
Spark安装配置
Spark安装
文档地址:http://spark.apache.org/docs/latest/
下载地址:http://spark.apache.org/downloads.html
下载Spark安装包
下载地址:https://archive.apache.org/dist/spark/
备注:不用安装scala
-
1、下载软件解压缩,移动到指定位置
1
2
3[root@Linux121 ~]# cd /opt/lagou/software/
[root@Linux121 software]# tar zxvf spark-2.4.5-bin-without-hadoop-scala-2.12.tgz
[root@Linux121 software]# mv spark-2.4.5-bin-without-hadoop-scala-2.12/ ../servers/spark-2.4.5/ -
2、设置环境变量,并使之生效
1
2
3
4
5[root@Linux121 software]# vi /etc/profile
export SPARK_HOME=/opt/lagou/servers/spark-2.4.5
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
[root@Linux121 software]# source /etc/profile -
3、修改配置
文件位置:$SPARK_HOME/conf
修改文件:slaves、spark-defaults.conf、spark-env.sh、log4j.properties
1
2
3
4
5
6[root@Linux121 software]# cd $SPARK_HOME/conf
[root@Linux121 conf]# cp slaves.template slaves
[root@Linux121 conf]# vim slaves
Linux121
Linux122
Linux1231
2
3
4
5
6
7
8
9
10[root@Linux121 conf]# cp spark-defaults.conf.template spark-defaults.conf
[root@Linux121 conf]# vim spark-defaults.conf
spark.master spark://Linux121:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://Linux121:9000/spark-eventlog
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 512m
#创建 HDFS 目录
[root@Linux121 conf]# hdfs dfs -mkdir /spark-eventlog备注:
-
spark.master。定义master节点,缺省端口号 7077
-
spark.eventLog.enabled。开启eventLog
-
spark.eventLog.dir。eventLog的存放位置
-
spark.serializer。一个高效的序列化器
-
spark.driver.memory。定义driver内存的大小(缺省1G)
1
2
3
4
5
6
7
8[root@Linux121 conf]# cp spark-env.sh.template spark-env.sh
[root@Linux121 conf]# vim spark-env.sh
export JAVA_HOME=/opt/lagou/servers/jdk1.8.0_231
export HADOOP_HOME=/opt/lagou/servers/hadoop-2.9.2
export HADOOP_CONF_DIR=/opt/lagou/servers/hadoop-2.9.2/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/opt/lagou/servers/hadoop-2.9.2/bin/hadoop classpath)
