
HDFS的Java客户端操作
客户端环境准备
-
将hadoop-2.9.2.tar.gz安装包解压到非中文路径(例如:C:\softwares\Java\hadoop-2.9.2)。
-
配置HADOOP_HOME环境变量
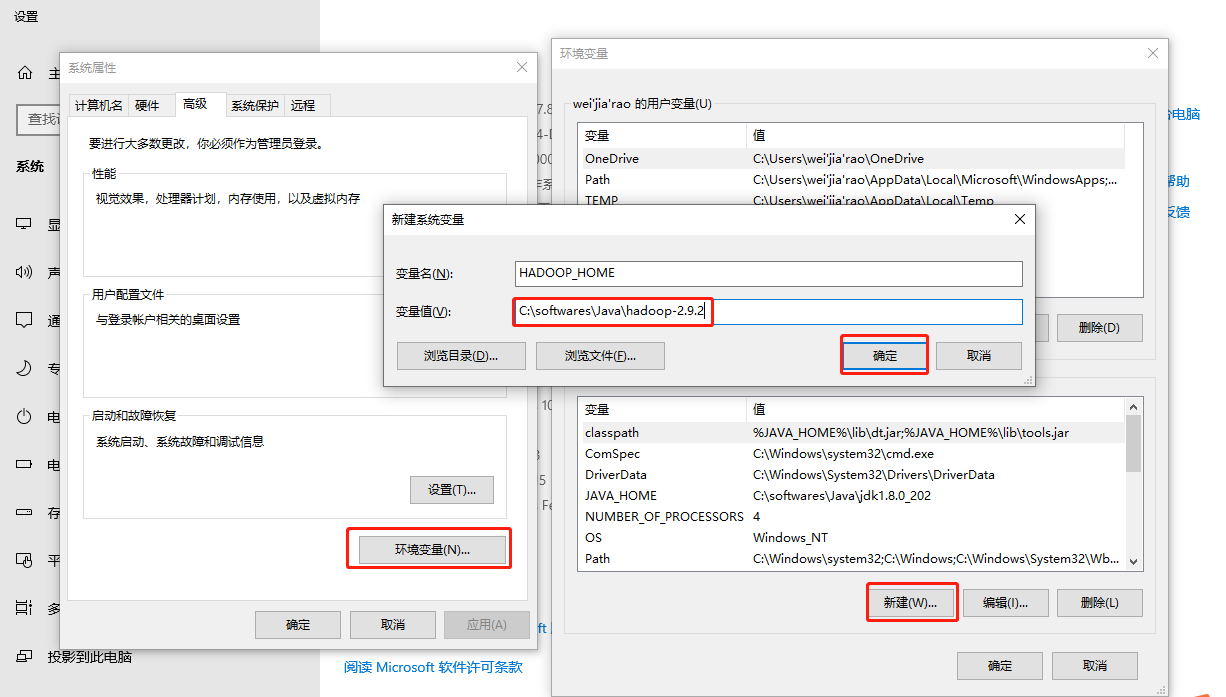
-
配置Path环境变量
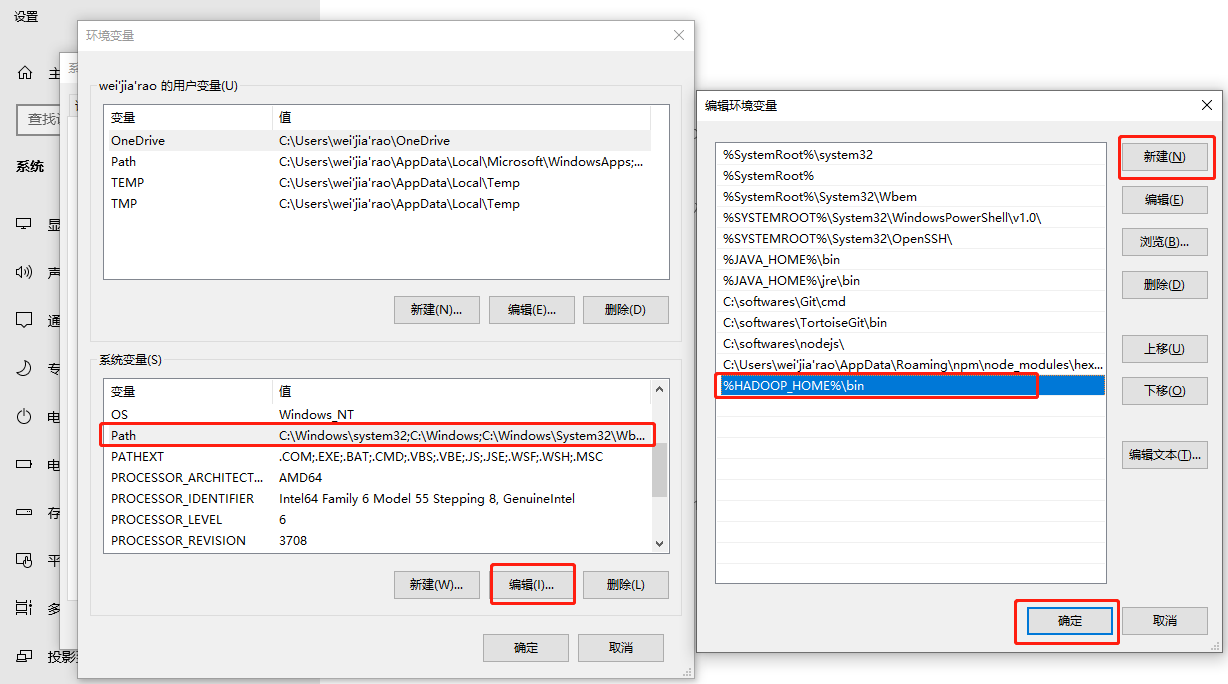
-
idea创建一个Maven工程ClientDemo
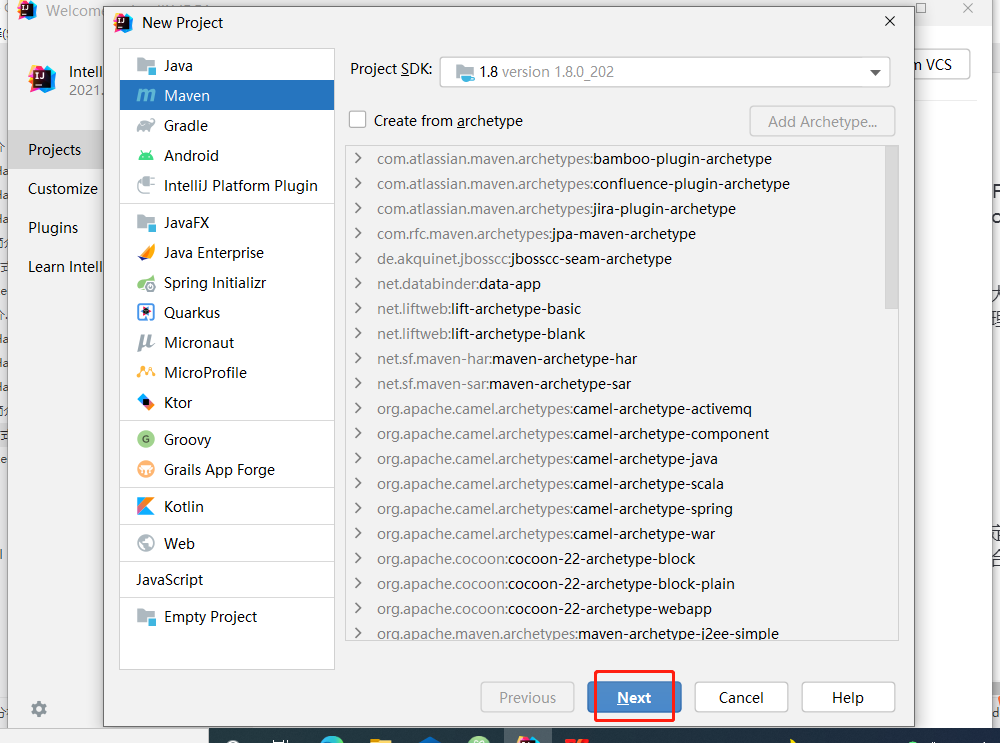
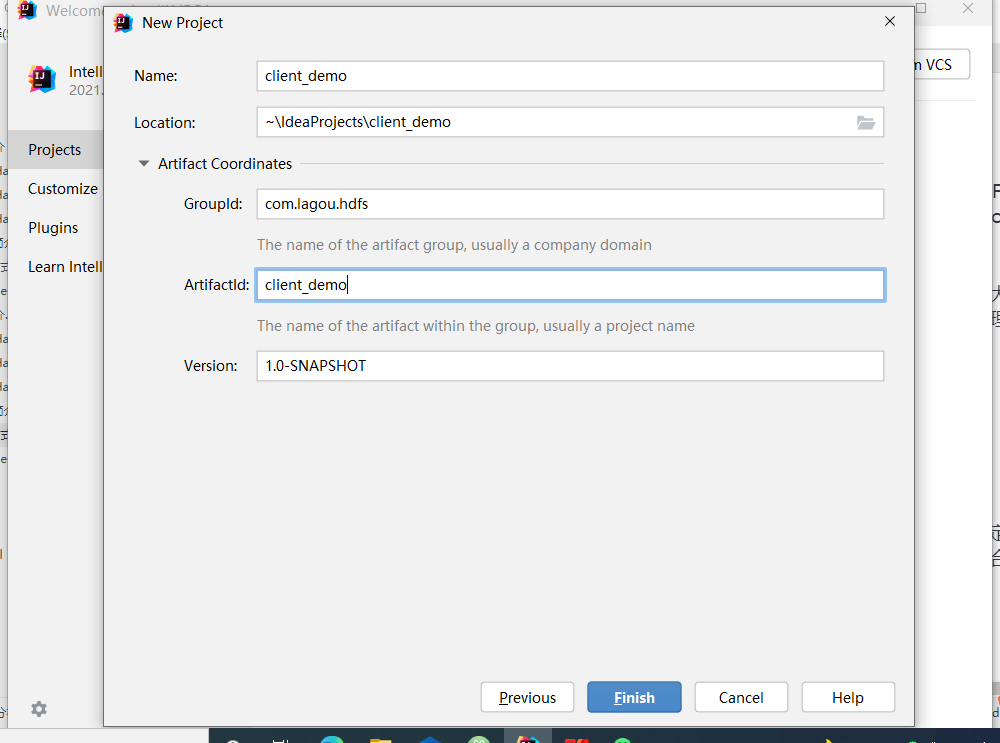
-
pom文件导入相应的依赖坐标+日志配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39<dependencies>
<!-- 单元测试junit依赖-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<!-- log4j 打印日志依赖-->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<!-- hadoop-common依赖,以下为maven远程仓库的所在地址,选择和安装的hadoop版本一致-->
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.9.2</version>
</dependency>
<!-- hadoop-client依赖,以下为maven远程仓库的所在地址,选择和安装的hadoop版本一致-->
