MapReduce编程规范
Mapper类
用户自定义一个Mapper类继承Hadoop的Mapper类
Mapper的输入数据是KV对的形式(类型可以自定义)
Map阶段的业务逻辑定义在map()方法中
Mapper的输出数据是KV对的形式(类型可以自定义)
注意:map()方法是对输入的一个KV对调用一次!
Reducer类
用户自定义Reducer类要继承Hadoop的Reducer类
Reducer的输入数据类型对应Mapper的输出数据类型(KV对)
Reducer的业务逻辑写在reduce()方法中
注意:Reduce()方法是对相同K的一组KV对调用执行一次!
Driver阶段
创建提交YARN集群运行的Job对象,其中封装了MapReduce程序运行所需要的相关参数入输入数据路径,输出数据路径等,也相当于是一个YARN集群的客户端,主要作用就是提交我们MapReduce程序运行。
WordCount代码实现
需求
在给定的文本文件中统计输出每一个单词出现的总次数,如
输入文本文件数据:wc.txt;
輸出:
1 2 3 4 5 6 apache 2 clickhouse 2 hadoop 1 mapreduce 1 spark 2 xiaoming 1
具体步骤
新建maven工程wordcount,pom文件导入依赖。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 <dependencies> <!-- log4j 打印日志依赖--> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.8.2</version> </dependency> <!-- hadoop-common依赖,以下为maven远程仓库的所在地址,选择和安装的hadoop版本一致--> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.9.2</version> </dependency> <!-- hadoop-client依赖,以下为maven远程仓库的所在地址,选择和安装的hadoop版本一致--> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.9.2</version> </dependency> <!-- hadoop-hdfs依赖,以下为maven远程仓库的所在地址,选择和安装的hadoop版本一致--> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.9.2</version> </dependency> </dependencies> <!--maven打包插件 --> <build> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>2.3.2</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build>
src/main/resource下添加log4j.properties。内容如下。
1 2 3 4 5 6 7 8 log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=target/spring.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
编写Mapper类,名称为WordCountMapper。
map()方法中把传入的数据转为String类型
