雪球网的爬取
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 import requestsimport jsonheaders = { 'Accept' : 'application/json, text/plain, */*' , 'Accept-encoding' : 'gzip, deflate, br' , 'Accept-language' : 'zh-CN,zh;q=0.9' , 'Cookie' : 'aliyungf_tc=AQAAAOeXuT4bbQkAK43ItiYQYpmcKxei; acw_tc=2760824b15759005426311706e8c9a8474b7161bba769e895108bc4a5d7384; xq_a_token=c9d3b00a3bd89b210c0024ce7a2e049f437d4df3; xq_r_token=8712d4cae3deaa2f3a3d130127db7a20adc86fb2; u=981575900545496; Hm_lvt_1db88642e346389874251b5a1eded6e3=1575900546; device_id=24700f9f1986800ab4fcc880530dd0ed; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1575900583' , 'Referer' : 'https://xueqiu.com/' , 'User-Agent' : 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Mobile Safari/537.36' , } url = 'https://xueqiu.com/v4/statuses/public_timeline_by_category.json?since_id=-1&max_id=20358817&count=15&category=-1' def get_info (): global url response = requests.get(url, headers=headers) res_dict = json.loads(response.text) next_max_id = res_dict['next_max_id' ] url = 'https://xueqiu.com/v4/statuses/public_timeline_by_category.json?since_id=-1&max_id={}&count=15&category=-1' .format (next_max_id) cards_list = res_dict['list' ] for card in cards_list: data = card['data' ] data_dict = json.loads(data) title = data_dict["title" ] print (title) description = data_dict["description" ] print (description) user = data_dict['user' ] print (user) print () if __name__ == '__main__' : for i in range (5 ): print (url) get_info()
爱淘宝的爬取
获取商品列表的标题,销量,价格,促销价格,评论数量等信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 import requests import reimport jsonheaders = { 'Accept' : 'application/json, text/plain, */*' , 'Accept-encoding' : 'gzip, deflate, br' , 'Accept-language' : 'zh-CN,zh;q=0.9' , 'Cookie' : 'aliyungf_tc=AQAAAOeXuT4bbQkAK43ItiYQYpmcKxei; acw_tc=2760824b15759005426311706e8c9a8474b7161bba769e895108bc4a5d7384; xq_a_token=c9d3b00a3bd89b210c0024ce7a2e049f437d4df3; xq_r_token=8712d4cae3deaa2f3a3d130127db7a20adc86fb2; u=981575900545496; Hm_lvt_1db88642e346389874251b5a1eded6e3=1575900546; device_id=24700f9f1986800ab4fcc880530dd0ed; Hm_lpvt_1db88642e346389874251b5a1eded6e3=1575900583' , 'Referer' : 'https://xueqiu.com/' , 'User-Agent' : 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Mobile Safari/537.36' , } def get_info (url ): response = requests.get(url, headers=headers) pattern = '({.*})' res = re.search(pattern, response.text) res_dict = json.loads( res.group(1 )) items_list = res_dict['result' ]['item' ] print (items_list) for item in items_list: title = item['TITLE' ] print (title) sell = item['SELL' ] print ('销量: ' +sell) goodsprice = item['GOODSPRICE' ] print ('价格: ' +goodsprice) if (item['PROMOTEPRICE' ] != "" ): promoteprice = item['PROMOTEPRICE' ] print ('促销价格: ' +promoteprice) if 'feedGoodReviewCount' in item: feedGoodReviewCount = item['feedGoodReviewCount' ] print ('评论数量: ' +feedGoodReviewCount) print () if __name__ == '__main__' : for i in range (5 ): url = 'https://odin.re.taobao.com/m/NwirelessSem?pid=430680_1006&refpid=mm_26632258_3504122_32554087&keyword=%E5%86%85%E8%A1%A3&count=60&offset={}&pvid=_TL-99123&features=isMall%2CisPostFree%2CfeedGoodReviewCount%2C10000034&sbid=re-searching&clk1=d48dd25cf2c0befc9139235d33641b70&_=1547436191605&callback=jsonp{}' .format (60 *i,12 +i) print (url) get_info(url)
今日头条街拍的爬取
爬取次数多时,会被网站禁止访问
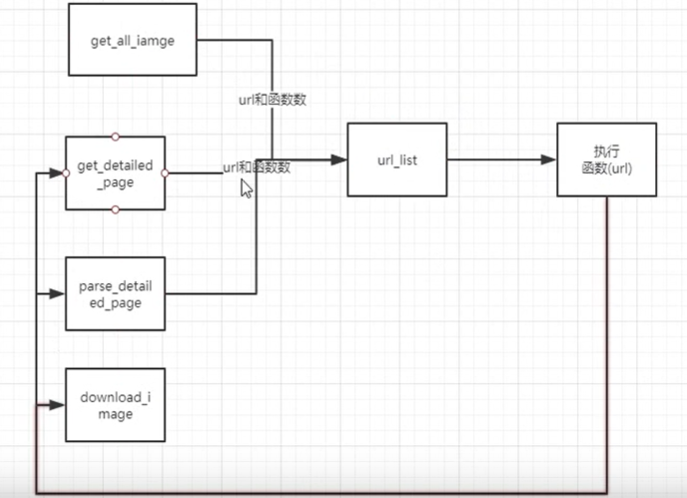
