
Spark-SQL编程之DataFrame和Dataset的创建
官方文档:http://spark.apache.org/docs/latest/sql-getting-started.html
SparkSession
在 Spark 2.0 之前:
-
SQLContext 是创建 DataFrame 和执行 SQL 的入口
-
HiveContext通过Hive sql语句操作Hive数据,兼Hhive操作,HiveContext继承自SQLContext
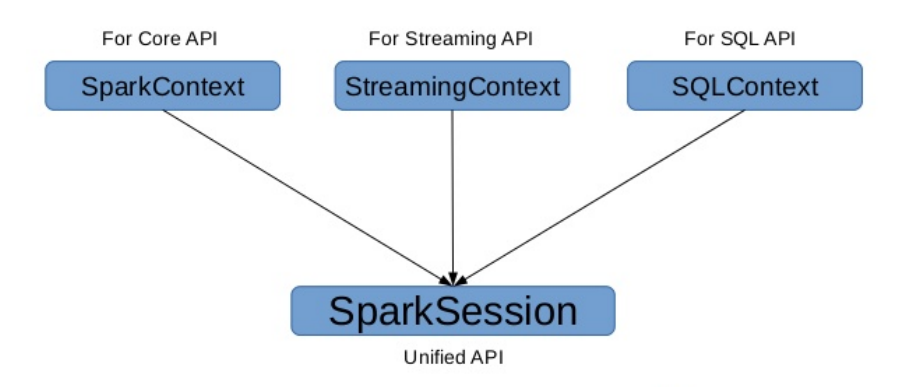
在 Spark 2.0 之后:
-
将这些入口点统一到了SparkSession,SparkSession 封装了 SqlContext 及HiveContext;
-
实现了 SQLContext 及 HiveContext 所有功能;
-
通过SparkSession可以获取到SparkConetxt;
1 | import org.apache.spark.sql.SparkSession |
DataFrame & Dataset 的创建
不要刻意区分:DF、DS。DF是一种特殊的DS;ds.transformation => df
由range生成Dataset
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
scala> val numDS = spark.range(5, 100, 5)
numDS: org.apache.spark.sql.Dataset[Long] = [id: bigint]
// orderBy 转换操作;desc:function;show:Action
scala> numDS.orderBy(desc("id")).show(5)
+---+
| id|
+---+
| 95|
| 90|
| 85|
| 80|
| 75|
+---+
only showing top 5 rows
// 统计信息
scala> numDS.describe().show
+-------+------------------+
|summary| id|
+-------+------------------+
| count| 19|
| mean| 50.0|
| stddev|28.136571693556885|
| min| 5|
| max| 95|
+-------+------------------+
// 显示schema信息
scala> numDS.printSchema
root
|-- id: long (nullable = false)
// 使用RDD执行同样的操作
scala> numDS.rdd.map(_.toInt).stats
res3: org.apache.spark.util.StatCounter = (count: 19, mean: 50.000000, stdev: 27.386128, max: 95.000000, min: 5.000000)
// 检查分区数
scala> numDS.rdd.getNumPartitions
res4: Int = 12
由集合生成Dataset
Dataset = RDD[case class]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
scala> case class Person(name:String, age:Int, height:Int)
defined class Person
// 注意 Seq 中元素的类型
scala> val seq1 = Seq(Person("Jack", 28, 184), Person("Tom", 10, 144), Person("Andy", 16, 165))
seq1: Seq[Person] = List(Person(Jack,28,184), Person(Tom,10,144), Person(Andy,16,165))
scala> val ds1 = spark.createDataset(seq1)
ds1: org.apache.spark.sql.Dataset[Person] = [name: string, age: int ... 1 more field]
// 显示schema信息
scala> ds1.printSchema
root
|-- name: string (nullable = true)
|-- age: integer (nullable = false)
|-- height: integer (nullable = false)
scala> ds1.show
+----+---+------+
|name|age|height|
+----+---+------+
|Jack| 28| 184|
| Tom| 10| 144|
|Andy| 16| 165|
+----+---+------+
scala> val seq2 = Seq(("Jack", 28, 184), ("Tom", 10, 144), ("Andy", 16, 165))
seq2: Seq[(String, Int, Int)] = List((Jack,28,184), (Tom,10,144), (Andy,16,165))
scala> val ds2 = spark.createDataset(seq2)
ds2: org.apache.spark.sql.Dataset[(String, Int, Int)] = [_1: string, _2: int ... 1 more field]
scala> ds2.show
+----+---+---+
| _1| _2| _3|
+----+---+---+
|Jack| 28|184|
| Tom| 10|144|
|Andy| 16|165|
+----+---+---+
由集合生成DataFrame
DataFrame = RDD[Row] + Schema
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
scala> val lst = List(("Jack", 28, 184), ("Tom", 10, 144), ("Andy", 16, 165))
lst: List[(String, Int, Int)] = List((Jack,28,184), (Tom,10,144), (Andy,16,165))
// 改单个字段名时简便
scala> val df1 = spark.createDataFrame(lst).withColumnRenamed("_1", "name1").withColumnRenamed("_2", "age1").withColumnRenamed("_3", "height1")
df1: org.apache.spark.sql.DataFrame = [name1: string, age1: int ... 1 more field]
scala> df1.orderBy("age1").show(10)
+-----+----+-------+
|name1|age1|height1|
+-----+----+-------+
| Tom| 10| 144|
| Andy| 16| 165|
| Jack| 28| 184|
+-----+----+-------+
// desc是函数,在IDEA中使用是需要导包
scala> import org.apache.spark.sql.functions._