根据空格切分出单词
输出<单词,1>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 package com.lagou.mr.wc; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; //需求:单词计数 //1 继承Mapper类 //2 Mapper类的泛型参数:共4个,2对kv //2.1 第一对kv:map输入参数类型 //2.2 第二队kv:map输出参数类型 // LongWritable, Text-->文本偏移量(后面不会用到),一行文本内容 //Text, IntWritable-->单词,1 public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { //3 重写Mapper类的map方法 /* 1 接收到文本内容,转为String类型 2 按照空格进行切分 3 输出<单词,1> */ //提升为全局变量,避免每次执行map方法都执行此操作 final Text word = new Text(); final IntWritable one = new IntWritable(1); // LongWritable, Text-->文本偏移量,一行文本内容,map方法的输入参数,一行文本就调用一次map方法 @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 接收到文本内容,转为String类型 final String str = value.toString(); // 2 按照空格进行切分 final String[] words = str.split(" "); // 3 输出<单词,1> //遍历数据 for (String s : words) { word.set(s); context.write(word, one); } } }
WordCountMapper继承的Mapper类选择新版本API,如下图
编写Reducer类,名称为WordCountReducer。
汇总各个key(单词)的个数,遍历value数据进行累加
输出key的总数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 package com.lagou.mr.wc; import com.sun.org.apache.bcel.internal.generic.NEW; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; //继承的Reducer类有四个泛型参数,2对kv //第一对kv:类型要与Mapper输出类型一致:Text, IntWritable //第二队kv:自己设计决定输出的结果数据是什么类型:Text, IntWritable public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { IntWritable total = new IntWritable(); //1 重写reduce方法 //Text key:map方法输出的key,本案例中就是单词, // Iterable<IntWritable> values:一组key相同的kv的value组成的集合 /* 假设map方法:hello 1;hello 1;hello 1 reduce的key和value是什么? key:hello, values:<1,1,1> 