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.9.2</version>
</dependency>
<!-- hadoop-hdfs依赖,以下为maven远程仓库的所在地址,选择和安装的hadoop版本一致-->
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.9.2</version>
</dependency>
</dependencies> -
为了便于控制程序运行打印的日志数量,需要在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,文件内容:
1
2
3
4
5
6
7
8log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n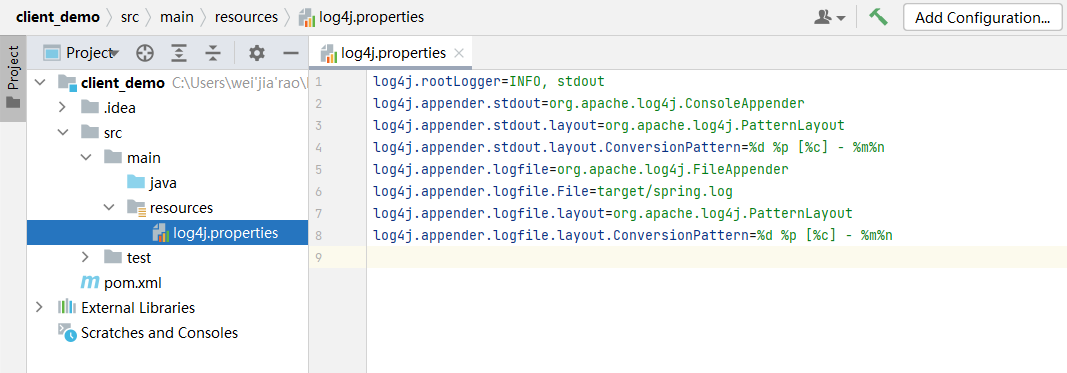
-
创建包:com.lagou.hdfs,并创建HdfsClient类,内容如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24package com.lagou.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class HdfsClient {
@Test
public void testMkdirs() throws IOException, InterruptedException, URISyntaxException {
//1 获取Hadoop集群的Configuration对象
