数据说明
学生信息表(student_txt)定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 -- 创建数据库 create database tuning; use tuning; -- 创建表 create table if not exists tuning.student_txt( s_no string comment '学号', s_name string comment '姓名', s_birth string comment '出生日期', s_age int comment '年龄', s_sex string comment '性别', s_score int comment '综合得分', s_desc string comment '自我介绍' )row format delimited fields terminated by '\t'; -- 数据加载 load data local inpath '/root/hive/student/*.txt' into table tuning.student_txt;
数据文件位置:/root/hive/student,50个文件,每个文件平均大小 40M 左右,包含4W条左右的信息;
SQL案例
查询 student_txt 表,每个年龄最晚出生和最早出生的人的出生日期,并将其存入表student_stat 中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 -- 创建 student_stat 表 create table student_stat ( age int, brith string ) partitioned by (tp string); -- 开启动态分区 set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict; -- 插入数据 insert overwrite table student_stat partition(tp) select s_age, max(s_birth) stat, 'max' tp from student_txt group by s_age union all select s_age, min(s_birth) stat, 'min' tp from student_txt group by s_age; -- 备注:union all 重复的行不会被删除
静态分区:若分区的值是确定的,新增分区或者是加载分区数据时,指定分区名
动态分区:分区的值是非确定的,由输入数据来确定
hive.exec.dynamic.partition(默认值true),是否开启动态分区功能,默认开启
hive.exec.dynamic.partition.mode(默认值strict),动态分区的模式
strict 至少一个分区为静态分区
nonstrict 允许所有的分区字段都可以使用动态分区
执行计划
要了解Hive 是如何工作的,需要了解EXPLAIN的功能,它能帮助我们了解 Hive 如何将查询转化成 Mapreduce 任务。
Hive的执行计划不是最终真实的执行计划,但是对了解其中的细节仍然有帮助。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 explain select * from student_txt; explain select * from student_txt limit 10; Explain STAGE DEPENDENCIES: Stage-0 is a root stage STAGE PLANS: Stage: Stage-0 Fetch Operator limit: -1 Processor Tree: TableScan alias: student_txt Statistics: Num rows: 4317304 Data size: 2193190912 Basic stats: COMPLETE Column stats: NONE Select Operator expressions: s_no (type: string), s_name (type: string), s_birth (type: string), s_age (type: int), s_sex (type: string), s_score (type: int), s_desc (type: string) outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6 Statistics: Num rows: 4317304 Data size: 2193190912 Basic stats: COMPLETE Column stats: NONE ListSink
执行计划比较简单,只有一个Stage,这个Stage中只有Fetch Operator,读取数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 explain select count(*) from student_txt limit 10; Explain STAGE DEPENDENCIES: Stage-1 is a root stage Stage-0 depends on stages: Stage-1 STAGE PLANS: Stage: Stage-1 Map Reduce Map Operator Tree: TableScan alias: student_txt Statistics: Num rows: 1 Data size: 2193190912 Basic stats: COMPLETE Column stats: COMPLETE Select Operator Statistics: Num rows: 1 Data size: 2193190912 Basic stats: COMPLETE Column stats: COMPLETE Group By Operator aggregations: count(1) mode: hash outputColumnNames: _col0 Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: COMPLETE Reduce Output Operator sort order: Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: COMPLETE TopN Hash Memory Usage: 0.1 value expressions: _col0 (type: bigint) Reduce Operator Tree: Group By Operator aggregations: count(VALUE._col0) mode: mergepartial outputColumnNames: _col0 Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: COMPLETE Limit Number of rows: 10 Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: COMPLETE File Output Operator compressed: false Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: COMPLETE table: input format: org.apache.hadoop.mapred.SequenceFileInputFormat output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe Stage: Stage-0 Fetch Operator limit: 10 Processor Tree: ListSink
SQL语句 select count(*) from student_txt limit 10 :
Stage-1、Stage-0,Stage-0 依赖 Stage-1
Stage-0 在结果集中取10条数据,显示在屏幕上
Stage-1 包含Map Task 和 Reduce Task
1 2 3 4 5 6 7 8 explain select s_age, max(s_birth) stat, 'max' tp from student_txt group by s_age union all select s_age, min(s_birth) stat, 'min' tp from student_txt group by s_age;
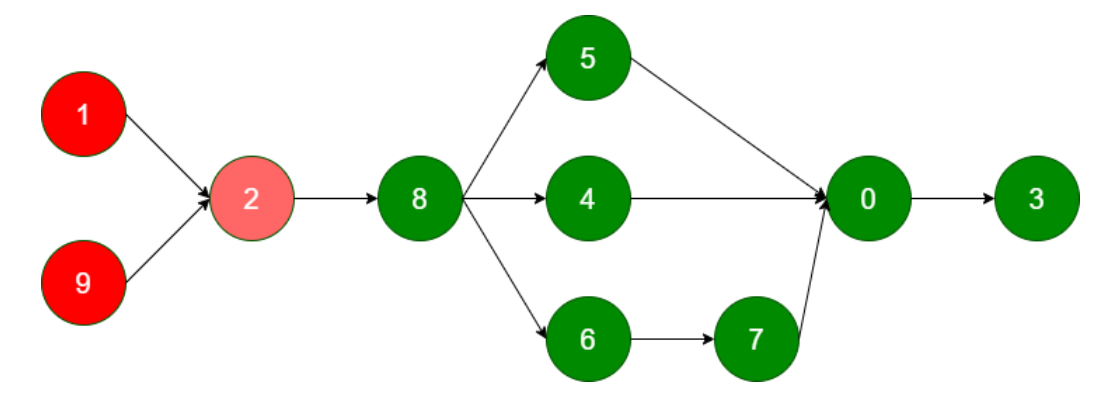
SQL有4个Stage,关系如下:
执行计划关键词信息说明
Map Reduce:表示当前任务所用的计算引擎是 MapReduce
Map Operator Tree:表示当前描述的 Map 阶段执行的操作信息
Reduce Operator Tree:表示当前描述的 Reduce 阶段执行的操作信息
Map/Reduce Operator Tree 关键信息说明
TableScan:表示对关键字 alias 声明的结果集进行扫描
Statistics:表示当前 Stage 的统计信息,这个信息通常是预估值
Filter Operator:表示在数据集上进行过滤
predicate:表示在 Filter Operator 进行过滤时,所用的谓词
Select Operator:表示对结果集上对列进行投影,即筛选列
expressions:表示需要投影的列,即筛选的列
outputColumnNames:表示输出的列名
Group By Operator:表示在结果集上分组聚合
aggregations:表示分组聚合使用的算法
keys:分组的列
Reduce Output Operator:表示当前描述的是对之前结果聚合后的信息
key expressions / value expressions:Map阶段输出key、value所用的数据列
sort order:是否进行排序,+ 正序,- 倒序
Map-reduce partition columns:Map 阶段输出到 Reduce 阶段的分区列
compressed:文件输出的结果是否进行压缩
input format / output format:输入输出的文件类型
serde:数据序列化、反序列化的方式
执行计划小结
一条 Hive SQL 语句会包含一个或多个Stage,不同的 Stage 间会存在着依赖关系。
越复杂的查询有越多的Stage,Stage越多就需要越多的时间时间来完成。
一个Stage可以是:Mapreduce任务(最耗费资源)、Move Operator(数据移动)、Stats-Aggr Operator(搜集统计数据)、Fetch Operator(读取数据)等;默认情况下,Hive一次只执行一个stage。
问题解答
问题1:SQL执行过程中有多少个job(Stage)
1 2 3 4 5 6 7 8 explain insert overwrite table student_stat partition(tp) select s_age, max(s_birth) stat, 'max' tp from student_txt group by s_age union all select s_age, min(s_birth) stat, 'min' tp from student_txt group by s_age;
整个SQL语句分为 10 个Stage
其中Stage-1、Stage-9包含 Map Task、Reduce Task
Stage-2 完成数据合并
Stage 8、5、4、6、7、0 组合完成数据的插入(动态分区插入)
Stage-3 收集SQL语句执行过程中的统计信息
Stage-1、Stage-9、Stage-2 最为关键,占用了整个SQL绝大部分资源
问题2:为什么在 Stage-1、Stage-9 中都有 9个 Map task、9个 Reduce task
决定map task、reduce task的因素比较多,包括文件格式、文件大小(关键因素)、文件数量、参数设置等。下面是两个重要参数:
在Map Task中输入数据大小:2193190840 / 256000000 = 9
如何调整Map task、Reduce task的个数?