假设map方法输出:hello 1;hello 1;hello 1,hadoop 1, mapreduce 1,hadoop 1 reduce的key和value是什么? reduce方法何时调用:一组key相同的kv中的value组成集合然后调用一次reduce方法 第一次:key:hello ,values:<1,1,1> 第二次:key:hadoop ,values<1,1> 第三次:key:mapreduce ,values<1> */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { //2 遍历key对应的values,然后累加结果 int sum = 0; for (IntWritable value : values) { int i = value.get(); sum += 1; } // 3 直接输出当前key对应的sum值,结果就是单词出现的总次数 total.set(sum); context.write(key, total); } }
WordCountReducer继承的Reducer类选择新版本API,如下图
编写Driver驱动类,名称为WordCountDriver。
获取配置文件对象,获取job对象实例
指定程序jar的本地路径
指定Mapper/Reducer类 4. 指定Mapper输出的kv数据类型
指定最终输出的kv数据类型
指定job处理的原始数据路径
指定job输出结果路径
提交作业
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 package com.lagou.mr.wc; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.CombineTextInputFormat; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; //封装任务并提交运行 public class WordCountDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { /* 1. 获取配置文件对象,获取job对象实例 2. 指定程序jar的本地路径 3. 指定Mapper/Reducer类 4. 指定Mapper输出的kv数据类型 5. 指定最终输出的kv数据类型 6. 指定job处理的原始数据路径 7. 指定job输出结果路径 8. 提交作业 */ //1. 获取配置文件对象,获取job对象实例 final Configuration conf = new Configuration(); //针对reduce端输出使用snappy压缩 //conf.set("mapreduce.output.fileoutputformat.compress", "true"); //conf.set("mapreduce.output.fileoutputformat.compress.type", "RECORD"); //conf.set("mapreduce.output.fileoutputformat.compress.codec", "org.apache.hadoop.io.compress.SnappyCodec"); final Job job = Job.getInstance(conf, "WordCountDriver"); //2. 指定程序jar的本地路径 job.setJarByClass(WordCountDriver.class); //3. 