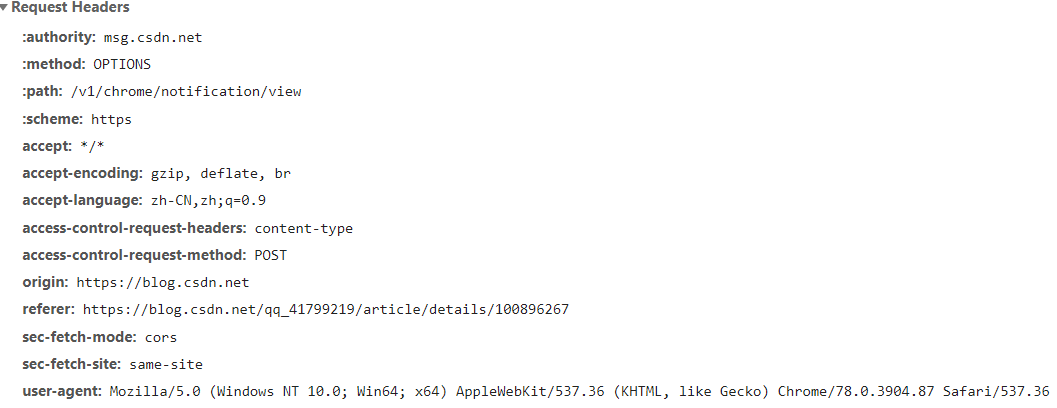
request包头的信息
-
重要的信息描述
a) Cookie : 能够存储一些服务器端的信息,与session共同完成身份标志的工作
b) User-Agent : 你的标签有哪些(就是身份,如浏览器是啥,操作系统,版本等等)
c) Referer : 从哪个页面跳转过来的(就是这个文件是在哪个网页里的
安装Fiddler和作用
去官网下载对应版本的fiddlersetup.exe安装程序。
安装完成后,启动程序,进入tools/options,点击connections
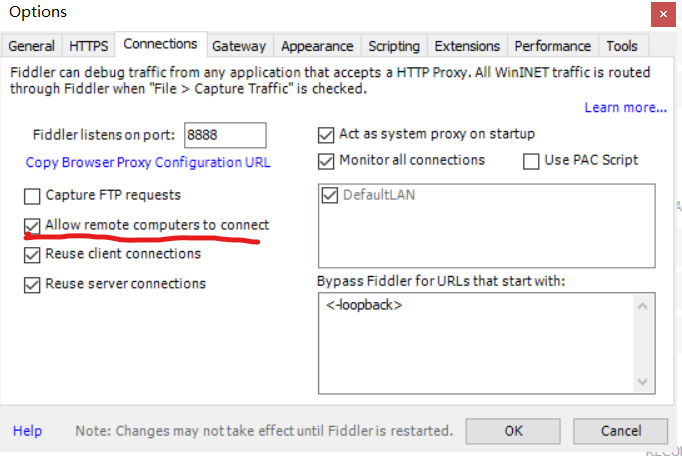
点击Https,勾选Decrypt Https traffic后,一直点击yes即可
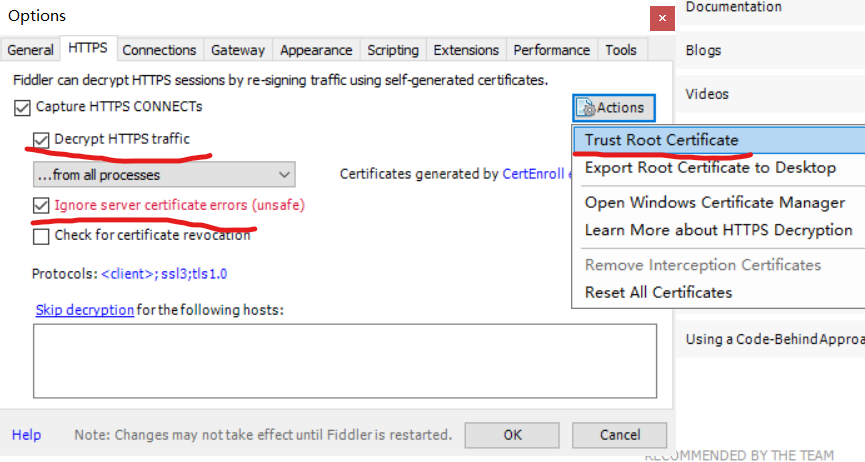
点击Actions,选择Trust root …后,一直点击yes即可
最后点击证书程序fiddlercertmaker.exe
启动fiddler,访问http和之前一样,但是访问https是会验证SSL,所以要在get里加入verify=False,
requests模块的使用
-
百度一下的爬取(不使用fiddler)
导入requests模块时,可能寻找不到此模块,我们可以去pycharm的setting里的project_interpreter里添加模块,也可以安装pip,直接在终端输入pip install requests
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| import requests
url = 'http://www.baidu.com'
response = requests.get(url)
print(response.text)
response.encoding = 'utf-8'
print(response.text)
print(response.content)
with open('baidu.html', 'wb') as f:
f.write(response.content)
|
-
西刺代理的爬取(使用fiddler)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| import requests
url = 'https://www.xicidaili.com/nn/'
'''
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
}
'''
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh,en-US;q=0.9,en;q=0.8,zh-CN;q=0.7',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': '_free_proxy_session=BAh7B0kiD3Nlc3Npb25faWQGOgZFVEkiJThjYWQ2OWY5ZWYzNWRkNzkzZDk1ZDVjNDI3MGNlNThmBjsAVEkiEF9jc3JmX3Rva2VuBjsARkkiMURzai8vRkcvekZwRHBZR21oOENrdTR3dG45RUtSNTJyUHJ0N3FwV21oTFE9BjsARg%3D%3D--b2cbd681cdf716a8d723652fd11410d993e78141; Hm_lvt_0cf76c77469e965d2957f0553e6ecf59=1547001545; Hm_lpvt_0cf76c77469e965d2957f0553e6ecf59=1547001545',
'Host': 'www.xicidaili.com',
'If-None-Match': 'W/"2cb72fa592d89c6159c54a04bc46c10b"',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
}
response = requests.get(url, headers=headers,verify=False)
with open('xicidaili.html', 'wb') as f:
f.write(response.content)
|
复制的request头的信息黏贴以后,在python文件中通过ctrl+f查找
1
2
| 勾选正则然后输入 ^(.*): (.*)
ctrl+r 替换成 '$1': '$2',
|
-
哔哩哔哩个人空间点赞数的爬取
爬取一个网站的时候,你需要确定信息是不是在这个网站上的,主要通过网页的检查源代码看看信息是否存在。
如果不存在,可以检查网页的ajax,点击network,在点击XHR,再通过preview查看ajax传输的数据
可以通过ctrl+f查找数据,找到数据后,观察General,得到以下数据
1
2
| Request URL: https://api.bilibili.com/x/space/upstat?mid=65713147&jsonp=jsonp&callback=__jp5
Request Method: GET
|
根据得到的url和请求方式来编写代码,以下是get方式的获取
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| import requests
import json
url = 'https://api.bilibili.com/x/space/upstat?mid=65713147&jsonp=jsonp&callback=__jp5'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Referer': 'https://space.bilibili.com/65713147/?spm_id_from=333.851.b_7265706f7274466972737432.6',
}
response = requests.get(url,headers=headers)
print(response.text)
with open('bilibili.html', 'wb') as f:
f.write(response.content)
|
-
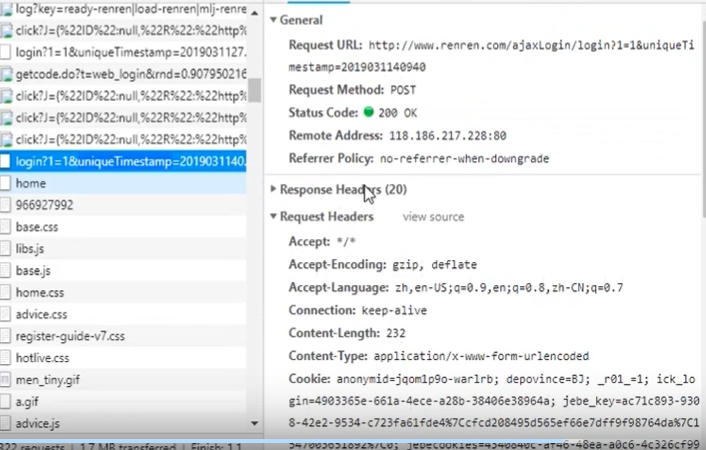
人人网的登录的爬取(不使用fiddler)
登陆表单提交是post方式,登录后会跳转,如果我们获取的数据是登录后才能访问的访问内容,我们可以用session类代替request来表示已登录
注意,在检查源代码的过程中, 最好将preserve_log勾选上,右键->检查->network->Preserve log(刷新页面是,network不刷新)
一般不需验证,只需要body,即使用form data,如果不成功,就在加上header
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| import requests
url = 'http://www.renren.com/ajaxLogin/login?1=1&uniqueTimestamp=2019031140940'
s = requests.session()
form = {
'email': '18510556963',
'icode': '',
'origURL': 'http://www.renren.com/home',
'domain': 'renren.com',
'key_id': '1',
'captcha_type': 'web_login',
'password': '6616586e6b980c1ec90669dfba849f912beeffdf8e8fb2e5dcf089b5f1d4d768',
'rkey': 'c3fe0fee33045b75e4b4af194b111c69',
'f': '',
}
response = s.post(url, data=form)
print(response.text)
home_url = 'http://www.renren.com/home'
response = s.get(home_url, allow_redirects=True)
print(response.url)
with open('renren_home.html', 'wb') as f:
f.write(response.content)
print(response.text)
|

 wechat
wechat alipay
alipay