export SPARK_MASTER_HOST=Linux121
export SPARK_MASTER_PORT=7077备注:这里使用的是 spark-2.4.5-bin-without-hadoop,所以要将 Hadoop 相关 jars 的位置告诉Spark
-
-
4、将Spark软件分发到集群;修改其他节点上的环境变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15[root@Linux121 conf]# cd /opt/lagou/servers/
[root@Linux121 servers]# scp -r spark-2.4.5/ Linux122:$PWD
[root@Linux121 servers]# scp -r spark-2.4.5/ Linux123:$PWD
[root@Linux122 ~]# vi /etc/profile
# SPARK_HOME
export SPARK_HOME=/opt/lagou/servers/spark-2.4.5
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
[root@Linux122 ~]# source /etc/profile
[root@Linux123 ~]# vi /etc/profile
# SPARK_HOME
export SPARK_HOME=/opt/lagou/servers/spark-2.4.5
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
[root@Linux123 ~]# source /etc/profile -
5、启动集群
1
2[root@Linux121 servers]# cd $SPARK_HOME/sbin
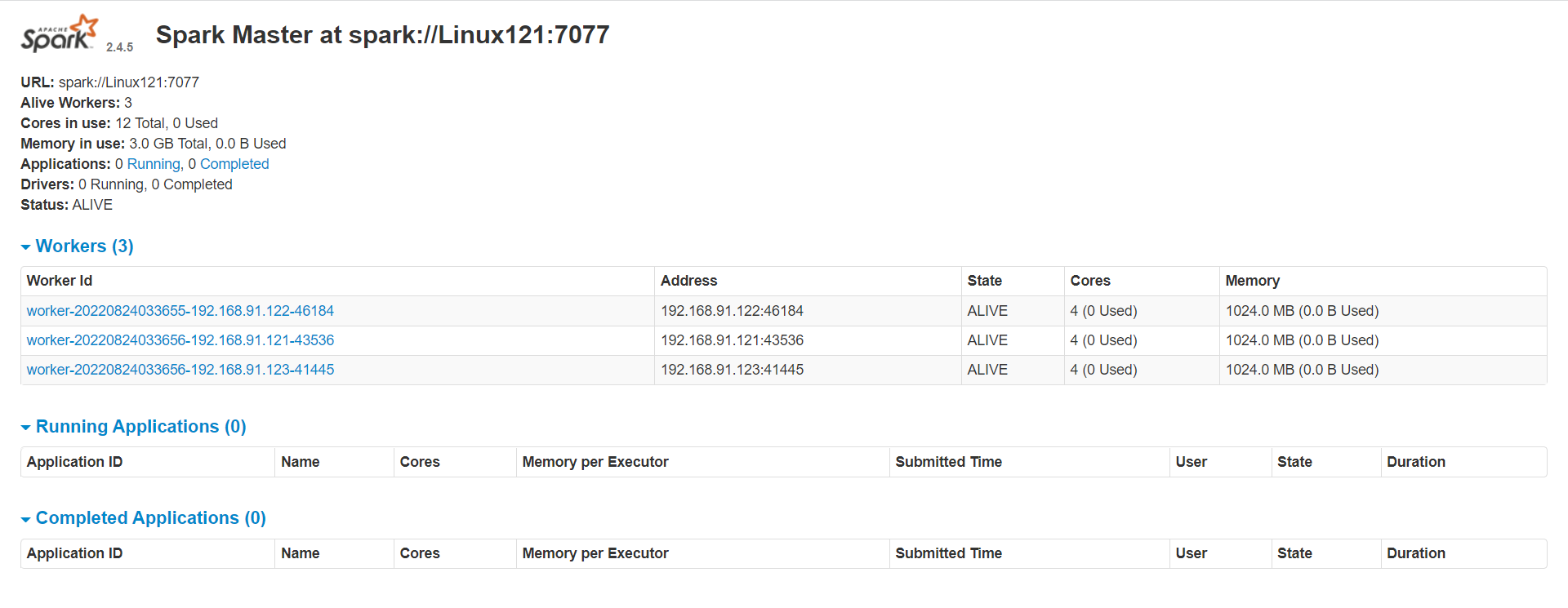
[root@Linux121 sbin]# ./start-all.sh分别在linux121、linux122、linux123上执行 jps,可以发现:
linux121:Master、Worker
linux122:Worker
linux123:Worker
此时 Spark 运行在 Standalone 模式下。
备注:在$HADOOP_HOME/sbin 及 $SPARK_HOME/sbin 下都有 start-all.sh 和 stop-all.sh 文件

在输入 start-all.sh / stop-all.sh 命令时,谁的搜索路径在前面就先执行谁,此时会产生冲突。
解决方案:
-
删除一组 start-all.sh / stop-all.sh 命令,让另外一组命令生效
-
将其中一组命令重命名。如:将 $HADOOP_HOME/sbin 路径下的命令重命名为:start-all-hadoop.sh / stop-all-hadoop.sh
-
将其中一个框架的 sbin 路径不放在 PATH 中
-
-
6、查看 Spark 的 Web 界面
在浏览器中输入:http://linux121:8080/
-
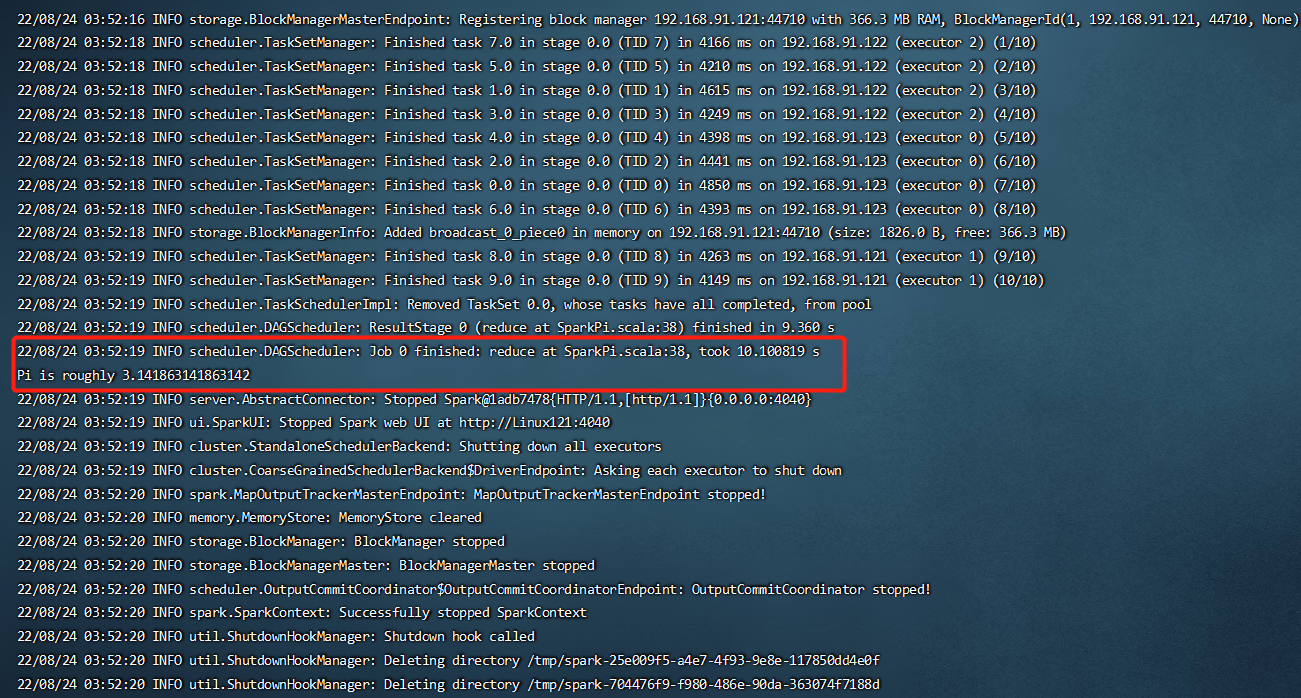
7、集群测试
1
[root@Linux121 ~]# run-example SparkPi 10
1
2
3[root@Linux121 ~]# spark-shell
// HDFS 文件
scala> val lines = sc.textFile("/wcinput/wc.txt") lines.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect().foreach(println)
Spark集群是否一定依赖hdfs?不是的,除非用到了hdfs。
Apache Spark支持多种部署模式。最简单的就是单机本地模式(Spark所有进程都运行在一台机器的JVM中)、伪分布式模式(在一台机器中模拟集群运行,相关的进程在同一台机器上)。分布式模式包括:Standalone、Yarn、Mesos。