Configuration configuration = new Configuration();
//2 根据Configuration获取FileSystem对象 url指定namenode的通讯地址,user指定linux服务器的用户
FileSystem fs = FileSystem.get(new URI("hdfs://linux121:9000"), configuration, "root");
//3 使用FileSystem对象创建一个测试目录
fs.mkdirs(new Path("/api_test"));
//4 释放FileSystem对象(类似数据库连接)
fs.close();
}
}运行testMkdirs方法,显示如图所示:
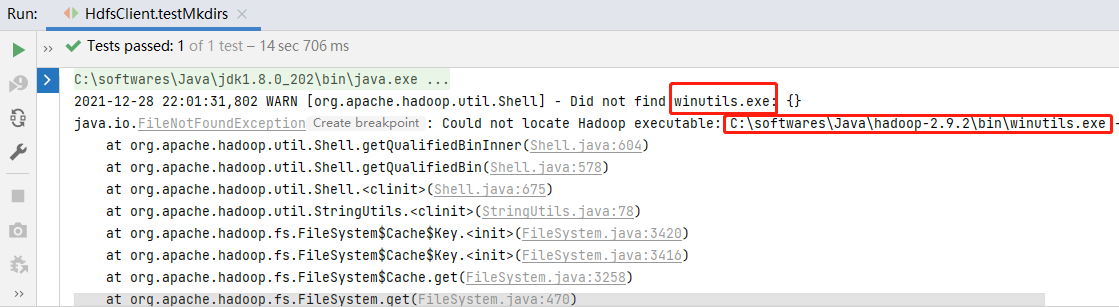
注意:Windows解压安装Hadoop后,在调用相关API操作HDFS集群可能报错,这是由于Hadoop安装缺少Windows操作系统相关文件所致。
解决方案:从资料文件夹中找到winutils.exe拷贝放到Windows系统Hadoop安装目录的bin目录下即可。
-
修改HdfsClient类,如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public class HdfsClient {
@Test
public void testMkdirs() throws IOException, InterruptedException, URISyntaxException {
//1 获取Hadoop集群的Configuration对象
