
Spark-SQL编程之Action操作与Transformation操作
Action操作
与RDD类似的操作
show、collect、collectAsList、head、first、count、take、takeAsList、reduce
与结构相关
printSchema、explain、columns、dtypes、col
1 | EMPNO,ENAME,JOB,MGR,HIREDATE,SAL,COMM,DEPTNO |
1 | // 处理了文件头,得到了字段名称 |
1 | // 结构属性 |
Transformation 操作
与RDD类似的操作
map、filter、flatMap、mapPartitions、sample、 randomSplit、 limit、distinct、dropDuplicates、describe
1 | df1.map(row=>row.getAs[Int](0)).show |
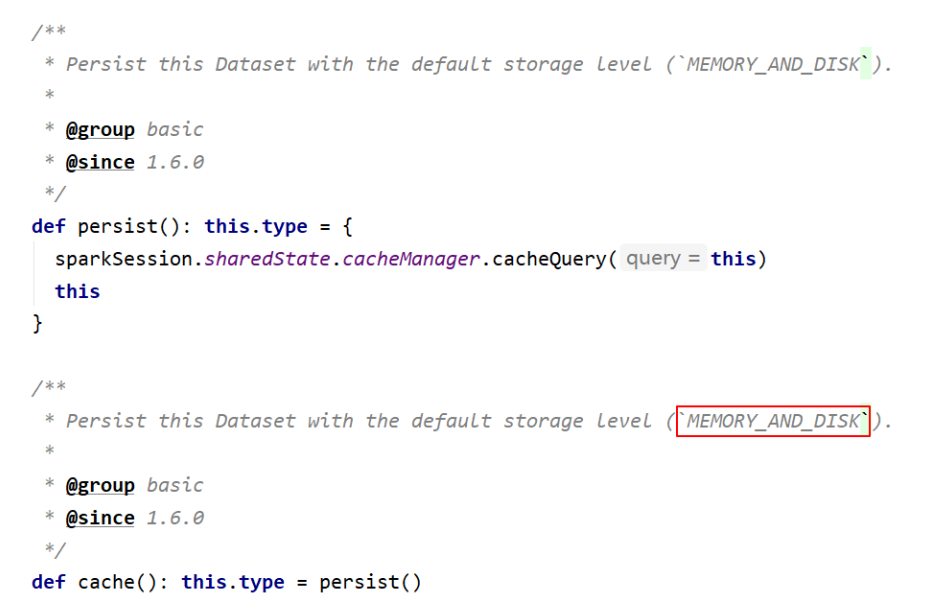
存储相关
cacheTable、persist、checkpoint、unpersist、cache
备注:Dataset 默认的存储级别是 MEMORY_AND_DISK
1 | import org.apache.spark.storage.StorageLevel |
select相关
列的多种表示、select、selectExpr
drop、withColumn、withColumnRenamed、cast(内置函数)
1 | // 列的多种表示方法。使用""、$""、'、col()、ds("") |
where相关
where == filter
1 | // where操作 |
groupBy相关
groupBy、agg、max、min、avg、sum、count(后面5个为内置函数)
1 | // groupBy、max、min、mean、sum、count(与df1.count不同) |
orderBy相关
orderBy == sort
1 | // orderBy |
join相关
1 | // 1、笛卡尔积 |
集合相关
union==unionAll(过期)、intersect、except
1 | // union、unionAll、intersect、except。集合的交、并、差 |
空值处理
na.fill、na.drop
1 | // NaN (Not a Number) |
窗口函数
一般情况下窗口函数不用 DSL 处理,直接用SQL更方便
参考源码Window.scala、WindowSpec.scala(主要)
1 | import org.apache.spark.sql.expressions.Window |
内建函数
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 WeiJia_Rao!
 wechat
wechat alipay
alipay



