MR reduce端join
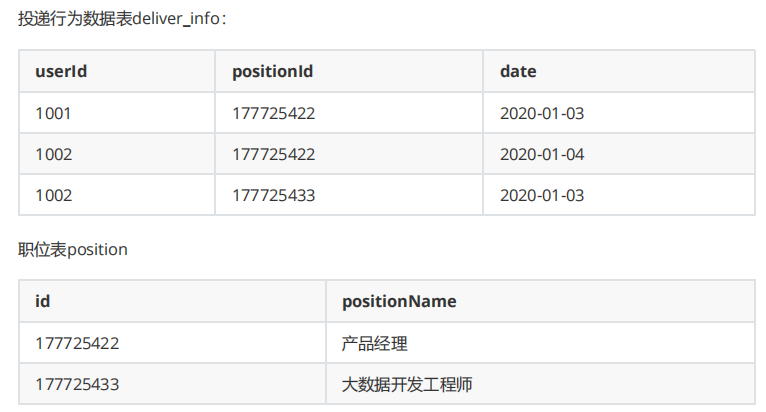
需求分析
假如数据量巨大,两表的数据是以文件的形式存储在HDFS中,需要用mapreduce程序来实现一下SQL查询运算。
编写DeliverBean类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 package com.lagou.mr.reduce_join; import org.apache.hadoop.io.Writable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; public class DeliverBean implements Writable { private String userId; private String positionId; private String date; private String positionName; //判断是投递数据还是职位数据标识 private String flag; public DeliverBean() { } public String getUserId() { return userId; } public void setUserId(String userId) { this.userId = userId; } public String getPositionId() { return positionId; } public void setPositionId(String positionId) { this.positionId = positionId; } public String getDate() { return date; } public void setDate(String date) { this.date = date; } public String getPositionName() { return positionName; } public void setPositionName(String positionName) { this.positionName = positionName; } public String getFlag() { return flag; } public void setFlag(String flag) { this.flag = flag; } @Override public void write(DataOutput out) throws IOException { out.writeUTF(userId); out.writeUTF(positionId); out.writeUTF(date); out.writeUTF(positionName); out.writeUTF(flag); } @Override public void readFields(DataInput in) throws IOException { this.userId = in.readUTF(); this.positionId = in.readUTF(); this.date = in.readUTF(); this.positionName = in.readUTF(); this.flag = in.readUTF(); } @Override public String toString() { return "DeliverBean{" + "userId='" + userId + '\'' + ", positionId='" + positionId + '\'' + ", date='" + date + '\'' + ", positionName='" + positionName + '\'' + ", flag='" + flag + '\'' + '}'; } }
编写ReduceJoinMapper类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 package com.lagou.mr.reduce_join; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import java.io.IOException; //输出kv类型:k: positionId,v: deliverBean public class ReduceJoinMapper extends Mapper<LongWritable, Text, Text, DeliverBean> { String name; DeliverBean bean = new DeliverBean(); Text k = new Text(); @Override protected void setup(Context context) throws IOException, InterruptedException { // 1 获取输入文件切片 FileSplit split = (FileSplit) context.getInputSplit(); // 2 获取输入文件名称 name = split.getPath().getName(); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 获取输入数据 String line = value.toString(); // 2 不同文件分别处理 if (name.startsWith("deliver_info")) { // 2.1 切割 String[] fields = line.split("\t"); // 2.2 封装bean对象 bean.setUserId(fields[0]); bean.setPositionId(fields[1]); bean.setDate(fields[2]); bean.setPositionName(""); bean.setFlag("deliver"); k.set(fields[1]); } else { // 2.3 切割 String[] fields = line.split("\t"); // 2.4 封装bean对象 bean.setPositionId(fields[0]); bean.setPositionName(fields[1]); bean.setUserId(""); bean.setDate(""); bean.setFlag("position"); k.set(fields[0]); } // 3 写出 context.write(k, bean); } }
编写ReduceJoinReducer类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 package com.lagou.mr.reduce_join; import org.apache.commons.beanutils.BeanUtils; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; import java.util.ArrayList; public class ReduceJoinReducer extends Reducer<Text, DeliverBean, DeliverBean, NullWritable> { @Override protected void reduce(Text key, Iterable<DeliverBean> values, Context context) throws IOException, InterruptedException { // 1准备投递行为数据的集合 ArrayList<DeliverBean> deBeans = new ArrayList<>(); // 2 准备bean对象 DeliverBean pBean = new DeliverBean(); for (DeliverBean bean : values) { if ("deliver".equals(bean.getFlag())) { DeliverBean dBean = new DeliverBean(); try { BeanUtils.copyProperties(dBean, bean); } catch (Exception e) { e.printStackTrace(); } deBeans.add(dBean); } else { try { BeanUtils.copyProperties(pBean, bean); } catch (Exception e) { e.printStackTrace(); } } } // 3 表的拼接 for (DeliverBean bean : deBeans) { bean.setPositionName(pBean.getPositionName()); // 4 数据写出去 context.write(bean, NullWritable.get()); } } }
编写ReduceJoinDriver类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 package com.lagou.mr.reduce_join; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class ReduceJoinDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { // 1. 获取配置文件对象,获取job对象实例 final Configuration conf = new Configuration(); final Job job = Job.getInstance(conf, "ReduceJoinDriver"); // 2. 指定程序jar的本地路径 job.setJarByClass(ReduceJoinDriver.class); // 3. 指定Mapper/Reducer类 job.setMapperClass(ReduceJoinMapper.class); job.setReducerClass(ReduceJoinReducer.class); // 4. 指定Mapper输出的kv数据类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(DeliverBean.class); // 5. 指定最终输出的kv数据类型 job.setOutputKeyClass(DeliverBean.class); job.setOutputValueClass(NullWritable.class); // 6. 指定job输出结果路径 FileInputFormat.setInputPaths(job, new Path("E:\\bigdatafile\\input\\reduce_join"));//指定读取数据的原始 路径 // 7. 指定job输出结果路径 FileOutputFormat.setOutputPath(job, new Path("E:\\bigdatafile\\output\\reduce_join")); //指定结果数据输出 路径 // 8. 提交作业 final boolean flag = job.waitForCompletion(true); //jvm退出:正常退出0,非0值则是错误退出 System.exit(flag ? 0 : 1); } }
