
Kafka特性之一致性保证
概念
-
- ⽔位标记
⽔位或⽔印(watermark)⼀词,表示位置信息,即位移(offset)。Kafka源码中使⽤的名字是⾼⽔位,HW(high watermark)。
-
- 副本⻆⾊
Kafka分区使⽤多个副本(replica)提供⾼可⽤。
-
- LEO和HW
每个分区副本对象都有两个重要的属性:LEO和HW。
-
LEO:即⽇志末端位移(log end offset),记录了该副本⽇志中下⼀条消息的位移值。如果LEO=10,那么表示该副本保存了10条消息,位移值范围是[0, 9]。另外,Leader LEO和Follower LEO的更新是有区别的。
-
HW:即上⾯提到的⽔位值。对于同⼀个副本对象⽽⾔,其HW值不会⼤于LEO值。⼩于等于HW值的所有消息都被认为是“已备份”的(replicated)。Leader副本和Follower副本的HW更新不同。
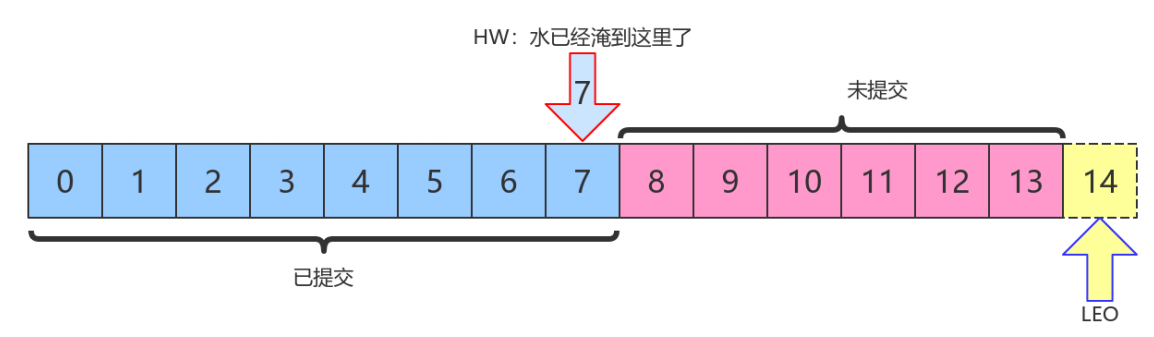
上图中,HW值是7,表示位移是 0~7 的所有消息都已经处于“已提交状态”(committed),⽽LEO值是14,8~13的消息就是未完全备份(fully replicated)——为什么没有14?LEO指向的是下⼀条消息到来时的位移。
消费者⽆法消费分区下Leader副本中位移⼤于分区HW的消息。
Follower副本何时更新LEO
Follower副本不停地向Leader副本所在的broker发送FETCH请求,⼀旦获取消息后写⼊⾃⼰的⽇志中进⾏备份。
那么Follower副本的LEO是何时更新的呢?⾸先我必须⾔明,Kafka有两套Follower副本LEO:
-
- ⼀套LEO保存在Follower副本所在Broker的副本管理机中;
-
- 另⼀套LEO保存在Leader副本所在Broker的副本管理机中。Leader副本机器上保存了所有的follower副本的LEO。
Kafka使⽤前者帮助Follower副本更新其HW值;利⽤后者帮助Leader副本更新其HW。
-
- Follower副本的本地LEO何时更新?
Follower副本的LEO值就是⽇志的LEO值,每当新写⼊⼀条消息,LEO值就会被更新。当Follower发送FETCH请求后,Leader将数据返回给Follower,此时Follower开始Log写数据,从⽽⾃动更新LEO值。
-
- Leader端Follower的LEO何时更新?