Apache Spark支持多种部署模式:
-
本地模式。最简单的运行模式,Spark所有进程都运行在一台机器的 JVM 中
-
伪分布式模式。在一台机器中模拟集群运行,相关的进程在同一台机器上(用的非常少)
-
分布式模式。包括:Standalone、Yarn、Mesos
-
Standalone。使用Spark自带的资源调度框架
-
Yarn。使用 Yarn 资源调度框架
-
Mesos。使用 Mesos 资源调度框架
-
本地模式
本地模式部署在单机,主要用于测试或实验;最简单的运行模式,所有进程都运行在一台机器的 JVM 中;
本地模式用单机的多个线程来模拟Spark分布式计算,通常用来验证开发出来的应用程序逻辑上有没有问题;
这种模式非常简单,只需要把Spark的安装包解压后,改一些常用的配置即可使用。不用启动Spark的Master、Worker守护进程,也不用启动Hadoop的服务(除非用到HDFS)。
-
local:在本地启动一个线程来运行作业;
-
local[N]:启动了N个线程;
-
local[*]:使用了系统中所有的核;
-
local[N,M]:第一个参数表示用到核的个数;第二个参数表示容许作业失败的次数
前面几种模式没有指定M参数,其默认值都是1;
-
1、关闭相关服务
1
2
3[root@Linux121 ~]# stop-dfs.sh
[root@Linux121 ~]# stop-all.sh -
2、启动 Spark 本地运行模式
1
[root@Linux121 ~]# spark-shell --master local
备注:此时可能有错误。主要原因是配置了日志聚合(即是用来了hdfs,但hdfs服务关闭了),关闭该选项即可
1
2
3# spark-defaults.conf文件中,注释以下两行:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://linux121:9000/spark-eventlog -
3、使用 jps 检查,发现一个 SparkSubmit 进程
这个SparkSubmit进程又当爹、又当妈。既是客户提交任务的Client进程、又是Spark的driver程序、还充当着Spark执行Task的Executor角色。
-
4、执行简单的测试程序
1
scala> val lines = sc.textFile("file:///root/a.txt") lines.count
伪分布式
伪分布式模式:在一台机器中模拟集群运行,相关的进程在同一台机器上;
备注:不用启动集群资源管理服务;
-
local-cluster[N,cores,memory]
-
N模拟集群的 Slave(或worker)节点个数
-
cores模拟集群中各个Slave节点上的内核数
-
memory模拟集群的各个Slave节点上的内存大小
-
备注:参数之间没有空格,memory不能加单位
-
1、启动 Spark 伪分布式模式
1
[root@Linux121 ~]# spark-shell --master local-cluster[4,2,1024]
-
2、使用 jps 检查,发现1个 SparkSubmit 进程和4个 CoarseGrainedExecutorBackend 进程
SparkSubmit依然充当全能角色,又是Client进程,又是Driver程序,还有资源管理的作用。
4个CoarseGrainedExecutorBackend,用来并发执行程序的进程。
-
3、执行简单的测试程序
1
[root@Linux121 ~]# spark-submit --master local-cluster[4,2,1024] --class org.apache.spark.examples.SparkPi $SPARK_HOME/examples/jars/spark-examples_2.12-2.4.5.jar 10
备注:
-
local-cluster[4,2,1024],参数不要给太大,资源不够
-
这种模式少用,有Bug。SPARK-32236
-
 wechat
wechat alipay
alipay




