
Hadoop的限额与归档以及集群安全模式
HDFS文件限额配置
高级管理命令,可以输入 hdfs dfsadmin -help 查看。
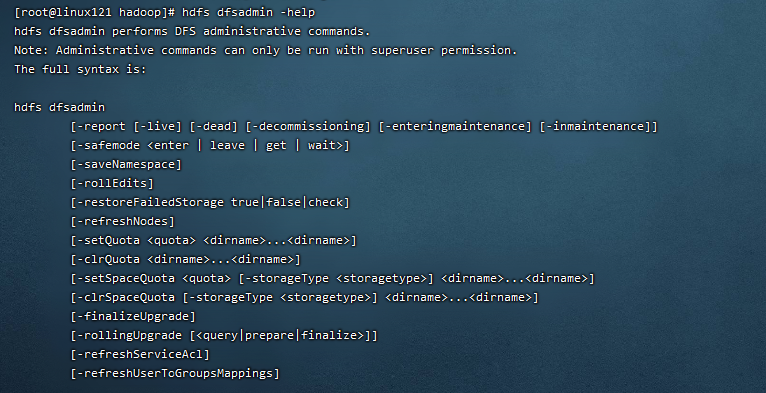
HDFS文件的限额配置允许我们以文件大小或者文件个数来限制我们在某个目录下上传的文件数量或者文件内容总量,以便达到我们类似百度网盘网盘等限制每个用户允许上传的最大的文件的量。
-
数量限额
1
2
3
4
5
6
7
8#创建hdfs文件夹hdfs
hdfs dfs -mkdir -p /user/root/lagou
#给该文件夹下面设置最多上传两个文件,上传文件,发现只能上传一个文件
hdfs dfsadmin -setQuota 2 /user/root/lagou
#清除文件数量限制
hdfs dfsadmin -clrQuota /user/root/lagou -
空间大小限额
1
2
3
4
5
6
7
8
9
10
11#限制空间大小4KB
hdfs dfsadmin -setSpaceQuota 4k /user/root/lagou
#上传超过4Kb的文件大小上去提示文件超过限额
hdfs dfs -put /export/softwares/xxx.tar.gz /user/root/lagou
#清除空间限额
hdfs dfsadmin -clrSpaceQuota /user/root/lagou
#查看hdfs文件限额数量
hdfs dfs -count -q -h /user/root/lagou
HDFS的安全模式
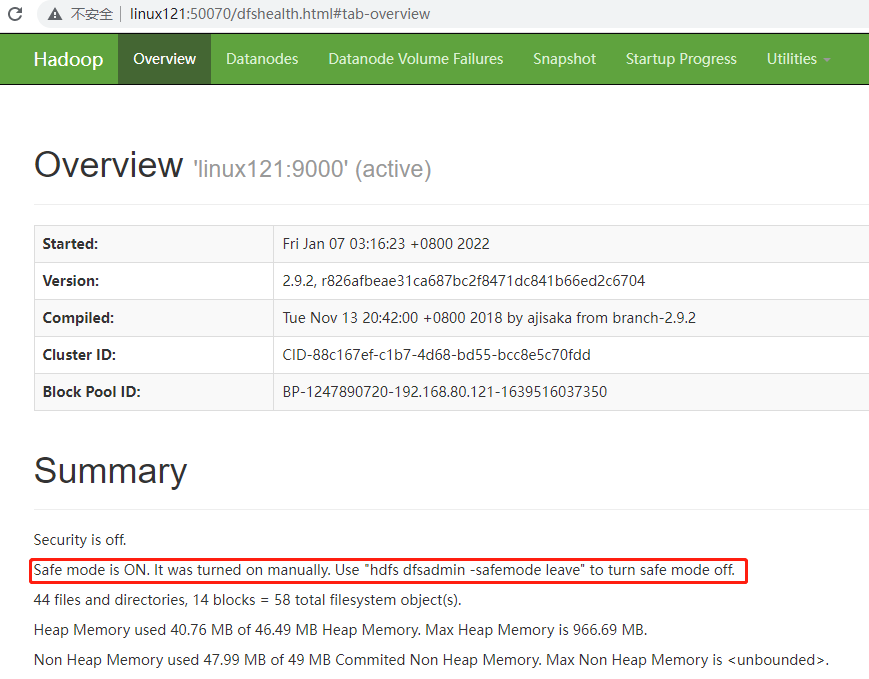
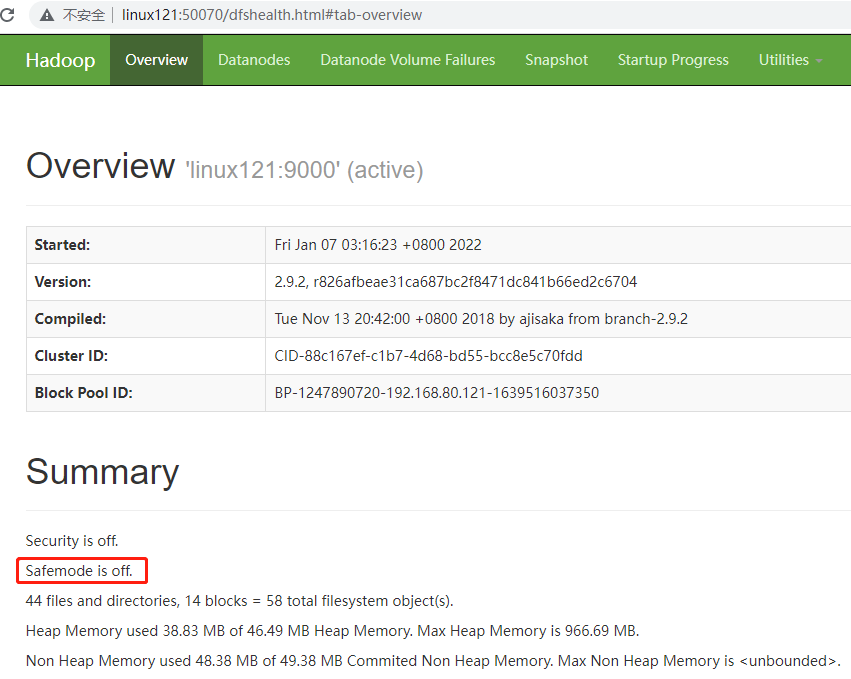
安全模式是HDFS所处的一种特殊状态,在这种状态下,文件系统只接受读数据请求,而不接受增加、删除、修改等变更请求。
在NameNode主节点启动时,HDFS首先进入安全模式,DataNode在启动的时候会向NameNode汇报可用的block等状态,当整个系统达到安全标准时,HDFS自动离开安全模式。
如果HDFS出于安全模式下,则文件block不能进行任何的副本复制操作,因此达到最小的副本数量要求是基于DataNode启动时的状态来判定的,启动时不会再做任何复制(从而达到最小副本数量要求),HDFS集群刚启动的时候,默认30S钟的时间是出于安全期的,只有过了30S之后,集群脱离了安全期,然后才可以对集群进行操作。
1 | #HDFS进入安全模式 |