Leader端的Follower的LEO更新发⽣在Leader在处理Follower FETCH请求时。⼀旦Leader接收到Follower发送的FETCH请求,它先从Log中读取相应的数据,给Follower返回数据前,先更新Follower的LEO。
Follower副本何时更新HW
Follower更新HW发⽣在其更新LEO之后,⼀旦Follower向Log写完数据,尝试更新⾃⼰的HW值。
⽐较当前LEO值与FETCH响应中Leader的HW值,取两者的⼩者作为新的HW值。
即:如果Follower的LEO⼤于Leader的HW,Follower HW值不会⼤于Leader的HW值。
Leader副本何时更新LEO
和Follower更新LEO相同,Leader写Log时⾃动更新⾃⼰的LEO值。
Leader副本何时更新HW值
Leader的HW值就是分区HW值,直接影响分区数据对消费者的可⻅性。
Leader会尝试去更新分区HW的四种情况:
-
Follower副本成为Leader副本时:Kafka会尝试去更新分区HW。
-
Broker崩溃导致副本被踢出ISR时:检查下分区HW值是否需要更新是有必要的。
-
⽣产者向Leader副本写消息时:因为写⼊消息会更新Leader的LEO,有必要检查HW值是否需要更新。
-
Leader处理Follower FETCH请求时:⾸先从Log读取数据,之后尝试更新分区HW值。
结论:
当Kafka broker都正常⼯作时,分区HW值的更新时机有两个:
-
Leader处理PRODUCE请求时
-
Leader处理FETCH请求时。
Leader如何更新⾃⼰的HW值?
Leader broker上保存了⼀套Follower副本的LEO以及⾃⼰的LEO。当尝试确定分区HW时,它会选出所有满⾜条件的副本,⽐较它们的LEO(包括Leader的LEO),并选择最⼩的LEO值作为HW值。
需要满⾜的条件,(⼆选⼀):
-
处于ISR中
-
副本LEO落后于Leader LEO的时⻓不⼤于 replica.lag.time.max.ms 参数值(默认是10s)
如果Kafka只判断第⼀个条件的话,确定分区HW值时就不会考虑这些未在ISR中的副本,但这些副本已经具备了 “⽴刻进⼊ISR”的资格,因此就可能出现分区HW值越过ISR中副本LEO的情况——不允许。因为分区HW定义就是ISR中所有副本LEO的最⼩值。
HW和LEO正常更新案例