缺点:这种方式中,join的操作是在reduce阶段完成,reduce端的处理压力太大,map节点的运算负载则很低,资源利用率不高,且在reduce阶段极易产生数据倾斜。
解决方案: map端join实现方式
MR map端join
在Mapper的setup阶段,将文件读取到缓存集合中;在驱动函数中加载缓存。
在博客MapReduce编程规范及示例编写 中maven工程wordcount里编写案例,创建map_join包。
编写DeliverBean类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 package com.lagou.mr.map_join; import org.apache.hadoop.io.Writable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; public class DeliverBean implements Writable { private String userId; private String positionId; private String date; private String positionName; private String flag; public DeliverBean() { } public DeliverBean(String userId, String positionId, String date, String positionName, String flag) { this.userId = userId; this.positionId = positionId; this.date = date; this.positionName = positionName; this.flag = flag; } public String getUserId() { return userId; } public void setUserId(String userId) { this.userId = userId; } public String getPositionId() { return positionId; } public void setPositionId(String positionId) { this.positionId = positionId; } public String getDate() { return date; } public void setDate(String date) { this.date = date; } public String getPositionName() { return positionName; } public void setPositionName(String positionName) { this.positionName = positionName; } public String getFlag() { return flag; } public void setFlag(String flag) { this.flag = flag; } @Override public void write(DataOutput out) throws IOException { out.writeUTF(userId); out.writeUTF(positionId); out.writeUTF(date); out.writeUTF(positionName); out.writeUTF(flag); } @Override public void readFields(DataInput in) throws IOException { this.userId = in.readUTF(); this.positionId = in.readUTF(); this.date = in.readUTF(); this.positionName = in.readUTF(); this.flag=in.readUTF(); } @Override public String toString() { return "DeliverBean{" + "userId='" + userId + '\'' + ", positionId='" + positionId + '\'' + ", date='" + date + '\'' + ", positionName='" + positionName + '\'' + '}'; } }
编写MapJoinMapper类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 package com.lagou.mr.map_join; import com.lagou.mr.reduce_join.DeliverBean; import org.apache.commons.lang3.StringUtils; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.BufferedReader; import java.io.FileInputStream; import java.io.IOException; import java.io.InputStreamReader; import java.util.HashMap; import java.util.Map; /** * 使用map端join完成投递行为与职位数据的关联 * map端缓存所有的职位数据 * map方法读取的文件数据是投递行为数据 * 基于投递行为数据的positionid去缓存中查询出positionname即可 * 这个job中无需reducetask,setnumreducetask为0 */ public class MapJoinMapper extends Mapper<LongWritable, Text, Text, NullWritable> { String name; DeliverBean bean = new DeliverBean(); Text k = new Text(); Map<String, String> pMap = new HashMap<>(); //读取文件 @Override protected void setup(Context context) throws IOException, InterruptedException { // 1 获取缓存的文件 BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("position.txt"),"UTF-8")); String line; while(StringUtils.isNotEmpty(line = reader.readLine())){ // 2 切割 String[] fields = line.split("\t"); // 3 缓存数据到集合 pMap.put(fields[0], fields[1]); } // 4 关流 reader.close(); } @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 获取一行 String line = value.toString(); // 2 截取 String[] fields = line.split("\t"); // 3 获取职位id String pId = fields[1]; // 4 获取职位名称 String pName = pMap.get(pId); // 5 拼接 k.set(line + "\t"+ pName); // 写出 context.write(k, NullWritable.get()); } }
编写MapJoinDriver类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 package com.lagou.mr.map_join; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.net.URI; import java.net.URISyntaxException; public class MapJoinDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException, URISyntaxException { // 1. 获取配置文件对象,获取job对象实例 final Configuration conf = new Configuration(); final Job job = Job.getInstance(conf, "ReduceJoinDriver"); // 2. 指定程序jar的本地路径 job.setJarByClass(MapJoinDriver.class); // 3. 指定Mapper类 job.setMapperClass(MapJoinMapper.class); // 4. 指定最终输出的kv数据类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); //5.指定job读取数据路径 FileInputFormat.setInputPaths(job, new Path("E:\\bigdatafile\\input\\map_join\\deliver_info.txt"));//指定读取数据的原始 路径 // 7. 指定job输出结果路径 FileOutputFormat.setOutputPath(job, new Path("E:\\bigdatafile\\output\\map_join")); //指定结果数据输出 路径 // 7.加载缓存文件 job.addCacheFile(new URI("file:///E:/bigdatafile/input/map_join/position.txt")); job.setNumReduceTasks(0); // 8. 提交作业 final boolean flag = job.waitForCompletion(true); //jvm退出:正常退出0,非0值则是错误退出 System.exit(flag ? 0 : 1); } }

 wechat
wechat alipay
alipay