import org.apache.spark.sql.functions._
scala> df1.orderBy(desc("age1")).show(10)
+-----+----+-------+
|name1|age1|height1|
+-----+----+-------+
| Jack| 28| 184|
| Andy| 16| 165|
| Tom| 10| 144|
+-----+----+-------+
// 修改整个DF的列名
scala> val df2 = spark.createDataFrame(lst).toDF("name", "age", "height")
df2: org.apache.spark.sql.DataFrame = [name: string, age: int ... 1 more field]
RDD 转成 DataFrame
DataFrame = RDD[Row] + Schema
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
scala> import org.apache.spark.sql.Row
import org.apache.spark.sql.Row
scala> import org.apache.spark.sql.types._
import org.apache.spark.sql.types._
scala> val arr = Array(("Jack", 28, 184), ("Tom", 10, 144), ("Andy", 16, 165))
arr: Array[(String, Int, Int)] = Array((Jack,28,184), (Tom,10,144), (Andy,16,165))
scala> val rdd1 = sc.makeRDD(arr).map(f=>Row(f._1, f._2, f._3))
rdd1: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[30] at map at <console>:33
val schema = StructType(
StructField("name", StringType, false) ::
StructField("age", IntegerType, false) ::
StructField("height", IntegerType, false) ::
Nil
)
schema: org.apache.spark.sql.types.StructType = StructType(StructField(name,StringType,false), StructField(age,IntegerType,false), StructField(height,IntegerType,false))
val schema1 = (new StructType).
add("name", "string", false).
add("age", "int", false).
add("height", "int", false)
schema1: org.apache.spark.sql.types.StructType = StructType(StructField(name,StringType,false), StructField(age,IntegerType,false), StructField(height,IntegerType,false))
// RDD => DataFrame,要指明schema
scala> val rddToDF = spark.createDataFrame(rdd1, schema)
rddToDF: org.apache.spark.sql.DataFrame = [name: string, age: int ... 1 more field]
scala> rddToDF.orderBy(desc("name")).show(false)
+----+---+------+
|name|age|height|
+----+---+------+
|Tom |10 |144 |
|Jack|28 |184 |
|Andy|16 |165 |
+----+---+------+
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
scala> import org.apache.spark.sql.Row
import org.apache.spark.sql.Row
scala> import org.apache.spark.sql.types._
import org.apache.spark.sql.types._
scala> val arr1 = Array(("Jack", 28, null), ("Tom", 10, 144), ("Andy", 16, 165))
arr1: Array[(String, Int, Any)] = Array((Jack,28,null), (Tom,10,144), (Andy,16,165))
scala> val rdd1 = sc.makeRDD(arr1).map(f=>Row(f._1, f._2, f._3))
rdd1: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[36] at map at <console>:33
val structType = StructType(
StructField("name", StringType, false) ::
StructField("age", IntegerType, false) ::
StructField("height", IntegerType, false) ::
Nil
)
structType: org.apache.spark.sql.types.StructType = StructType(StructField(name,StringType,false), StructField(age,IntegerType,false), StructField(height,IntegerType,false))
// false 说明字段不能为空
scala> val schema1 = structType
schema1: org.apache.spark.sql.types.StructType = StructType(StructField(name,StringType,false), StructField(age,IntegerType,false), StructField(height,IntegerType,false))
scala> val df1 = spark.createDataFrame(rdd1, schema1)
df1: org.apache.spark.sql.DataFrame = [name: string, age: int ... 1 more field]
// 下一句执行报错(因为有空字段)
scala> df1.show
scheduler.TaskSetManager: Lost task 2.0 in stage 1.0 (TID 3, 192.168.91.121, executor 1): java.lang.RuntimeException: Error while encoding: java.lang.RuntimeException: The 2th field 'height' of input row cannot be null.