我们假设有⼀个topic,单分区,副本因⼦是2,即⼀个Leader副本和⼀个Follower副本。我们看下当producer发送⼀条消息时,broker端的副本到底会发⽣什么事情以及分区HW是如何被更新的。
-
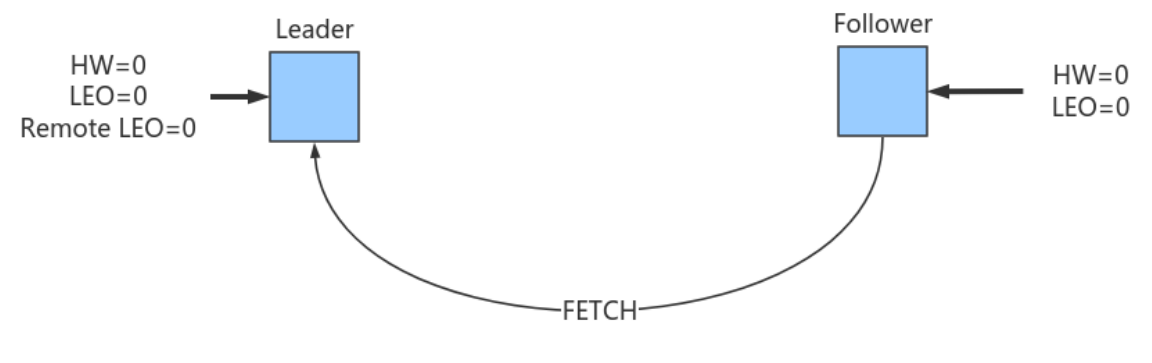
- 初始状态
初始时Leader和Follower的HW和LEO都是0(严格来说源代码会初始化LEO为-1,不过这不影响之后的讨论)。Leader中的Remote LEO指的就是Leader端保存的Follower LEO,也被初始化成0。此时,⽣产者没有发送任何消息给Leader,⽽Follower已经开始不断地给Leader发送FETCH请求了,但因为没有数据因此什么都不会发⽣。值得⼀提的是,Follower发送过来的FETCH请求因为⽆数据⽽暂时会被寄存到Leader端的purgatory中,待500ms( replica.fetch.wait.max.ms 参数)超时后会强制完成。倘若在寄存期间⽣产者发来数据,则Kafka会⾃动唤醒该FETCH请求,让Leader继续处理。
-
- Follower发送FETCH请求在Leader处理完PRODUCE请求之后
producer给该topic分区发送了⼀条消息,此时的状态如下图所示:
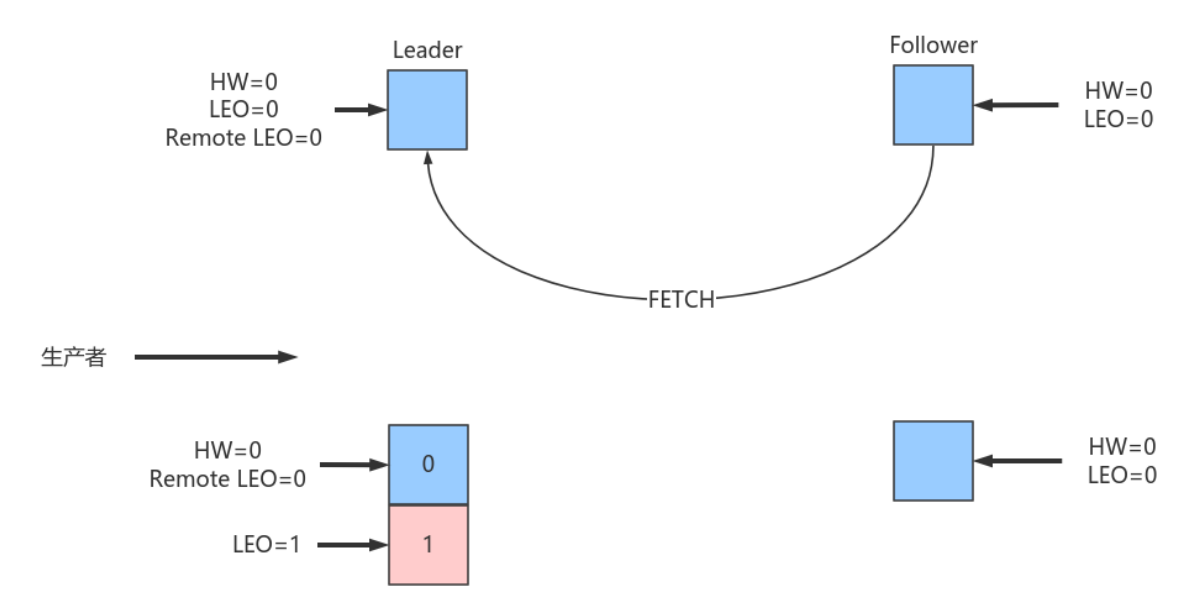
如上图所示,Leader接收到PRODUCE请求主要做两件事情:
-
把消息写⼊Log,同时⾃动更新Leader⾃⼰的LEO
-
尝试更新Leader HW值。假设此时Follower尚未发送FETCH请求,Leader端保存的Remote LEO依然是0,因此Leader会⽐较它⾃⼰的LEO值和Remote LEO值,发现最⼩值是0,与当前HW值相同,故不会更新分区HW值(仍为0)
PRODUCE请求处理完成后各值如下,Leader端的HW值依然是0,⽽LEO是1,Remote LEO也是0。
属性 阶段 旧值 新值 备注 Leader LEO PRODUCE处理完成 0 1 写⼊了⼀条数据 Remote LEO PRODUCE处理完成 0 0 还未Fetch Leader HW PRODUCE处理完成 0 0 min(LeaderLEO=1, RemoteLEO=0)=0 Follower LEO PRODUCE处理完成 0 0 还未Fetch Follower HW PRODUCE处理完成 0 0 min(LeaderHW=0, FollowerLEO=0)=0 -