将这两个参数放大一倍设置,观察是否生效:
1 2 3 4 5 6 7 8 9 10 11 set mapred.max.split.size=512000000; set hive.exec.reducers.bytes.per.reducer=512000000; insert overwrite table student_stat partition(tp) select s_age, max(s_birth) stat, 'max' tp from student_txt group by s_age union all select s_age, min(s_birth) stat, 'min' tp from student_txt group by s_age;
此时 Map Task、Reduce Task的个数均为5个,执行时间 80S 左右。
SQL优化
方法一:减少Map、Reduce Task 数
1 2 3 4 5 6 7 8 9 10 11 set mapred.max.split.size=1024000000; set hive.exec.reducers.bytes.per.reducer=1024000000; insert overwrite table student_stat partition(tp) select s_age, max(s_birth) stat, 'max' tp from student_txt group by s_age union all select s_age, min(s_birth) stat, 'min' tp from student_txt group by s_age;
参数从 256M => 512M ,有效果; 参数从 512M => 1024M,效果不明显
有效果,说明了一个问题:设置合理的Map、Reduce个数
方法二:减少Stage
使用Hive多表插入语句。可以在同一个查询中使用多个 insert 子句,这样的好处是只需要扫描一次源表就可以生成多个不相交的输出。如:
1 2 3 4 5 6 from tab1 insert overwrite table tab2 partition (age) select name,address,school,age insert overwrite table tab3 select name,address where age>24;
多表插入的关键点:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 -- 开启动态分区插入 set hive.exec.dynamic.partition=true; set hive.exec.dynamic.partition.mode=nonstrict; -- 优化后的SQL from student_txt insert overwrite table student_stat partition(tp) select s_age, max(s_birth) stat, 'max' tp group by s_age insert overwrite table student_stat partition(tp) select s_age, min(s_birth) stat, 'min' tp group by s_age; -- 执行计划 explain from student_txt insert overwrite table student_stat partition(tp) select s_age, max(s_birth) stat, 'max' tp group by s_age insert overwrite table student_stat partition(tp) select s_age, min(s_birth) stat, 'min' tp group by s_age;
减少 stage,最关键的是减少了一次数据源的扫描,性能得到了提升。
文件格式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 -- 创建表插入数据,改变表的存储格式 create table student_parquet stored as parquet as select * from student_txt; select count(1) from student_parquet; -- 仅创建表结构,改变表的存储格式,但是分区的信息丢掉了 create table student_stat_parquet stored as parquet as select * from student_stat where 1>2; -- 重新创建表 drop table student_stat_parquet; create table student_stat_parquet ( age int, b string ) partitioned by (tp string) stored as parquet;
CTAS创建表存储格式变成默认格式TEXTFILE,可以在CTAS语句中指定表的存储格式,行和列的分隔符等。
使用as select查询创建并填充表,select中选取的列名会作为新表的列名,会改变表的属性、结构,只能是内部表、分区分桶也没有了,字段的注释comment也会丢掉。
更改表的存储格式后,数据文件大小在50M左右。
1 2 3 4 5 6 7 8 9 10 11 12 explain select count(1) from student_parquet; Explain STAGE DEPENDENCIES: Stage-0 is a root stage STAGE PLANS: Stage: Stage-0 Fetch Operator limit: 1 Processor Tree: ListSink
parquet 文件保存了很多的元数据信息,所以这里没有Map、Reduce Task,直接从文件中的元数据就可以获取记录行数。
1 2 3 4 5 6 7 8 9 from student_parquet insert into table student_stat_parquet partition(tp) select s_age, min(s_birth) stat, 'min' tp group by s_age insert into table student_stat_parquet partition(tp) select s_age, max(s_birth) stat, 'max' tp group by s_age; -- 禁用本地模式 set hive.exec.mode.local.auto=false;
使用parquet文件格式再执行SQL语句,此时符合本地模式的使用条件,执行速度非常快,仅 20S 左右;
禁用本地模式后,执行时间也在 40S 左右。

 wechat
wechat alipay
alipay