Configuration configuration = new Configuration();
//2 根据Configuration获取FileSystem对象 url指定namenode的通讯地址,user指定linux服务器的用户
//linux121必须本机配置hosts才可识别
//FileSystem fs = FileSystem.get(new URI("hdfs://linux121:9000"), configuration, "root");
configuration.set("fs.defaultFS", "hdfs://linux121:9000");
FileSystem fs = FileSystem.get(configuration);
//3 使用FileSystem对象创建一个测试目录
fs.mkdirs(new Path("/api_test1"));
//4 释放FileSystem对象(类似数据库连接)
fs.close();
}
}运行testMkdirs方法,显示如图所示:
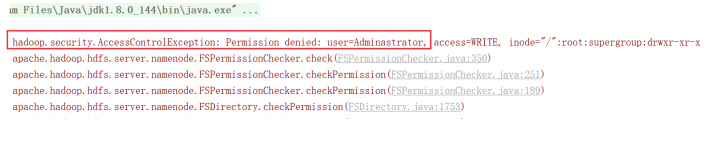
遇到问题:如果不指定操作HDFS集群的用户信息,默认是获取当前操作系统的用户信息,出现权限被拒绝的问题。
hdfs的文件权限机制与linux系统的文件权限机制类似!!
r:read w:write x:execute 权限x对于文件表示忽略,对于文件夹表示是否有权限访问其内容。
如果linux系统用户zhangsan使用hadoop命令创建一个文件,那么这个文件在HDFS当中的owner就是zhangsan。
HDFS文件权限的目的,防止好人做错事,而不是阻止坏人做坏事。HDFS相信你告诉我你是谁,你就是谁!!