- follower发送了FETCH请求
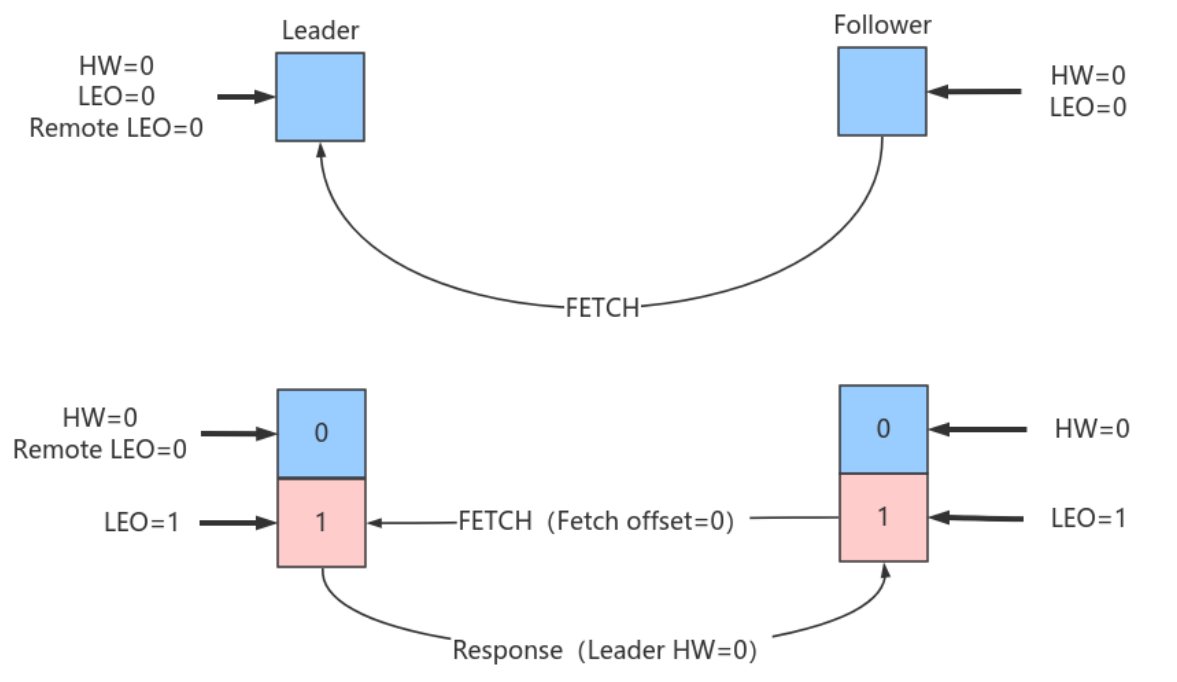
本例中当follower发送FETCH请求时,Leader端的处理依次是:
-
- 读取Log数据
-
- 更新remote LEO = 0(为什么是0? 因为此时Follower还没有写⼊这条消息。Leader如何确认Follower还未写⼊呢?这是通过Follower发来的FETCH请求中的Fetch offset来确定的)
-
- 尝试更新分区HW:此时Leader LEO = 1,Remote LEO = 0,故分区HW值= min(Leader LEO, Follower Remote LEO) = 0
-
- 把数据和当前分区HW值(依然是0)发送给Follower副本⽽Follower副本接收到FETCH Response后依次执⾏下列操作:
-
- 写⼊本地Log,同时更新Follower⾃⼰管理的 LEO为1
-
- 更新Follower HW:⽐较本地LEO和 FETCH Response 中的当前Leader HW值,取较⼩者,Follower HW = 0
此时,第⼀轮FETCH RPC结束,我们会发现虽然Leader和Follower都已经在Log中保存了这条消息,但分区HW值尚未被更新,仍为0。
属性 阶段 旧值 新值 备注 Leader LEO PRODUCE和Follower FETCH处理完成 0 1 写⼊了⼀条数据 Remote LEO PRODUCE和Follower FETCH处理完成 0 0 第⼀次fetch中offset为0 Leader HW PRODUCE和Follower FETCH处理完成 0 0 min(LeaderLEO=1,RemoteLEO=0)=0 Follower LEO PRODUCE和Follower FETCH处理完成 0 1 同步了⼀条数据 Follower HW PRODUCE和Follower FETCH处理完成 0 0 min(LeaderHW=0,FollowerLEO=1)=0 -
Follower第⼆轮FETCH
分区HW是在第⼆轮FETCH RPC中被更新的,如下图所示:

Follower发来了第⼆轮FETCH请求,Leader端接收到后仍然会依次执⾏下列操作:
-
读取Log数据
-
