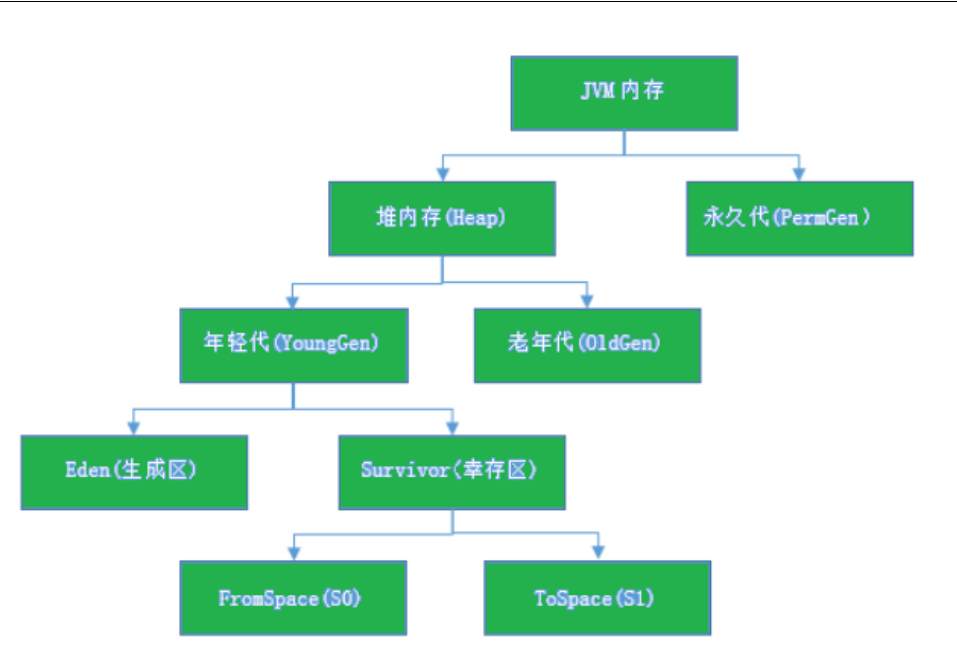
JVM堆内存
-
JVM内存划分为堆内存和非堆内存,堆内存分为年轻代(Young Generation)、老年代(Old Generation),非堆内存就一个永久代(Permanent Generation)。
-
年轻代又分为Eden和Survivor区。Survivor区由FromSpace和ToSpace组成。Eden区占大容量,Survivor两个区占小容量,默认比例是8:1:1。
-
堆内存用途:存放的是对象,垃圾收集器就是收集这些对象,然后根据GC算法回收。
-
非堆内存用途:永久代,也称为方法区,存储程序运行时长期存活的对象,比如类的元数据、方法、常量、属性等。
补充:JDK1.8版本废弃了永久代,替代的是元空间(MetaSpace),元空间与永久代上类似,都是方法区的实现,他们最大区别是:元空间并不在JVM中,而是使用本地内存。
对象分代
-
新生成的对象首先放到年轻代Eden区
-
当Eden空间满了,触发Minor GC,存活下来的对象移动到Survivor0区
-
Survivor0区满后触发执行Minor GC,Survivor0区存活对象移动到Suvivor1区,这样保证了一段时间内总有一个survivor区为空
-
经过多次Minor GC仍然存活的对象移动到老年代
-
老年代存储长期存活的对象,占满时会触发Major GC(Full GC),GC期间会停止所有线程等待GC完成,所以对响应要求高的应用尽量减少发生Major GC,避免响应超时
Minor GC : 清理年轻代
Major GC(Full GC) : 清理老年代,清理整个堆空间,会停止应用所有线程。
Jstat
虚拟机或服务器查看当前jvm内存使用以及垃圾回收情况
1
2
3
4
5
6
7
8
9
| jps 查看namenode的pid
7281 DataNode
7811 SecondaryNameNode
7219 ResourceManager
14554 Jps
7438 NodeManager
11647 JobHistoryServer
jstat -gc -t 7438 1s #显示pid是58563的垃圾回收堆的行为统计
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
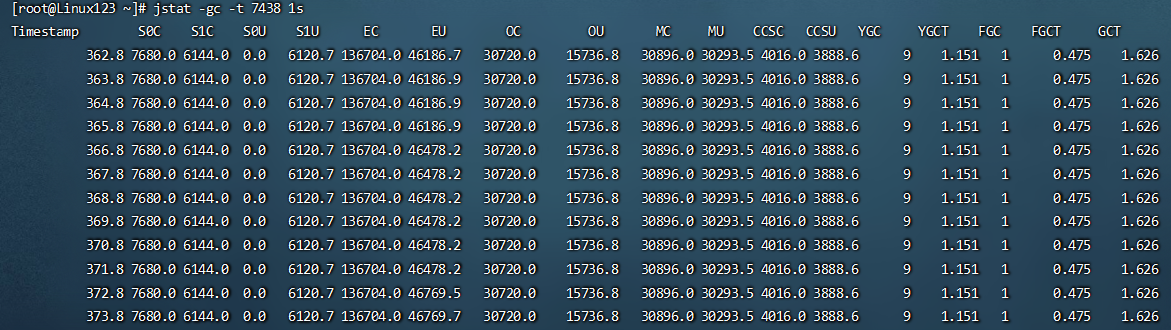
| #C即Capacity 总容量,U即Used 已使用的容量
S0C: 当前survivor0区容量(kB)
S1C: 当前survivor1区容量(kB)
S0U: survivor0区已使用的容量(KB)
S1U: survivor1区已使用的容量(KB)
EC: Eden区的总容量(KB)
EU: 当前Eden区已使用的容量(KB)
OC: Old空间容量(kB)。
OU: Old区已使用的容量(KB)
MC: Metaspace空间容量(KB)
MU: Metacspace使用量(KB)
CCSC: 压缩类空间容量(kB)
CCSU: 压缩类空间使用(kB)
YGC: 新生代垃圾回收次数
YGCT: 新生代垃圾回收时间
FGC: 老年代full GC垃圾回收次数
FGCT: 老年代垃圾回收时间
GCT: 垃圾回收总消耗时间
|
HDFS-GC详细日志输出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| #日志输出文件地址
export HADOOP_LOG_DIR=/hadoop/logs/
#JMX配置
export HADOOP_JMX_OPTS="-Dcom.sun.management.jmxremote.authenticate=false - Dcom.sun.management.jmxremote.ssl=false"
export HADOOP_NAMENODE_OPTS="-Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:- INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
export HADOOP_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS $HADOOP_DATANODE_OPTS"
