Hadoop当中支持的压缩算法
数据压缩有两大好处,节约磁盘空间,加速数据在网络和磁盘上的传输!
进入linux环境,执行hadoop checknative查看我们编译之后的hadoop支持的各种压缩,如果出现openssl为false,那么就在线安装一下依赖包!

安装openssl
1
| yum install -y openssl-devel
|
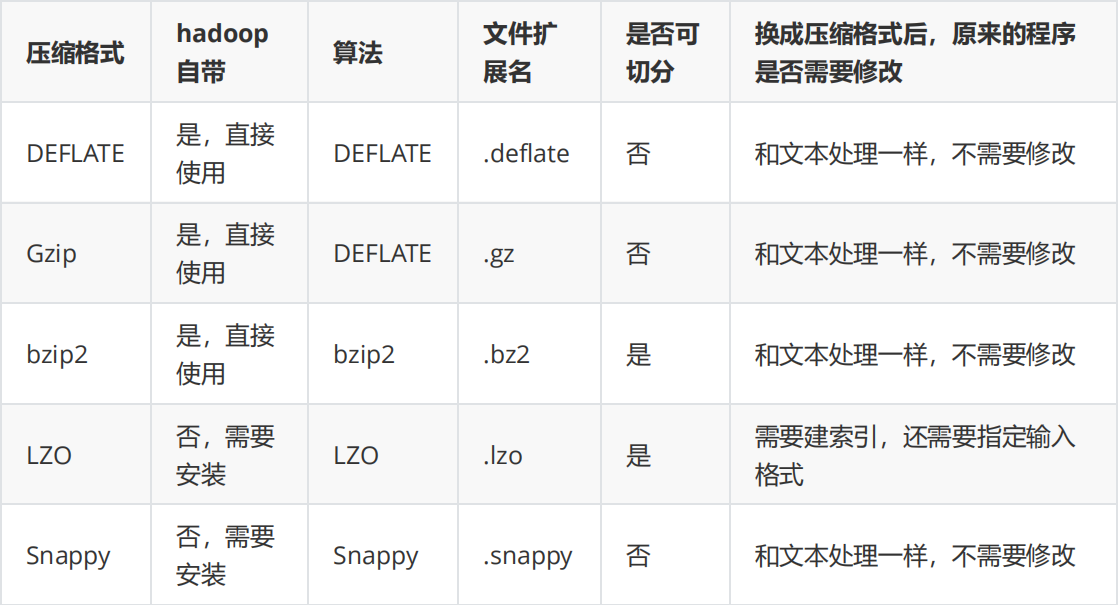
为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器
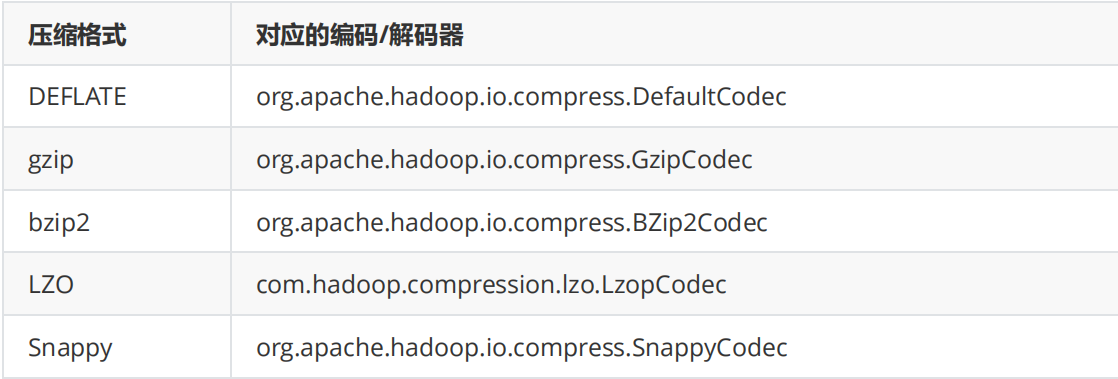
常见压缩方式对比分析
压缩位置
-
Map输入端压缩
此处使用压缩文件作为Map的输入数据,无需显示指定编解码方式,Hadoop会自动检查文件扩展名,如果压缩方式能够匹配,Hadoop就会选择合适的编解码方式对文件进行压缩和解压。
-
Map输出端压缩
Shuffle是Hadoop MR过程中资源消耗最多的阶段,如果有数据量过大造成网络传输速度缓慢,可以考虑使用压缩
-
Reduce端输出压缩
输出的结果数据使用压缩能够减少存储的数据量,降低所需磁盘的空间,并且作为第二个MR的输入时可以复用压缩。
压缩配置方式
- 在驱动代码中通过Configuration直接设置使用的压缩方式,可以开启Map输出和Reduce输出压缩。
1
2
3
4
5
6
7
8
9
10
| Configuration configuration = new Configuration();
设置map阶段压缩
configuration.set("mapreduce.map.output.compress","true");
configuration.set("mapreduce.map.output.compress.codec","org.apache.hadoop.i o.compress.SnappyCodec");
设置reduce阶段的压缩
configuration.set("mapreduce.output.fileoutputformat.compress","true");
configuration.set("mapreduce.output.fileoutputformat.compress.type","RECORD");
configuration.set("mapreduce.output.fileoutputformat.compress.codec","org.ap ache.hadoop.io.compress.SnappyCodec");
|
- 配置mapred-site.xml(修改后分发到集群其它节点,重启Hadoop集群)
1
2
3
4
5
6
7
8
9
10
11
12
| <property>
<name>mapreduce.output.fileoutputformat.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.type</name>
<value>RECORD</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
|
注意,第二种方法不推荐使用,这会导致运行在集群的所有MR任务都会执行压缩,第一种自由度更高。
压缩案例
使用snappy压缩方式压缩WordCount案例的输出结果数据
1
2
3
4
5
6
7
8
9
10
11
12
| //1. 获取配置文件对象,获取job对象实例
final Configuration conf = new Configuration();
//针对reduce端输出使用snappy压缩
conf.set("mapreduce.output.fileoutputformat.compress", "true");
conf.set("mapreduce.output.fileoutputformat.compress.type", "RECORD");
conf.set("mapreduce.output.fileoutputformat.compress.codec", "org.apache.hadoop.io.compress.SnappyCodec");
final Job job = Job.getInstance(conf, "WordCountDriver");
//6. 指定job读取数据路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
//7. 指定job输出结果路径
FileOutputFormat.setOutputPath(job, new Path(args[1]));
|
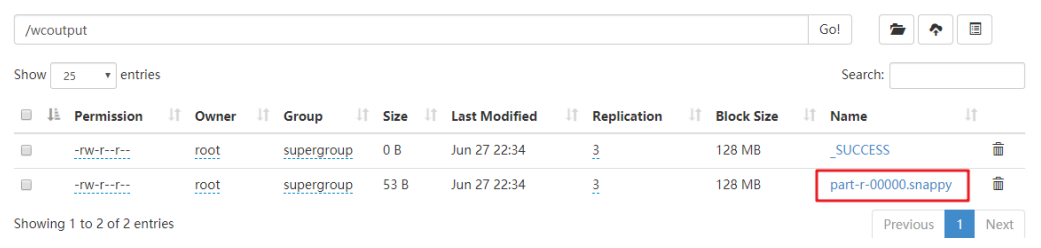
wordcount重新打成jar包,提交集群运行,

验证输出结果是否已进行了snappy压缩

 wechat
wechat alipay
alipay