更新Remote LEO = 1(这次为什么是1了? 因为这轮FETCH RPC携带的fetch offset是1,那么为什么这轮携带的就是1了呢,因为上⼀轮结束后Follower LEO被更新为1了)
-
尝试更新分区HW:此时leader LEO = 1,Remote LEO = 1,故分区HW值= min(Leader LEO, Follower Remote LEO) = 1。
-
把数据(实际上没有数据)和当前分区HW值(已更新为1)发送给Follower副本作为Response
同样地,Follower副本接收到FETCH response后依次执⾏下列操作:
-
写⼊本地Log,当然没东⻄可写,Follower LEO也不会变化,依然是1。
-
更新Follower HW:⽐较本地LEO和当前LeaderHW取⼩者。由于都是1,故更新follower HW = 1 。
属性 阶段 旧值 新值 备注 Leader LEO 第⼆次Follower FETCH处理完成 1 1 未写⼊新数据 Remote LEO 第⼆次Follower FETCH处理完成 0 1 第2次fetch中offset为1 Leader HW 第⼆次Follower FETCH处理完成 0 1 min(RemoteLEO,LeaderLEO)=1 Follower LEO 第⼆次Follower FETCH处理完成 1 1 未写⼊新数据 Follower HW 第⼆次Follower FETCH处理完成 0 1 第2次fetch resp中的LeaderHW和本地FollowerLEO都是1 此时消息已经成功地被复制到Leader和Follower的Log中且分区HW是1,表明消费者能够消费offset = 0的消息。
-
-
- FETCH请求保存在purgatory中,PRODUCE请求到来。
当Leader⽆法⽴即满⾜FECTH返回要求的时候(⽐如没有数据),那么该FETCH请求被暂存到Leader端的purgatory中(炼狱),待时机成熟尝试再次处理。Kafka不会⽆限期缓存,默认有个超时时间(500ms),⼀旦超时时间已过,则这个请求会被强制完成。当寄存期间还没超时,⽣产者发送PRODUCE请求从⽽使之满⾜了条件以致被唤醒。
此时,Leader端处理流程如下:
-
Leader写Log(⾃动更新Leader LEO)
-
尝试唤醒在purgatory中寄存的FETCH请求
-
尝试更新分区HW
HW和LEO异常案例
