
Linux安装部署高可用k8s集群
环境规划
多主多从:多个Master节点和多台Node节点,使用VIP漂移,,用于生产环境。
| 角色 | IP地址 | 操作系统 | 配置 | 软件 |
|---|---|---|---|---|
| k8svip 虚拟 | 192.168.18.110 | |||
| master01 | 192.168.18.111 | CentOS8 | 4核CPU,8G内存,120G硬盘 | docker & kubeadm & kubectl & kubelet & Keepalived & HAproxy & Flannel |
| master02 | 192.168.18.112 | CentOS8 | 4核CPU,8G内存,120G硬盘 | docker & kubeadm & kubectl & kubelet & Keepalived & HAproxy |
| node01 | 192.168.18.113 | CentOS8 | 4核CPU,8G内存,120G硬盘 | docker & kubeadm & kubectl & kubelet |
| node02 | 192.168.18.114 | CentOS8 | 4核CPU,8G内存,120G硬盘 | docker & kubeadm & kubectl & kubelet |
四台CentOS服务器(二主二从)。
环境搭建
环境初始化
-
关闭防火墙和禁止防火墙开机启动。(所有机器)
1
2systemctl stop firewalld.service
systemctl disable firewalld.service -
设置主机名并解析。(所有机器)
1
2
3
4
5
6
7
8
9
10
11
12
13
14# 配置四台机器主机名
hostnamectl set-hostname master01
hostnamectl set-hostname master02
hostnamectl set-hostname node01
hostnamectl set-hostname node02
# 修改hosts文件
vi /etc/hosts
192.168.18.111 master01
192.168.18.112 master02
192.168.18.113 node01
192.168.18.114 node02
192.168.18.110 k8svip -
配置ssh免密登录。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# 在master01节点生成证书,并创建authorized_keys文件
ssh-keygen
cd /root/.ssh
cp id_rsa.pub authorized_keys
for i in 112 113 114
> do
> scp -r /root/.ssh 192.168.18.$i:/root/
> done
#需要在每台主机上验证是否可以相互免密登录
ssh 192.168.18.111
ssh 192.168.18.112
ssh 192.168.18.113
ssh 192.168.18.114 -
时间同步。(所有机器)
redhat/centos 7.x默认使用的时间同步服务为ntp服务,但是从redhat/centos 8开始在官方的仓库中移除了ntp软件,换成默认的chrony进行时间同步的服务。
chrony本身既可以作为客户端向其他时间服务器同步时间又可以提供时间同步的服务,也就是说同时作为客户端和服务端,配置文件统一都是:/etc/chrony.conf。
1
2
3
4# 所有机器
yum install -y chrony
systemctl enable chronyd.service这里使用node02作为服务端,其他节点作为客户端。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# node02机器执行
vi /etc/chrony.conf
# 修改以下
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
# pool 2.centos.pool.ntp.org iburst
# 服务端可以向互联网的公共服务器请求同步时间
pool time1.cloud.tencent.com iburst
# Allow NTP client access from local network.
# 192.168.18.0网段的所有机器访问,即192.168.18.x的ip都可以向当前服务器请求同步
allow 192.168.18.1/24
# 重启服务
systemctl restart chronyd1
2
3
4
5
6
7
8
9
10
11# 其他所有节点执行
vi /etc/chrony.conf
# 修改以下
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
# pool 2.centos.pool.ntp.org iburst
# 客户端可以向服务端请求同步时间
pool 192.168.18.114 iburst
# 重启服务
systemctl restart chronyd1
2
3
4
5
6
7
8
9
10
11# 查看当前的同步源,比如刚才的服务端可以看到多个源,客户端只能看到一个
chronyc sources -v
# 查看当前的同步状态
chronyc sourcestats -v
# 手动同步一次时间,返回200 OK表示同步成功
chronyc -a makestep
# 显示系统时间信息
chronyc tracking -
关闭selinux。(所有机器)
1
setenforce 0&&sed -ri "s/(^SELINUX=).+/\1disabled/" /etc/selinux/config
-
关闭swap分区。(所有机器)
1
sed -ri 's/.*swap.*/#&/' /etc/fstab && swapoff -a
-
将桥接的IPv4流量传递到iptables的链。(所有机器)
1
2
3
4
5
6
7
8
9
10
11
12
13cat > /etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
net.ipv4.ip_nonlocal_bind = 1
vm.swappiness = 0
EOF
# 从所有系统配置文件中加载内核参数
sysctl --system
# 加载br_netfilter模块
modprobe br_netfilter -
开启ipvs(所有机器)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15yum -y install ipset ipvsadm
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack
EOF
# 授权、运行、检查是否加载:
chmod 755 /etc/sysconfig/modules/ipvs.modules
bash /etc/sysconfig/modules/ipvs.modules
lsmod | grep -e ip_vs -e nf_conntrack
安装docker、kubeadm、kubectl和kubelet