指定Mapper/Reducer类 job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); //4. 指定Mapper输出的kv数据类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //5. 指定最终输出的kv数据类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //6. 指定job读取数据路径 FileInputFormat.setInputPaths(job, new Path(args[0])); //指定读取数据的原始路径 //7. 指定job输出结果路径 FileOutputFormat.setOutputPath(job, new Path(args[1])); //指定结果数据输出路径 //8. 提交作业 final boolean flag = job.waitForCompletion(true); //jvm退出:正常退出0,非0值则是错误退出 System.exit(flag ? 0 : 1); } }
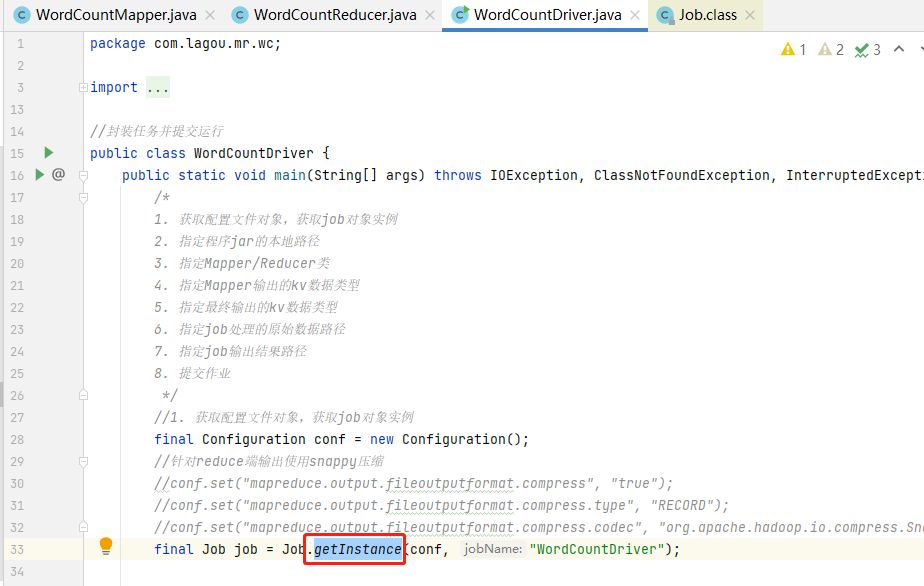
Ctrl+鼠标左点击,查看Job的getInstance方法源码。
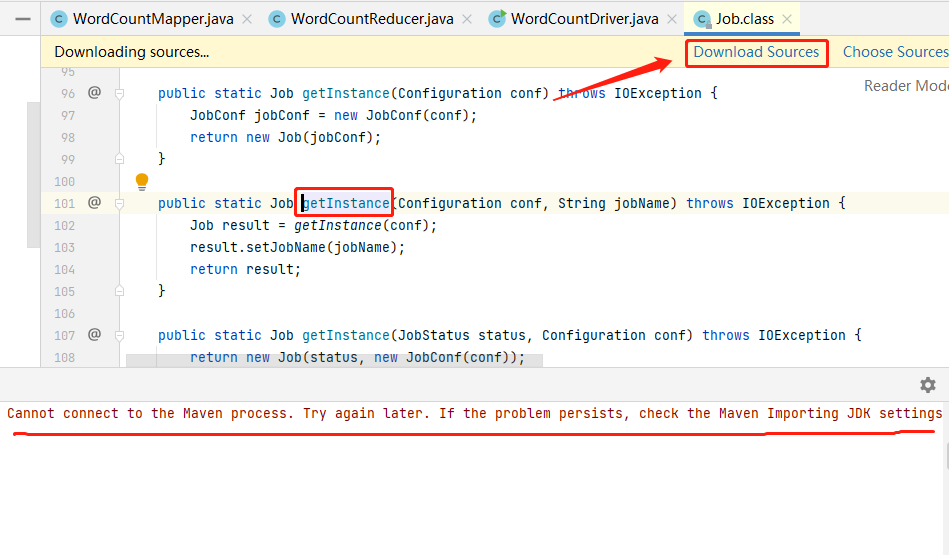
若未显示源码,可以点击Download Sources下载源码,然而会报错,原因是Hadoop2.8以后maven仓库没有对应的源码。
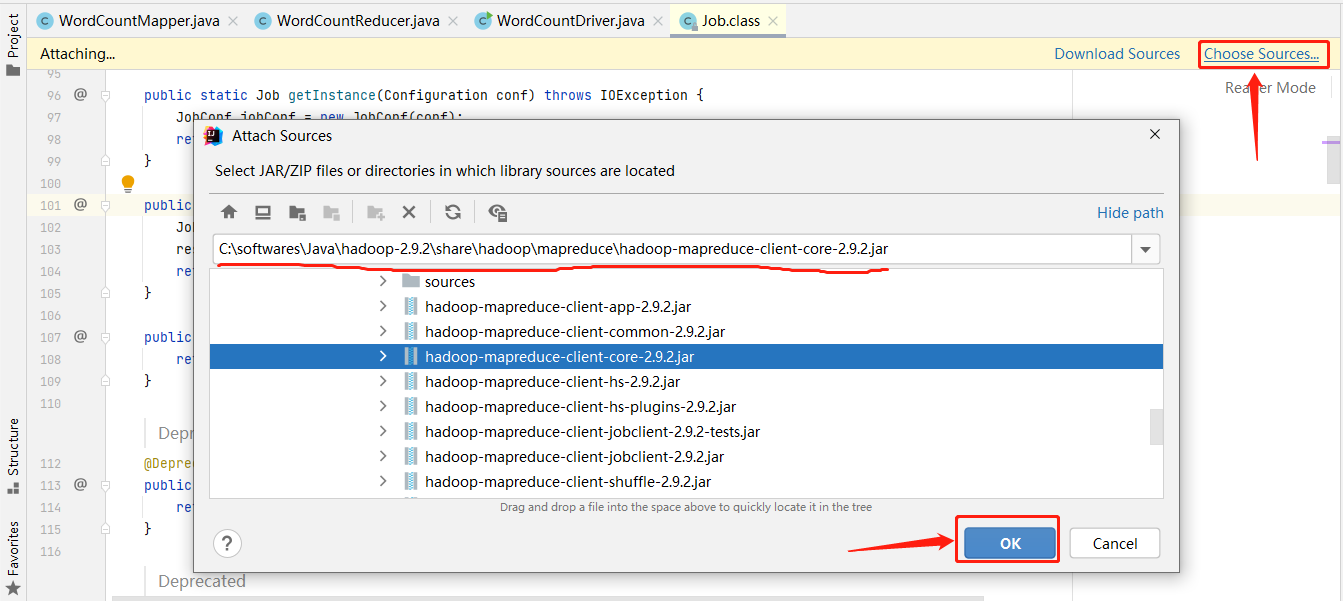
所以可以点击Choose Sources选择安装的Hadoop的源码。
运行任务
在E盘下创建wc.txt文件和output文件夹,并在wc.txt文件中输入测试的单词,以空格隔开可以换行,但每行末尾必须无空格。
本地模式
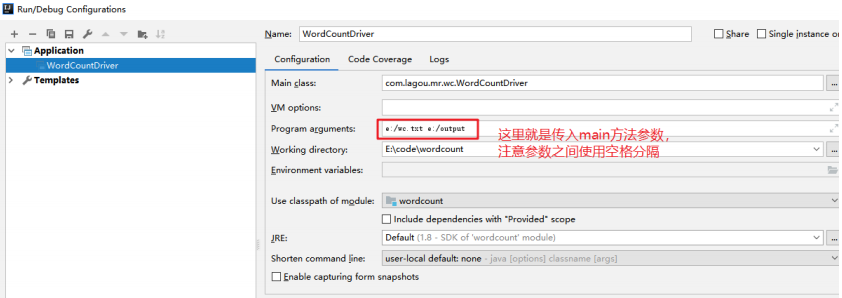
直接main方法启动,会报越界异常,此时需要对main方法的String[] args输入参数。
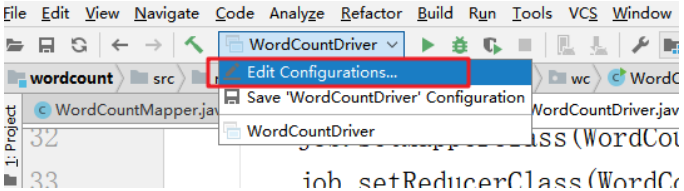
下拉,选择选择editconfiguration。
在program arguments设置输入参数e:/wc.txt e:/output。
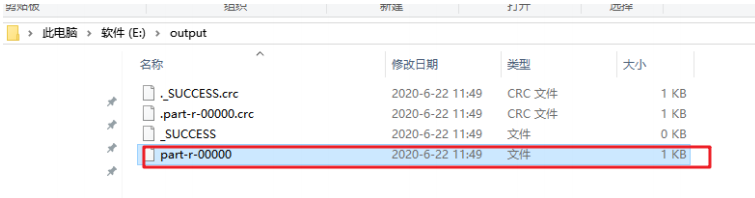
运行结束,去到输出结果路径查看结果。
注意本地idea运行mr任务与集群没有任何关系,没有提交任务到yarn集群,是在本地使用多线程方式模拟的mr的运行。
Yarn集群模式
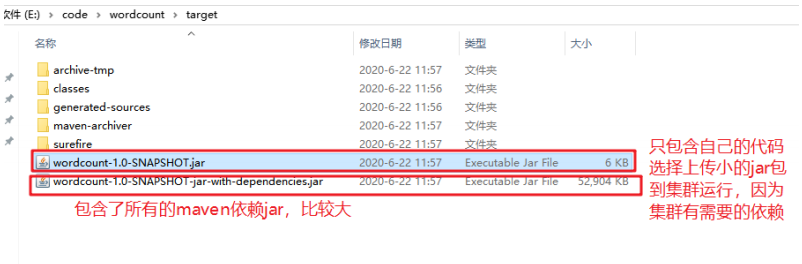
把程序打成jar包,选择合适的jar包,改名为wc.jar;上传到Hadoop集群。
准备原始数据文件,上传到HDFS的路径,不能是本地路径,因为跨节点运行无法获取数据!
启动Hadoop集群(Hdfs,Yarn)。
使用Hadoop 命令提交任务运行。
1 hadoop jar wc.jar com.lagou.wordcount.WordcountDriver /user/lagou/input /user/lagou/output
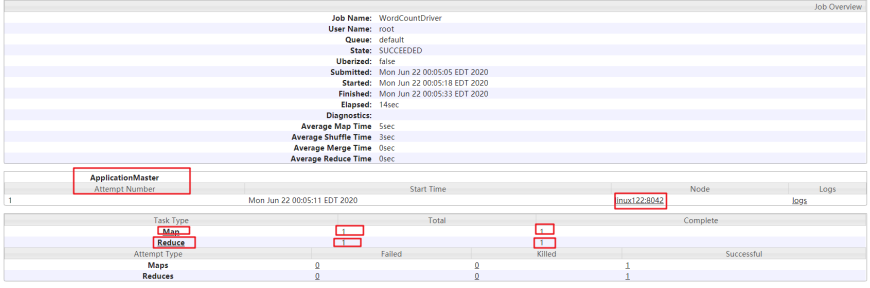
浏览器输入linux123:8088,查看Yarn集群任务运行成功展示图。



 wechat
wechat alipay
alipay