Kafka使⽤HW值来决定副本备份的进度,⽽HW值的更新通常需要额外⼀轮FETCH RPC才能完成。但这种设计是有问题的,可能引起的问题包括:
-
备份数据丢失
-
备份数据不⼀致
-
- 数据丢失
使⽤HW值来确定备份进度时其值的更新是在下⼀轮RPC中完成的。如果Follower副本在标记上⽅的的第⼀步与第⼆步之间发⽣崩溃,那么就有可能造成数据的丢失。
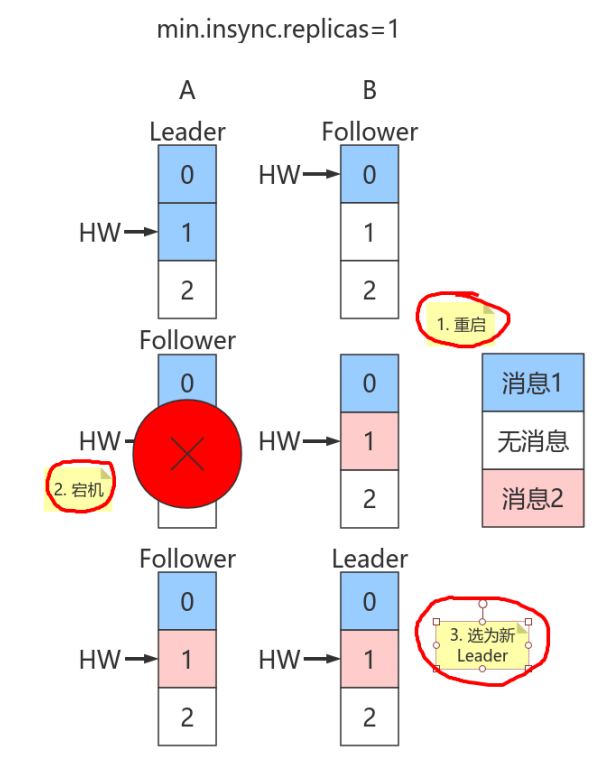
上图中有两个副本:A和B。开始状态是A是Leader。
假设⽣产者 min.insync.replicas 为1,那么当⽣产者发送两条消息给A后,A写⼊Log,此时Kafka会通知⽣产者这两条消息写⼊成功。
属性 阶段 旧值 新值 备注 Leader LEO PRODUCE和Follower FETCH处理完成 0 1 写⼊了⼀条数据 Remote LEO PRODUCE和Follower FETCH处理完成 0 0 第⼀次fetch中offset为0 Leader HW PRODUCE和Follower FETCH处理完成 0 0 min(LeaderLEO=1,FollowerLEO=0)=0 Follower LEO PRODUCE和Follower FETCH处理完成 0 1 同步了⼀条数据 Follower HW PRODUCE和Follower FETCH处理完成 0 0 min(LeaderHW=0, FollowerLEO=1)=0 Leader LEO 第⼆次Follower FETCH处理完成 1 2 写⼊了第⼆条数据 Remote LEO 第⼆次Follower FETCH处理完成 0 1 第2次fetch中offset为1 Leader HW 第⼆次Follower FETCH处理完成 0 1 min(RemoteLEO=1,LeaderLEO=2)=1 Follower LEO 第⼆次Follower FETCH处理完成 1 2 写⼊了第⼆条数据 Follower HW 第⼆次Follower FETCH处理完成 0 1 min(LeaderHW=1,FollowerLEO=2)=1 Leader LEO 第三次Follower FETCH处理完成 2 2 未写⼊新数据 Remote LEO 第三次Follower FETCH处理完成 1 2 第3次fetch中offset为2 Leader HW 第三次Follower FETCH处理完成 