解决方案:
1.指定用户信息获取FileSystem对象,如HdfsClient类中testMkdirs初始的内容。
2.关闭HDFS集群权限校验。
1 | vim hdfs-site.xml |
修改完成之后要分发到其它节点,同时要重启HDFS集群。
3.基于HDFS权限本身比较鸡肋的特点,我们可以彻底放弃HDFS的权限校验,如果生产环境中我们可以考虑借助kerberos以及sentry等安全框架来管理大数据集群安全。所以我们直接修改HDFS的根目录权限为777。
1 | hdfs dfs -chmod -R 777 / |
HDFS的API操作
上传文件
1 | package com.lagou.hdfs; |
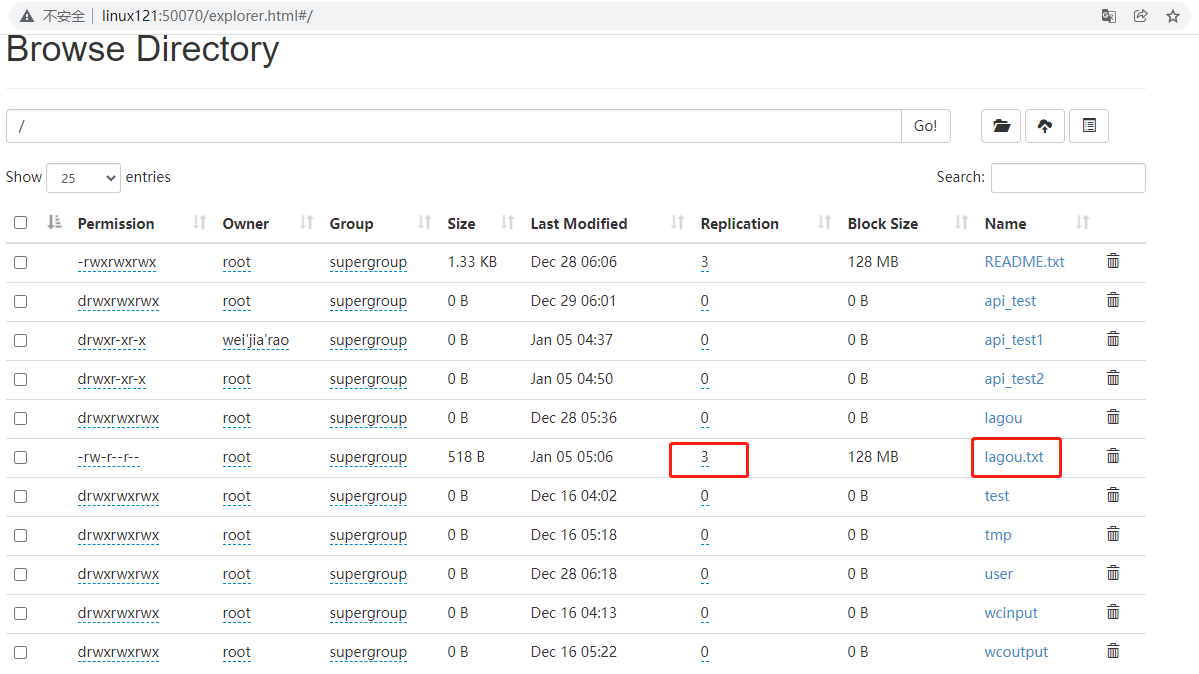
文件的备份数量是服务器的默认配置。
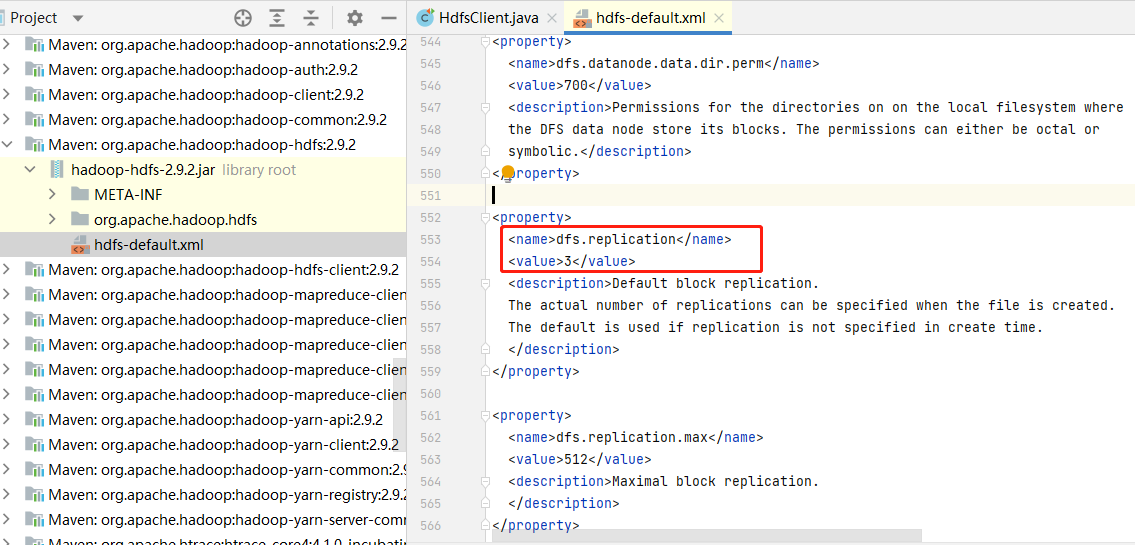