export NAMENODE_OPTS="-verbose:gc -XX:+PrintGCDetails - Xloggc:${HADOOP_LOG_DIR}/logs/hadoop-gc.log \ -XX:+PrintGCDateStamps -XX:+PrintGCApplicationConcurrentTime - XX:+PrintGCApplicationStoppedTime \ -server -Xms150g -Xmx150g -Xmn20g -XX:SurvivorRatio=8 - XX:MaxTenuringThreshold=15 \ -XX:ParallelGCThreads=18 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC - XX:+UseCMSCompactAtFullCollection -XX:+DisableExplicitGC - XX:+CMSParallelRemarkEnabled \ -XX:+CMSClassUnloadingEnabled -XX:CMSInitiatingOccupancyFraction=70 - XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly - XX:CMSMaxAbortablePrecleanTime=5000 \ -XX:+UseGCLogFileRotation -XX:GCLogFileSize=20m - XX:ErrorFile=${HADOOP_LOG_DIR}/logs/hs_err.log.%p - XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${HADOOP_LOG_DIR}/logs/%p.hprof \"
export DATENODE_OPTS="-verbose:gc -XX:+PrintGCDetails - Xloggc:${HADOOP_LOG_DIR}/hadoop-gc.log \ -XX:+PrintGCDateStamps -XX:+PrintGCApplicationConcurrentTime - XX:+PrintGCApplicationStoppedTime \ -server -Xms15g -Xmx15g -Xmn4g -XX:SurvivorRatio=8 -XX:MaxTenuringThreshold=15 \-XX:ParallelGCThreads=18 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC - XX:+UseCMSCompactAtFullCollection -XX:+DisableExplicitGC - XX:+CMSParallelRemarkEnabled \ -XX:+CMSClassUnloadingEnabled -XX:CMSInitiatingOccupancyFraction=70 - XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly - XX:CMSMaxAbortablePrecleanTime=5000 \ -XX:+UseGCLogFileRotation -XX:GCLogFileSize=20m - XX:ErrorFile=${HADOOP_LOG_DIR}/logs/hs_err.log.%p - XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=${HADOOP_LOG_DIR}/logs/%p.hprof \"
export HADOOP_NAMENODE_OPTS="$NAMENODE_OPTS $HADOOP_NAMENODE_OPTS"
export HADOOP_DATANODE_OPTS="$DATENODE_OPTS $HADOOP_DATANODE_OPTS"
|
1
2
3
4
5
6
7
8
| -Xms150g -Xmx150g :堆内存大小最大和最小都是150g
-Xmn20g :新生代大小为20g,等于eden+2*survivor,意味着老年代为150-20=130g。
-XX:SurvivorRatio=8 :Eden和Survivor的大小比值为8,意味着两个Survivor区和一个Eden区的比值为2:8,一个Survivor占整个年轻代的1/10
-XX:ParallelGCThreads=10 :设置ParNew GC的线程并行数,默认为 8 + (Runtime.availableProcessors - 8) * 5/8 ,24核机器为18。
-XX:MaxTenuringThreshold=15 :设置对象在年轻代的最大年龄,超过这个年龄则会晋升到老年代
-XX:+UseParNewGC :设置新生代使用Parallel New GC