1 2 min(RemoteLEO=2,LeaderLEO)=2 Follower LEO 第三次Follower FETCH处理完成 2 2 未写⼊新数据 Follower HW 第三次Follower FETCH处理完成 1 2 第3次fetch resp中的LeaderHW和本地FollowerLEO都是2 但是在broker端,Leader和Follower的Log虽都写⼊了2条消息且分区HW已经被更新到2,但Follower HW尚未被更新还是1,也就是上⾯标记的第⼆步尚未执⾏,表中最后⼀条未执⾏。
倘若此时副本B所在的broker宕机,那么重启后B会⾃动把LEO调整到之前的HW值1,故副本B会做⽇志截断(log truncation),将offset = 1的那条消息从log中删除,并调整LEO = 1。此时follower副本底层log中就只有⼀条消息,即offset = 0的消息!
B重启之后需要给A发FETCH请求,但若A所在broker机器在此时宕机,那么Kafka会令B成为新的Leader,⽽当A重启回来后也会执⾏⽇志截断,将HW调整回1。这样,offset=1的消息就从两个副本的log中被删除,也就是说这条已经被⽣产者认为发送成功的数据丢失。
丢失数据的前提是 min.insync.replicas=1 时,⼀旦消息被写⼊Leader端Log即被认为是 committed 。延迟⼀轮 FETCH RPC 更新HW值的设计使follower HW值是异步延迟更新,若在这个过程中Leader发⽣变更,那么成为新Leader的Follower的HW值就有可能是过期的,导致⽣产者本是成功提交的消息被删除。
-
- Leader和Follower数据离散
除了可能造成的数据丢失以外,该设计还会造成Leader的Log和Follower的Log数据不⼀致。
如Leader端记录序列:m1,m2,m3,m4,m5,…;Follower端序列可能是m1,m3,m4,m5,…。
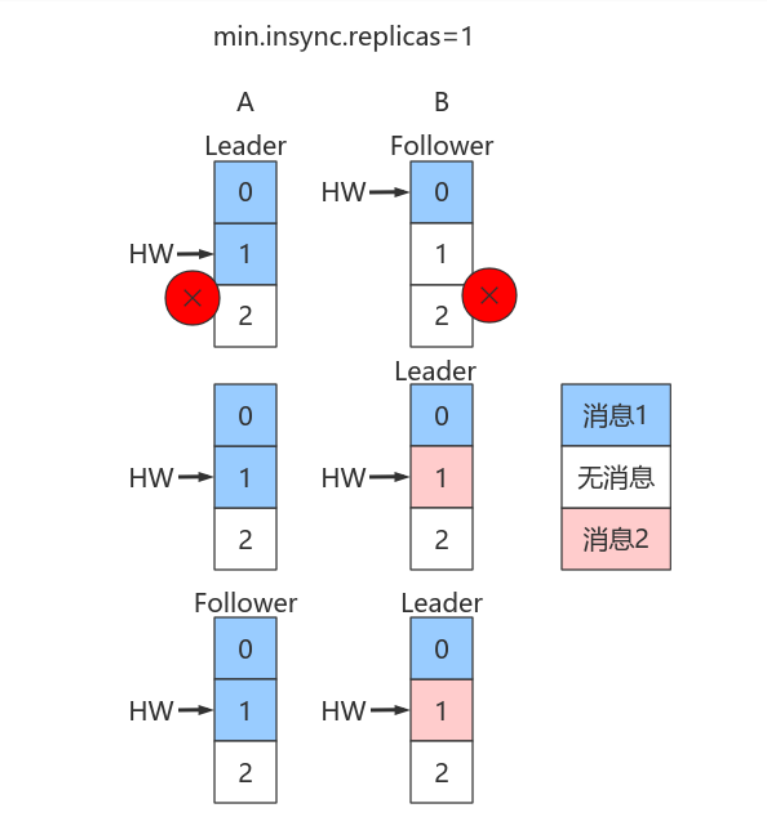
假设:A是Leader,A的Log写⼊了2条消息,但B的Log只写了1条消息。分区HW更新到2,但B的HW还是1,同时⽣产者 min.insync.replicas 仍然为1。