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 import requests import reimport jsonimport osimport timedef get_all_iamge (): if not os.path.exists(mydir): os.mkdir(mydir) for i in range (2 ): timestamp = round (time.time()*1000 ); url = 'https://www.toutiao.com/api/search/content/?aid=24&app_name=web_search&offset=0&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count={}&en_qc=1&cur_tab=1&from=search_tab&pd=synthesis×tamp={}' my_url = url.format (i*20 ,timestamp) get_detailed_page(my_url) def get_detailed_page (url ): headers = { 'cookie' : 'tt_webid=6768656694743909895; _ga=GA1.2.237111991.1575950710; _gid=GA1.2.1896547608.1575950710; WIN_WH=587_722; tt_webid=6768656694743909895; s_v_web_id=e2310544b094625945f5535a168a9ba0; WEATHER_CITY=%E5%8C%97%E4%BA%AC; csrftoken=f00fea89a91dade14cb27f4d9dd9e12b; __tasessionId=76sg2e3zu1575961424549' , 'referer' : 'https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D' , 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36' , 'x-requested-with' : 'XMLHttpReques' , } response = requests.get(url, headers=headers, verify=False ) res = response.json() data = res['data' ] for item in data: if 'article_url' in item: article_url = item['article_url' ] print (article_url) parse_detailed_page(article_url) def parse_detailed_page (url ): headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36' } response = requests.get(url, headers=headers, verify=False ) res_match = pat.search(response.text) if res_match: json_str = res_match.group(1 ) res = json.loads(json_str) res = json.loads(res) print (res) sub_images = res['sub_images' ] for item in sub_images: image_url = item['url' ] download_image(image_url) def download_image (url ): filename = mydir + '/' + url.split('/' )[-1 ] + '.jpg' print ('Downloading ...' + filename) response = requests.get(url,) print (response) with open (filename, 'wb' ) as f: f.write(response.content) if __name__ == '__main__' : mydir = 'download' pattern = 'gallery: JSON.parse\((.*?)\),' pat = re.compile (pattern) get_all_iamge()
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 import requestsimport reimport jsonimport osdef get_all_iamge (): if not os.path.exists(mydir): os.mkdir(mydir) url_list = [] url = 'https://www.toutiao.com/search_content/?offset={}&format=json&keyword=%E8%A1%97%E6%8B%8D&autoload=true&count=20&cur_tab=1&from=search_tab&pd=synthesis' for i in range (2 ): my_url = url.format (i * 20 ) url_list.append((my_url, get_detailed_page)) while url_list: (my_url, func) = url_list.pop(0 ) func(my_url, url_list) def get_detailed_page (url, url_list ): response = requests.get(url) res = response.json() data = res['data' ] for item in data: if 'article_url' in item: article_url = item['article_url' ] print (article_url) url_list.append((article_url, parse_detailed_page)) def parse_detailed_page (url, url_list ): headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36' } response = requests.get(url, headers=headers) res_match = pat.search(response.text) if res_match: json_str = res_match.group(1 ) res = json.loads(json_str) res = json.loads(res) sub_images = res['sub_images' ] for item in sub_images: image_url = item['url' ] url_list.append((image_url, download_image)) def download_image (url, url_list ): filename = mydir + '/' + url.split('/' )[-1 ] + '.jpg' print ('Downloading ...' + filename) response = requests.get(url) with open (filename, 'wb' ) as f: f.write(response.content) if __name__ == '__main__' : mydir = 'download' pattern = 'gallery: JSON.parse\\((.*?)\\),' pat = re.compile (pattern) get_all_iamge()
 wechat
wechat alipay
alipay