-XX:+UseConcMarkSweepGC :设置老年代使用CMS GC,当此项设置时候自动设置新生代为ParNew GC
-XX:CMSInitiatingOccupancyFraction=70 :老年代第一次占用达到该百分比时候,就会引发CMS的第一次垃圾回收周期。后继CMS GC由HotSpot自动优化计算得到。
|
GC日志解析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| 3.157: [GC (Allocation Failure) 3.157: [ParNew: 272640K->34048K(306688K), 0.0844702 secs] 272640K->69574K(2063104K), 0.0845560 secs] [Times: user=0.23 sys=0.03, real=0.09 secs]
4.092: [GC (Allocation Failure) 4.092: [ParNew: 306688K->34048K(306688K), 0.1013723 secs] 342214K->136584K(2063104K), 0.1014307 secs] [Times: user=0.25 sys=0.05, real=0.10 secs]
... cut for brevity ...
11.292: [GC (Allocation Failure) 11.292: [ParNew: 306686K->34048K(306688K), 0.0857219 secs] 971599K->779148K(2063104K), 0.0857875 secs] [Times: user=0.26 sys=0.04, real=0.09 secs]
12.140: [GC (Allocation Failure) 12.140: [ParNew: 306688K->34046K(306688K), 0.0821774 secs] 1051788K->856120K(2063104K), 0.0822400 secs] [Times: user=0.25 sys=0.03, real=0.08 secs]
12.989: [GC (Allocation Failure) 12.989: [ParNew: 306686K->34048K(306688K), 0.1086667 secs] 1128760K->931412K(2063104K), 0.1087416 secs] [Times: user=0.24 sys=0.04, real=0.11 secs]
13.098: [GC (CMS Initial Mark) [1 CMS-initial-mark: 897364K(1756416K)] 936667K(2063104K), 0.0041705 secs] [Times: user=0.02 sys=0.00, real=0.00 secs]
13.102: [CMS-concurrent-mark-start] 13.341: [CMS-concurrent-mark: 0.238/0.238 secs] [Times: user=0.36 sys=0.01, real=0.24 secs]
13.341: [CMS-concurrent-preclean-start] 13.350: [CMS-concurrent-preclean: 0.009/0.009 secs] [Times: user=0.03 sys=0.00, real=0.01 secs] 13.350: [CMS-concurrent-abortable-preclean-start]
13.878: [GC (Allocation Failure) [ParNew: 16844397K->85085K(18874368K), 0.0960456 secs]116885867K->100127390K(155189248K), 0.0961542 secs] [Times: user=0.14 sys=0.00, real=0.05 secs]
14.366: [CMS-concurrent-abortable-preclean: 0.917/1.016 secs] [Times: user=2.22 sys=0.07, real=1.01 secs]