假设A和B所在Broker同时宕机,B先重启回来,因此B成为Leader,分区HW = 1。假设此时⽣产者发送了第3条消息(红⾊表示)给B,于是B的log中offset = 1的消息变成了红框表示的消息,同时分区HW更新到2(A还没有回来,就B⼀个副本,故可以直接更新HW⽽不⽤理会A)之后A重启回来,需要执⾏⽇志截断,但发现此时分区HW=2⽽A之前的HW值也是2,故不做任何调整。此后A和B将以这种状态继续正常⼯作。
显然,这种场景下,A和B的Log中保存在offset = 1的消息是不同的记录,从⽽引发不⼀致的情形出现。
Leader Epoch使⽤
Kafka解决⽅案
造成上述两个问题的根本原因在于
-
HW值被⽤于衡量副本备份的成功与否。
-
在出现失败重启时作为⽇志截断的依据。
但HW值的更新是异步延迟的,特别是需要额外的FETCH请求处理流程才能更新,故这中间发⽣的任何崩溃都可能导致HW值的过期。
Kafka从0.11引⼊了 leader epoch 来取代HW值。Leader端使⽤内存保存Leader的epoch信息,即使出现上⾯的两个场景也能规避这些问题。
所谓Leader epoch实际上是⼀对值:<epoch, offset>:
-
epoch表示Leader的版本号,从0开始,Leader变更过1次,epoch+1
-
offset对应于该epoch版本的Leader写⼊第⼀条消息的offset。因此假设有两对值:
1 | <0, 0> |
则表示第⼀个Leader从位移0开始写⼊消息;共写了120条[0, 119];⽽第⼆个Leader版本号是1,从位移120处开始写⼊消息。
-
Leader broker中会保存这样的⼀个缓存,并定期地写⼊到⼀个 checkpoint ⽂件中。
-
当Leader写Log时它会尝试更新整个缓存:如果这个Leader⾸次写消息,则会在缓存中增加⼀个条⽬;否则就不做更新。
-
每次副本变为Leader时会查询这部分缓存,获取出对应Leader版本的位移,则不会发⽣数据不⼀致和丢失的情况。
规避数据丢失
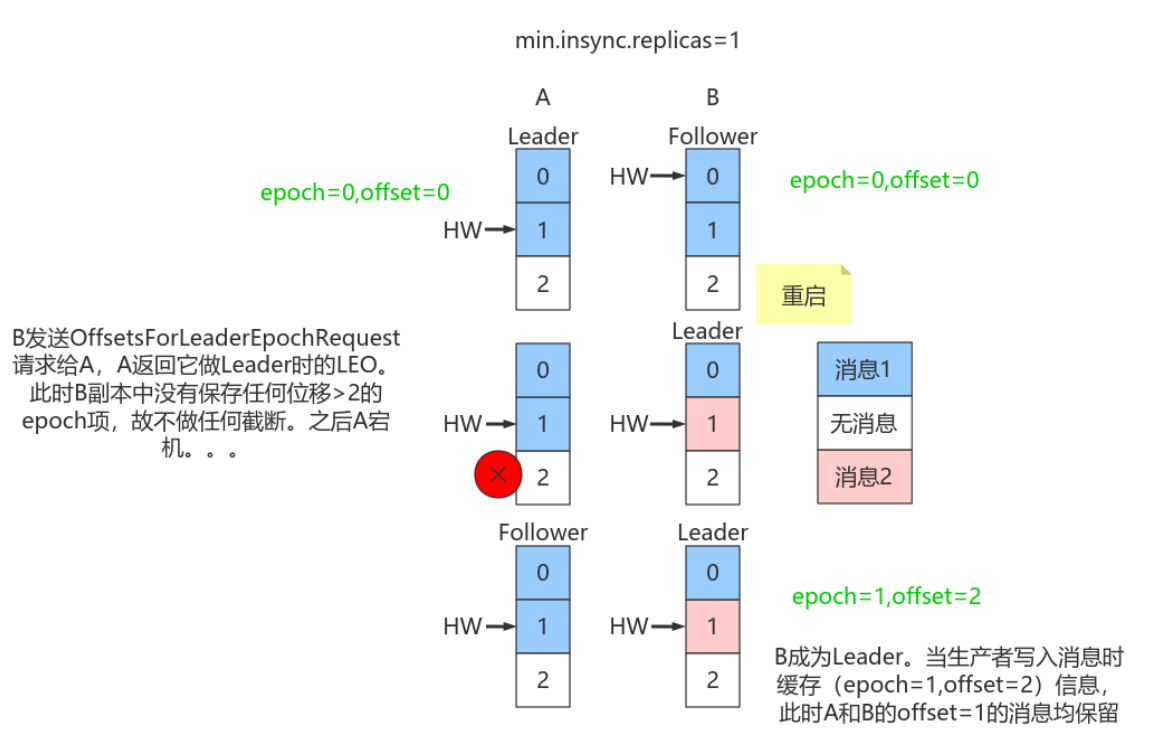
只需要知道每个副本都引⼊了新的状态来保存⾃⼰当leader时开始写⼊的第⼀条消息的offset以及leader版本。这样在恢复的时候完全使⽤这些信息⽽⾮HW来判断是否需要截断⽇志。
规避数据不⼀致
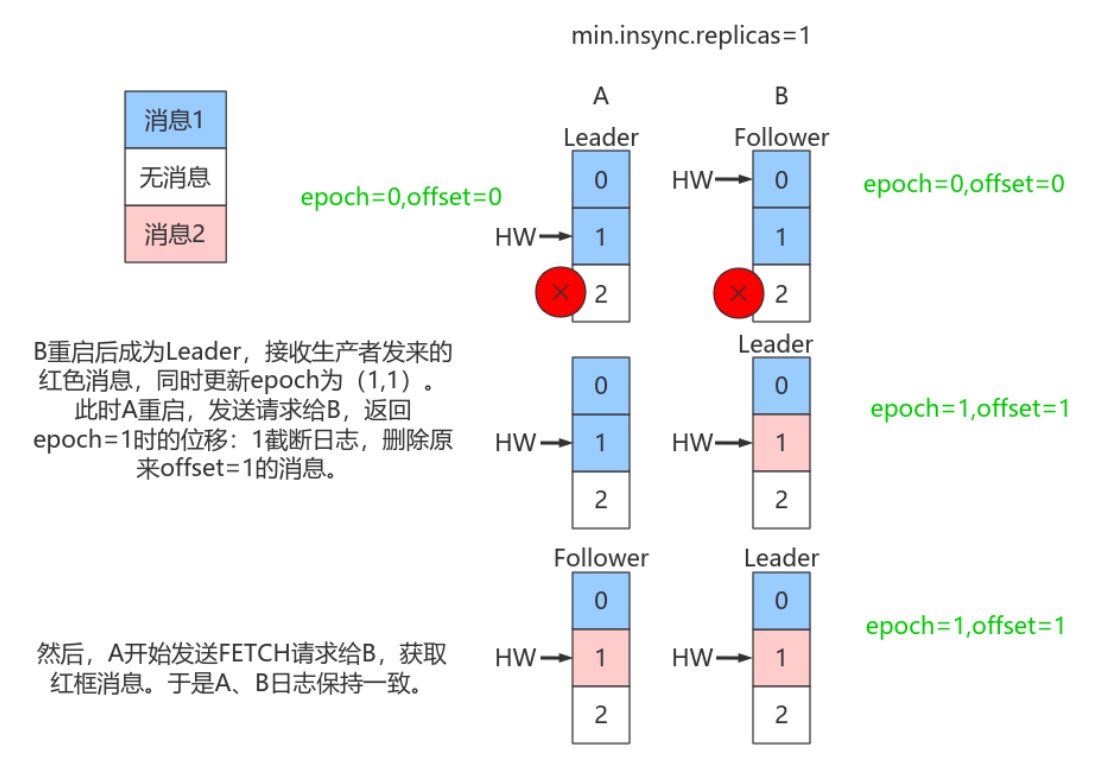
依靠Leader epoch的信息可以有效地规避数据不⼀致的问题。
 wechat
wechat alipay
alipay