每台服务器中分别安装docker、kubeadm、kubectl和kubelet。
-
安装docker,可以查看Linux安装部署docker博客。(所有机器)
-
安装kubeadm、kubelet和kubectl。(所有机器)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23# 配置kubernetes的yum源
vi /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
# 安装软件
yum install -y kubeadm-1.17.0 kubectl-1.17.0 kubelet-1.17.0
# 为了实现Docker使用的cgroup drvier和kubelet使用的cgroup drver一致,建议修改"/etc/sysconfig/kubelet"文件的内容
vi /etc/sysconfig/kubelet
# 修改
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"
KUBE_PROXY_MODE="ipvs"
# 设置开机启动
systemctl enable kubelet
实现高可用,安装keepalibed以及HAproxy
若服务器资源足够,keepalibed以及HAproxy可以不安装在主从机器中。
-
安装keepalibed以及HAproxy。(所有master机器)
1
yum -y install haproxy keepalived
-
修改haproxy配置文件。(所有master机器)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78mv /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.bak
# master节点文件内容都一样
vi /etc/haproxy/haproxy.cfg
#---------------------------------------------------------------------
# Global settings
#---------------------------------------------------------------------
global
# to have these messages end up in /var/log/haproxy.log you will
# need to:
# 1) configure syslog to accept network log events. This is done
# by adding the '-r' option to the SYSLOGD_OPTIONS in
# /etc/sysconfig/syslog
# 2) configure local2 events to go to the /var/log/haproxy.log
# file. A line like the following can be added to
# /etc/sysconfig/syslog
#
# local2.* /var/log/haproxy.log
#
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
# turn on stats unix socket
stats socket /var/lib/haproxy/stats
#---------------------------------------------------------------------
# common defaults that all the 'listen' and 'backend' sections will
# use if not designated in their block
#---------------------------------------------------------------------
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
#---------------------------------------------------------------------
# kubernetes apiserver frontend which proxys to the backends
#---------------------------------------------------------------------
frontend kubernetes-apiserver
mode tcp
bind *:16443
option tcplog
default_backend kubernetes-apiserver
#---------------------------------------------------------------------
# round robin balancing between the various backends
#---------------------------------------------------------------------
backend kubernetes-apiserver
mode tcp
balance roundrobin
server master01 192.168.18.111:6443 check
server master02 192.168.18.112:6443 check
#---------------------------------------------------------------------
# collection haproxy statistics message
#---------------------------------------------------------------------
listen stats
bind *:1080
mode http
stats enable
stats auth admin:123456
stats refresh 5s
stats realm HAProxy\ Statistics
stats uri /haproxy-status -
启动haproxy并检查。(所有master机器)
1
2
3
4
5
6
7
8
9
10
11
12
13
14systemctl start haproxy
systemctl enable haproxy
yum -y install net-tools
[root@master01 ~]# netstat -lntup|grep haproxy
tcp 0 0 0.0.0.0:1080 0.0.0.0:* LISTEN 803035/haproxy
tcp 0 0 0.0.0.0:16443 0.0.0.0:* LISTEN 803035/haproxy
udp 0 0 0.0.0.0:46627 0.0.0.0:* 803033/haproxy
[root@master02 docker]# netstat -lntup|grep haproxy
tcp 0 0 0.0.0.0:1080 0.0.0.0:* LISTEN 814950/haproxy
