
Hive-HQL之窗口函数
窗口函数又名开窗函数,属于分析函数的一种。用于解决复杂报表统计需求的功能强大的函数,很多场景都需要用到。
窗口函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是:对于每个组返回多行,而聚合函数对于每个组只返回一行。
窗口函数指定了分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化。
over 关键字
使用窗口函数之前一般要要通过over()进行开窗
1 | -- 查询emp表工资总和 |
注意:窗口函数是针对每一行数据的;如果over中没有参数,默认的是全部结果集;
partition by子句
在over窗口中进行分区,对某一列进行分区统计,窗口的大小就是分区的大小
1 | -- 查询员工姓名、薪水、部门薪水总和 |
order by 子句
order by 子句对输入的数据进行排序
1 | -- 增加了order by子句;sum:从分组的第一行到当前行求和 |
Window子句
1 | rows between ... and ... |
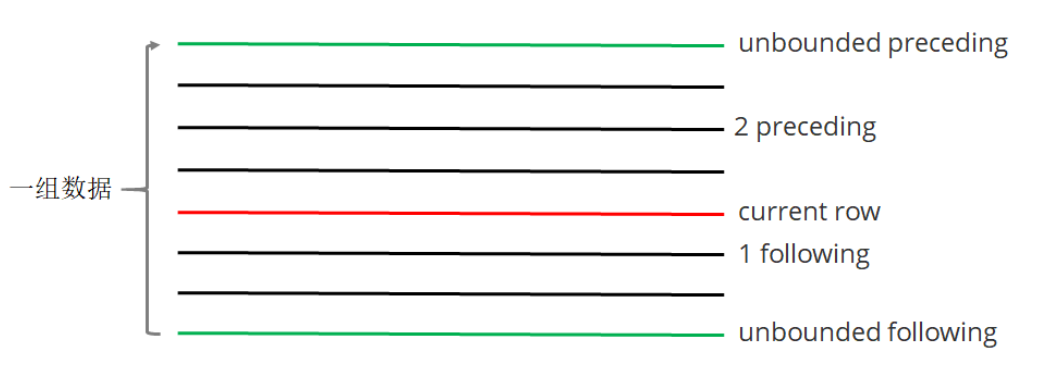
如果要对窗口的结果做更细粒度的划分,使用window子句,有如下的几个选项:
-
unbounded preceding。组内第一行数据
-
n preceding。组内当前行的前n行数据
-
current row。当前行数据
-
n following。组内当前行的后n行数据
-
unbounded following。组内最后一行数据
1 | -- rows between ... and ... 子句 |
排名函数
都是从1开始,生成数据项在分组中的排名。
-
row_number()。排名顺序增加不会重复;如1、2、3、4、… …
-
RANK()。 排名相等会在名次中留下空位;如1、2、2、4、5、… …
-
DENSE_RANK()。 排名相等会在名次中不会留下空位 ;如1、2、2、3、4、… …
1 | -- row_number / rank / dense_rank |
1 | -- 数据准备 |
序列函数
-
lag。返回当前数据行的上一行数据
-
lead。返回当前数据行的下一行数据
-
first_value。取分组内排序后,截止到当前行,第一个值
-
last_value。分组内排序后,截止到当前行,最后一个值
-
ntile。将分组的数据按照顺序切分成n片,返回当前切片值
1 | -- 测试数据 userpv.dat。cid ctime pv |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 WeiJia_Rao!
 wechat
wechat alipay
alipay