14.366: [GC (CMS Final Remark) [YG occupancy: 182593 K (306688 K)]14.366: [Rescan (parallel) , 0.0291598 secs]14.395: [weak refs processing, 0.0000232 secs]14.395: [class unloading, 0.0117661 secs]14.407: [scrub symbol table, 0.0015323 secs]14.409: [scrub string table, 0.0003221 secs][1 CMS-remark: 976591K(1756416K)] 1159184K(2063104K), 0.0462010 secs] [Times: user=0.14 sys=0.00, real=0.05 secs]
14.412: [CMS-concurrent-sweep-start]
14.633: [CMS-concurrent-sweep: 0.221/0.221 secs] [Times: user=0.37 sys=0.00, real=0.22 secs]
14.633: [CMS-concurrent-reset-start] 14.636: [CMS-concurrent-reset: 0.002/0.002 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
|
-
ParNew: 16844397K->85085K(18874368K), 0.0960456 secs;其中, 16844397K 表示GC前的新生代占用量, 85085K 表示GC后的新生代占用量,GC后Eden和一个Survivor为空,所以 85085K 也是另一个Survivor的占用量。括号中的 18874368K 是Eden+一个被占用Survivor的总和(18g)。
-
116885867K->100127390K(155189248K), 0.0961542 secs;其中,分别是Java堆在垃圾回收前后的大小,和Java堆大小。说明堆使用为116885867K=111.47g,回收大小为100127390K=95.49g,堆大小为155189248K=148g(去掉其中一个Survivor),回收了16g空间。
总结:在HDFS Namenode内存中的对象大都是文件,目录和blocks,这些数据只要不被程序或者数据的拥有者人为的删除,就会在Namenode的运 行生命期内一直存在,所以这些对象通常是存在在old区中,所以,如果整个hdfs文件和目录数多,blocks数也多,内存数据也会很大,
如何降低Full GC的影响?
计算NN所需的内存大小,合理配置JVM
使用低卡顿G1收集器
G1垃圾收集器利用分而治之的思想将堆进行分区,划分为一个个的区域。
G1垃圾收集器将堆拆成一系列的分区,这样的话,大部分的垃圾收集操作就只在一个分区内执行,从而避免很多GC操作在整个Java堆或者整个年轻代进行。
1
| export HADOOP_NAMENODE_OPTS="-server -Xmx220G -Xms200G -XX:+UseG1GC - XX:MaxGCPauseMillis=200 -XX:+UnlockExperimentalVMOptions - XX:+ParallelRefProcEnabled -XX:-ResizePLAB -XX:+PerfDisableSharedMem -XX:- OmitStackTraceInFastThrow -XX:G1NewSizePercent=2 -XX:ParallelGCThreads=23 - XX:InitiatingHeapOccupancyPercent=40 -XX:G1HeapRegionSize=32M - XX:G1HeapWastePercent=10 -XX:G1MixedGCCountTarget=16 -verbose:gc - XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps - XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=5 -XX:GCLogFileSize=100M - Xloggc:/var/log/hbase/gc.log -Dhadoop.security.logger=${HADOOP_SECURITY_LOGGER:- INFO,RFAS} -Dhdfs.audit.logger=${HDFS_AUDIT_LOGGER:-INFO,NullAppender} $HADOOP_NAMENODE_OPTS"
|
注意:如果现在采用的垃圾收集器没有问题,就不要选择G1,如果追求低停顿,可以尝试使用G1

 wechat
wechat alipay
alipay