staticinvoke(class org.apache.spark.unsafe.types.UTF8String, StringType, fromString, validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 0, name), StringType), true, false) AS name#0
validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 1, age), IntegerType) AS age#1
validateexternaltype(getexternalrowfield(assertnotnull(input[0, org.apache.spark.sql.Row, true]), 2, height), IntegerType) AS height#2
// true 允许该字段为空,语句可以正常执行
val schema2 = StructType(
StructField("name", StringType, false) ::
StructField("age", IntegerType, false) ::
StructField("height", IntegerType, true) ::
Nil
)
schema2: org.apache.spark.sql.types.StructType = StructType(StructField(name,StringType,false), StructField(age,IntegerType,false), StructField(height,IntegerType,true))
scala> val df2 = spark.createDataFrame(rdd1, schema2)
df2: org.apache.spark.sql.DataFrame = [name: string, age: int ... 1 more field]
scala> df2.show
+----+---+------+
|name|age|height|
+----+---+------+
|Jack| 28| null|
| Tom| 10| 144|
|Andy| 16| 165|
+----+---+------+
// IDEA中需要,spark-shell中不需要
scala> import spark.implicits._
import spark.implicits._
scala> val arr2 = Array(("Jack", 28, 150), ("Tom", 10, 144), ("Andy", 16, 165))
arr2: Array[(String, Int, Int)] = Array((Jack,28,150), (Tom,10,144), (Andy,16,165))
scala> val rddToDF = sc.makeRDD(arr2).toDF("name", "age", "height")
rddToDF: org.apache.spark.sql.DataFrame = [name: string, age: int ... 1 more field]
scala> case class Person(name:String, age:Int, height:Int)
defined class Person
scala> val arr2 = Array(("Jack", 28, 150), ("Tom", 10, 144), ("Andy", 16, 165))
arr2: Array[(String, Int, Int)] = Array((Jack,28,150), (Tom,10,144), (Andy,16,165))
scala> val rdd2 = spark.sparkContext.makeRDD(arr2).map(f=>Person(f._1, f._2, f._3))
rdd2: org.apache.spark.rdd.RDD[Person] = MapPartitionsRDD[14] at map at <console>:34
scala> val ds2 = rdd2.toDS()
ds2: org.apache.spark.sql.Dataset[Person] = [name: string, age: int ... 1 more field]
// 反射推断,spark 通过反射从case class的定义得到类名
scala> val df2 = rdd2.toDF()
df2: org.apache.spark.sql.DataFrame = [name: string, age: int ... 1 more field]
// 反射推断
scala> ds2.printSchema
root
|-- name: string (nullable = true)
|-- age: integer (nullable = false)
|-- height: integer (nullable = false)
scala> df2.printSchema
root
|-- name: string (nullable = true)
|-- age: integer (nullable = false)
|-- height: integer (nullable = false)
scala> ds2.orderBy(desc("name")).show(10)
+----+---+------+
|name|age|height|
+----+---+------+
| Tom| 10| 144|
|Jack| 28| 150|
|Andy| 16| 165|
+----+---+------+
scala> df2.orderBy(desc("name")).show(10)
+----+---+------+
|name|age|height|
+----+---+------+
| Tom| 10| 144|
|Jack| 28| 150|
|Andy| 16| 165|
+----+---+------+
RDD转Dataset
Dataset = RDD[case class]
DataFrame = RDD[Row] + Schema
1 | scala> val ds3 = spark.createDataset(rdd2) |
从文件创建DateFrame(以csv文件为例)
1 | val df1 = spark.read.csv("data/people1.csv") |
三者的转换
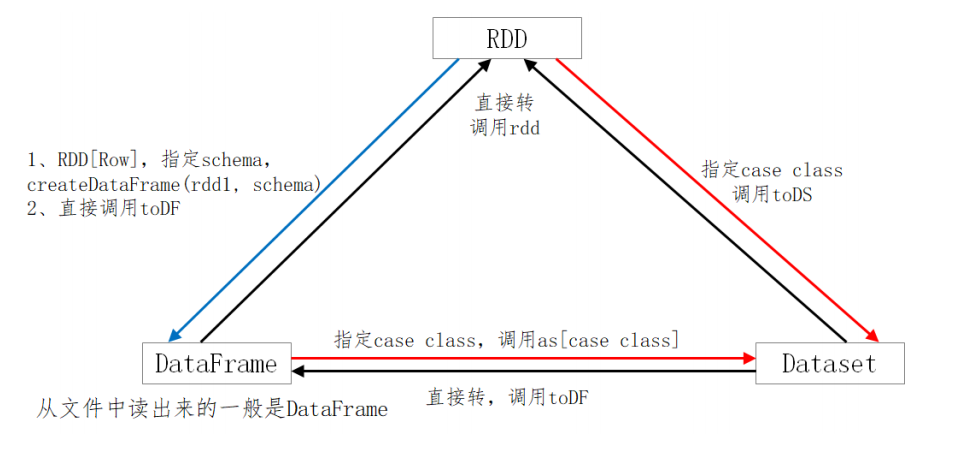
SparkSQL提供了一个领域特定语言(DSL)以方便操作结构化数据。核心思想还是SQL;仅仅是一个语法的问题。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 WeiJia_Rao!
 wechat
wechat alipay
alipay