tcp 0 0 0.0.0.0:16443 0.0.0.0:* LISTEN 814950/haproxy
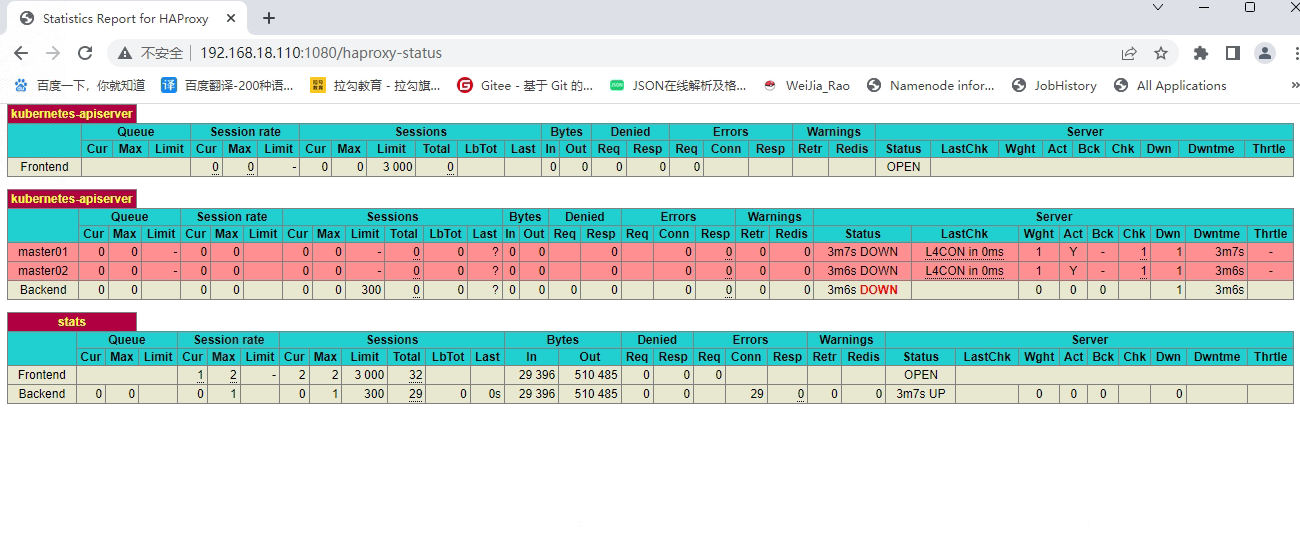
udp 0 0 0.0.0.0:56907 0.0.0.0:* 814948/haproxy网页访问虚拟ip 192.168.18.110:1080/haproxy-status 或者master节点的ip都可以查看haproxy的状态
-
修改keepalibed配置文件。(所有master机器)
1
2
3mv /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.bak
# 每个master节点要做相应的修改
vi /etc/keepalived/keepalived.conf1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30# master01的keepalibed配置文件
global_defs { #全局定义部分
router_id k8s #Keepalived服务器的路由标识,自定义
}
vrrp_script check_haproxy { #定义vrrp脚本
script "killall -0 haproxy" #要执行的命令
interval 3 #脚本调用时间
weight -2 #根据权重值调整vrrp实例的优先级,默认为0
fall 10 #需要失败多少次,vrrp才进行角色状态切换(从正常切换为fault)
rise 2 #需要成功多少次,vrrp才进行角色状态切换(从fault切换为正常)
}
vrrp_instance VI_1 {
state MASTER #指定Master或者BACKUP,必须大写
interface enp1s0 #监听的实际网口
virtual_router_id 51 #组播ID,取值在0-255之间,用来区分多个instance的VRRP组播, 同一网段中该值不能重复,并且同一个vrrp实例使用唯一的标识。
priority 250 #权重值,数字越大优先级越高,谁的优先级高谁就是master,该项取值范围是1-255(在此范围之外会被识别成默认值100)
advert_int 1 #发送组播包的间隔时间,默认为1秒
authentication {
auth_type PASS #认证,认证类型有PASS和AH(IPSEC)。
auth_pass 123456 #密码,同一vrrp实例MASTER与BACKUP 使用相同的密码才能正常通信
}
virtual_ipaddress {
192.168.18.110 #vip地址
}
track_script {
check_haproxy
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30# master02的keepalibed配置文件
global_defs { #全局定义部分
router_id k8s #Keepalived服务器的路由标识,自定义
}
vrrp_script check_haproxy { #定义vrrp脚本
script "killall -0 haproxy" #要执行的命令
interval 3 #脚本调用时间
weight -2 #根据权重值调整vrrp实例的优先级,默认为0
fall 10 #需要失败多少次,vrrp才进行角色状态切换(从正常切换为fault)
rise 2 #需要成功多少次,vrrp才进行角色状态切换(从fault切换为正常)
}
vrrp_instance VI_1 {
state BACKUP #指定Master或者BACKUP,必须大写
interface enp1s0 #监听的实际网口
virtual_router_id 51 #组播ID,取值在0-255之间,用来区分多个instance的VRRP组播, 同一网段中该值不能重复,并且同一个vrrp实例使用唯一的标识。
priority 200 #权重值,数字越大优先级越高,谁的优先级高谁就是master,该项取值范围是1-255(在此范围之外会被识别成默认值100)
advert_int 1 #发送组播包的间隔时间,默认为1秒
authentication {
auth_type PASS #认证,认证类型有PASS和AH(IPSEC)。
auth_pass 123456 #密码,同一vrrp实例MASTER与BACKUP 使用相同的密码才能正常通信
}
virtual_ipaddress {
192.168.18.110 #vip地址
}
track_script {
check_haproxy
}
}注意: 以上 script “killall -0 haproxy”。这种方式用在主机部署上可以,但容器部署时,在keepalived容器中无法知道另一个容器haproxy的活跃情况,因此我在此处通过检测端口号来判断haproxy的健康状况。如下:
1
script "/bin/bash -c 'if [[ $(netstat -nlp | grep 9443) ]]; then exit 0; else exit 1; fi'" # haproxy 检测
-
启动keepalived并检查
1
2systemctl start keepalived
systemctl enable keepalived
部署k8s的Master节点,集群初始化
-
生成kubeadm预处理配置文件。(在具有vip的master上操作,这里为master01)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46mkdir -p /usr/local/kubernetes/
cd /usr/local/kubernetes/
kubeadm config print init-defaults > kubeadm-init.yaml
vi kubeadm-init.yaml
apiVersion: kubeadm.k8s.io/v1beta2
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.18.111 #master01的地址
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
name: master01
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta2
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controlPlaneEndpoint: "192.168.18.110:16443" #VIP的地址和端口
controllerManager: {}
dns:
type: CoreDNS
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers #阿里云的镜像站点
kind: ClusterConfiguration
kubernetesVersion: v1.17.0
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12 #选择默认即可,当然也可以自定义CIDR
podSubnet: 10.244.0.0/16 #添加pod网段
scheduler: {}
