// 这里采用本地文件,也可以采用HDFS文件 val lines = ssc.textFileStream("data/log/") val words = lines.flatMap(_.split("\\s+")) val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
objectSocketLikeNC{ defmain(args: Array[String]): Unit = { val words: Array[String] = "Hello World Hello Hadoop Hello spark kafka hive zookeeper hbase flume sqoop".split("\\s+") val n: Int = words.length val port: Int = 9999
val random: Random = scala.util.Random val server = newServerSocket(port) val socket: Socket = server.accept() println("成功连接到本地主机:" + socket.getInetAddress)
while (true) { val out = newPrintWriter(socket.getOutputStream) out.println(words(random.nextInt(n)) + " "+ words(random.nextInt(n))) out.flush() Thread.sleep(100) } } }
classServerThread(sock: Socket) extendsThread{ val words = "hello world hello spark hello word hello java hello hadoop hello kafka".split("\\s+") val length = words.length
overridedefrun(): Unit = { val out = newDataOutputStream(sock.getOutputStream) val random = scala.util.Random while (true) { val (wordx, wordy) = (words(random.nextInt(length)), words(random.nextInt(length))) out.writeUTF(s"$wordx$wordy") Thread.sleep(100) } } }
objectSocketServer{ defmain(args: Array[String]): Unit = { val server = newServerSocket(9999) println(s"Socket Server 已启动: ${server.getInetAddress}:${server.getLocalPort}")
while (true) { val socket = server.accept() println("成功连接到本地主机:" + socket.getInetAddress) newServerThread(socket).start() } } }
objectRDDQueueDStream{ defmain(args: Array[String]) { Logger.getLogger("org").setLevel(Level.WARN) val sparkConf = newSparkConf().setAppName(this.getClass.getCanonicalName).setMaster( "local[2]")
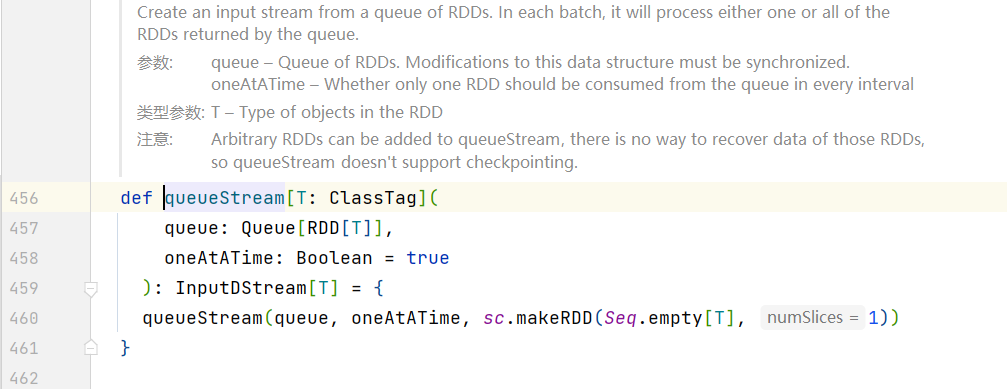
// 每隔1秒对数据进行处理 val ssc = newStreamingContext(sparkConf, Seconds(1)) val rddQueue = newQueue[RDD[Int]]() val queueStream = ssc.queueStream(rddQueue) val mappedStream = queueStream.map(r => (r % 10, 1)) val reducedStream = mappedStream.reduceByKey(_ + _) reducedStream.print() ssc.start()
// 每秒产生一个RDD for (i <- 1 to 5){ rddQueue.synchronized { val range = (1 to 100).map(_*i) rddQueue += ssc.sparkContext.makeRDD(range, 2) } Thread.sleep(2000) }




 wechat
wechat alipay
alipay