在src/main/resource下创建hdfs-site.xml,并输入以下,可以修改备份数量
1 | <?xml version="1.0" encoding="UTF-8"?> |
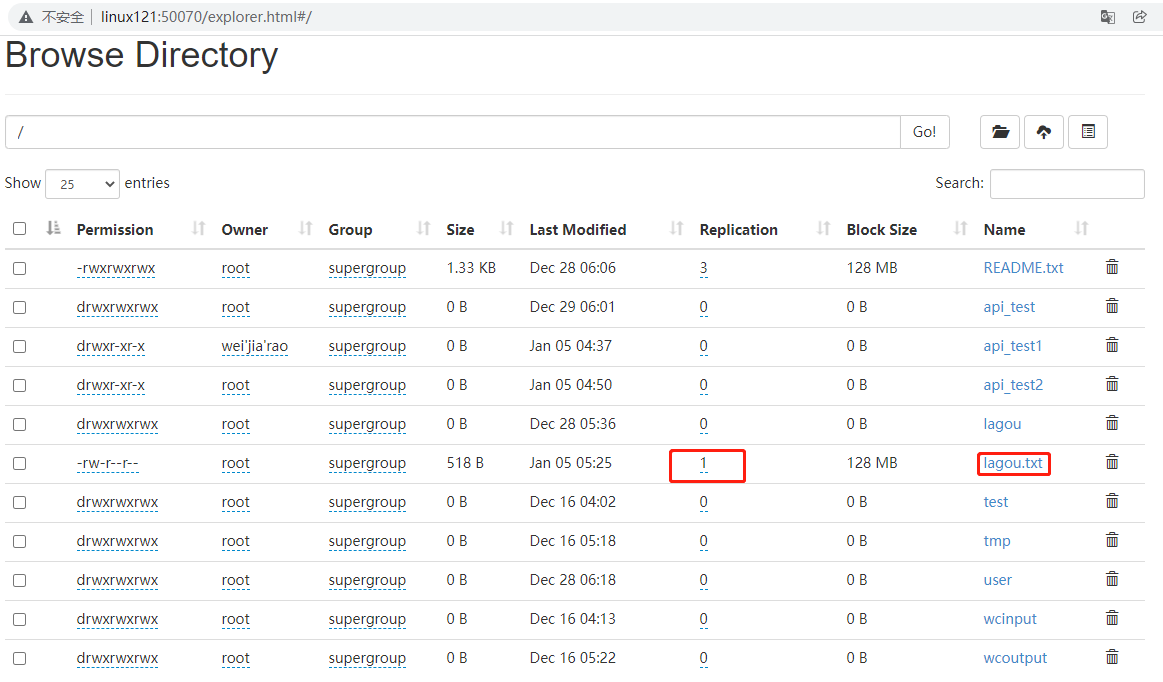
在java代码中设置的备份数量。
1 | //在上述的init方法中加入配置 |
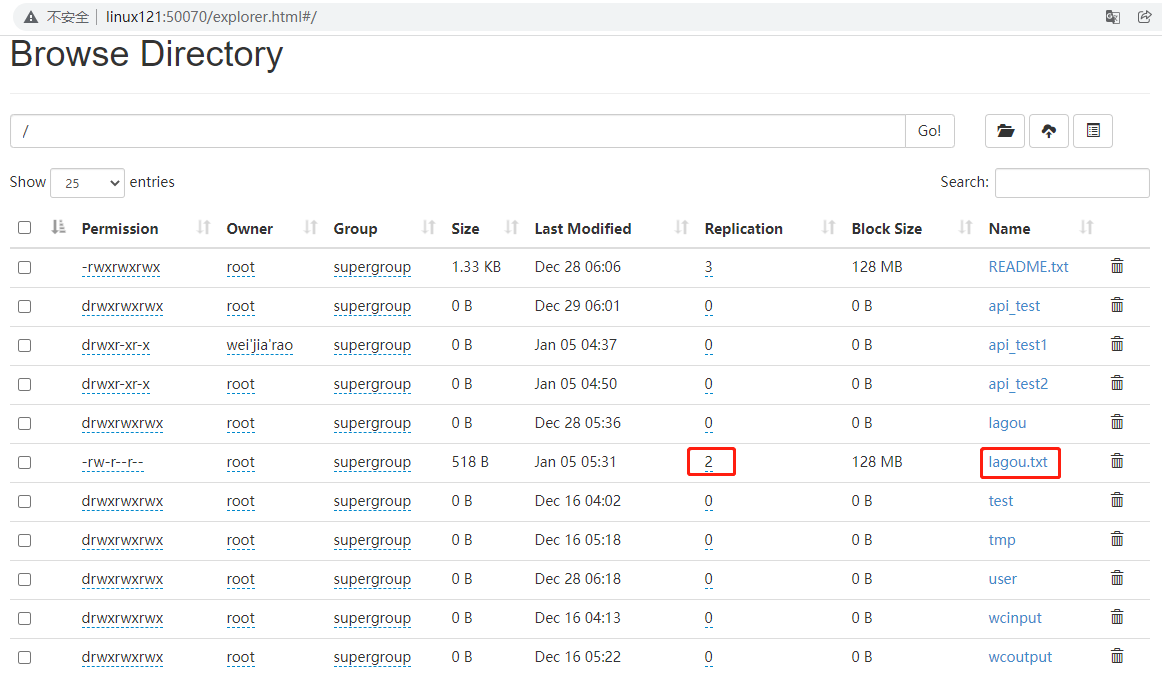
配置备份参数优先级排序:(1)代码中设置的值 >(2)用户自定义配置文件 >(3)服务器的默认配置
下载文件
在上述类中加入以下方法。
1 | //下载文件 |
删除文件/文件夹
在上述类中加入以下方法。
1 | //删除文件/文件夹 |
查看文件名称、权限、长度、块信息
在上述类中加入以下方法。
1 | //遍歷hdfs的根目录得到文件以及文件夹的信息、名称、权限、长度等 |
文件夹判断
在上述类中加入以下方法。
1 | //文件以及文件夹判断 |
I/O流操作HDFS
以上我们使用的API操作都是HDFS系统框架封装好的。我们自己也可以采用IO流的方式实现文件的上传和下载。
文件上传
把本地e盘上的lagou.txt文件上传到HDFS根目录,在上述类中加入以下方法。
1 | //使用IO流操作HDFS |
文件下载
从HDFS上下载lagou.txt文件到本地e盘上,在上述类中加入以下方法。
1 | //使用IO流操作HDFS |
seek 定位读取
将HDFS上的lagou.txt的内容在控制台输出两次,在上述类中加入以下方法。
1 | //seek定位读取hdfs指定文件:使用io流读取/lagou.txt文件并把内容输出两次,本质就是读取文件内容两次并输出 |
 wechat
wechat alipay
alipay