# 提前拉取镜像
kubeadm config images pull --config kubeadm-init.yaml**注意:**上面的controlPlaneEndpoint这里填写的是VIP的地址,而端口则是haproxy服务的8443端口,也就是我们在haproxy里面配置的信息。(这里我改动了)

1
2
3
4
5
6# 以上错误时,可尝试删除文件,重新加载
rm -rf /etc/containerd/config.toml
systemctl restart containerd
# 重新拉取镜像
kubeadm config images pull --config kubeadm-init.yaml1
2
3
4
5# kubeadm预处理配置文件拷贝到其他master节点
scp kubeadm-init.yaml root@master02:/usr/local/kubernetes/
# 其他master节点提前拉取镜像
kubeadm config images pull --config kubeadm-init.yaml -
初始化kubenetes的master01节点
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26kubeadm init --config /usr/local/kubernetes/kubeadm-init.yaml --ignore-preflight-errors=all
# 出现以下则初始化kubenetes的master01节点成功
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join 192.168.18.110:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:89d04e787d8ae81ba79b76d23e24631f546bb8242df23efdd24188d14cee411b \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.18.110:16443 --token abcdef.0123456789abcdef \
--discovery-token-ca-cert-hash sha256:89d04e787d8ae81ba79b76d23e24631f546bb8242df23efdd24188d14cee411b1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# 出现以下需重启kubeadm
[preflight] Running pre-flight checks
[WARNING Service-Docker]: docker service is not enabled, please run 'systemctl enable docker.service'
[WARNING FileExisting-tc]: tc not found in system path
error execution phase preflight: [preflight] Some fatal errors occurred:
[ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists
[ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists
[ERROR Port-10250]: Port 10250 is in use
# 重启kubeadm
kubeadm reset -f
# 重新初始化
kubeadm init --config /usr/local/kubernetes/kubeadm-init.yaml -
配置环境变量,使用kubectl工具。(master01机器)
1
2
3mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config -
查看集群状态。(master01机器)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-0 Healthy {"health":"true"}
kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-9d85f5447-6chrb 0/1 Pending 0 148m
coredns-9d85f5447-t76bk 0/1 Pending 0 148m
etcd-master01 1/1 Running 0 148m
kube-apiserver-master01 1/1 Running 0 148m
kube-controller-manager-master01 1/1 Running 0 148m
kube-proxy-k45db 1/1 Running 0 148m
kube-scheduler-master01 1/1 Running 0 148m -
安装集群网络。(master01机器)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18# 从官方地址获取到flannel的yaml
mkdir flannel
cd flannel
wget -c https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
# 安装flannel网络
kubectl apply -f kube-flannel.yml
# 检查
kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-9d85f5447-6chrb 1/1 Running 0 166m
coredns-9d85f5447-t76bk 1/1 Running 0 166m
etcd-master01 1/1 Running 0 166m
kube-apiserver-master01 1/1 Running 0 166m
kube-controller-manager-master01 1/1 Running 0 166m
kube-proxy-k45db 1/1 Running 0 166m
kube-scheduler-master01 1/1 Running 0 166m -
复制密钥及相关文件到其他master节点
1
2
3
4ssh root@master02 mkdir -p /etc/kubernetes/pki/etcd
scp /etc/kubernetes/admin.conf root@master02:/etc/kubernetes
scp /etc/kubernetes/pki/{ca.*,sa.*,front-proxy-ca.*} root@master02:/etc/kubernetes/pki
scp /etc/kubernetes/pki/etcd/ca.* root@master02:/etc/kubernetes/pki/etcd
master02节点加入集群
1 | # master02机器上执行 |
1 | mkdir -p $HOME/.kube |
1 | kubectl get nodes |
node节点加入集群
1 | # 所有node节点执行 |
 wechat
wechat alipay
alipay