1 | #HDFS离开安全模式 |
Hadoop归档技术
主要解决HDFS集群存在大量小文件的问题!!
由于大量小文件会占用NameNode的内存,因此对于HDFS来说存储大量小文件造成NameNode内存资源的浪费!
Hadoop存档文件HAR文件,是一个更高效的文件存档工具,HAR文件是由一组文件通过archive工具创建而来,在减少了NameNode的内存使用的同时,可以对文件进行透明的访问,通俗来说就是HAR文件对NameNode来说是一个文件减少了内存的浪费,对于实际操作处理文件依然是一个一个独立的文件。

-
归档命令,可以输入 hadoop archive -help 查看。

-
案例
- 启动YARN集群
1
[root@linux121 hadoop-2.9.2]$ start-yarn.sh
- 归档文件
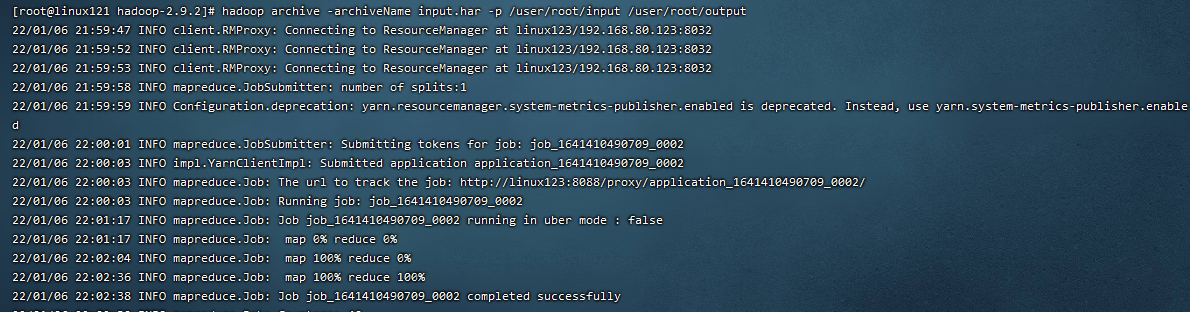
把/user/lagou/input目录里面的所有文件归档成一个叫input.har的归档文件,并把归档后文件存储到/user/lagou/output路径下。
1
[root@linux121 hadoop-2.9.2]$ hadoop archive -archiveName input.har -p /user/root/input /user/root/output
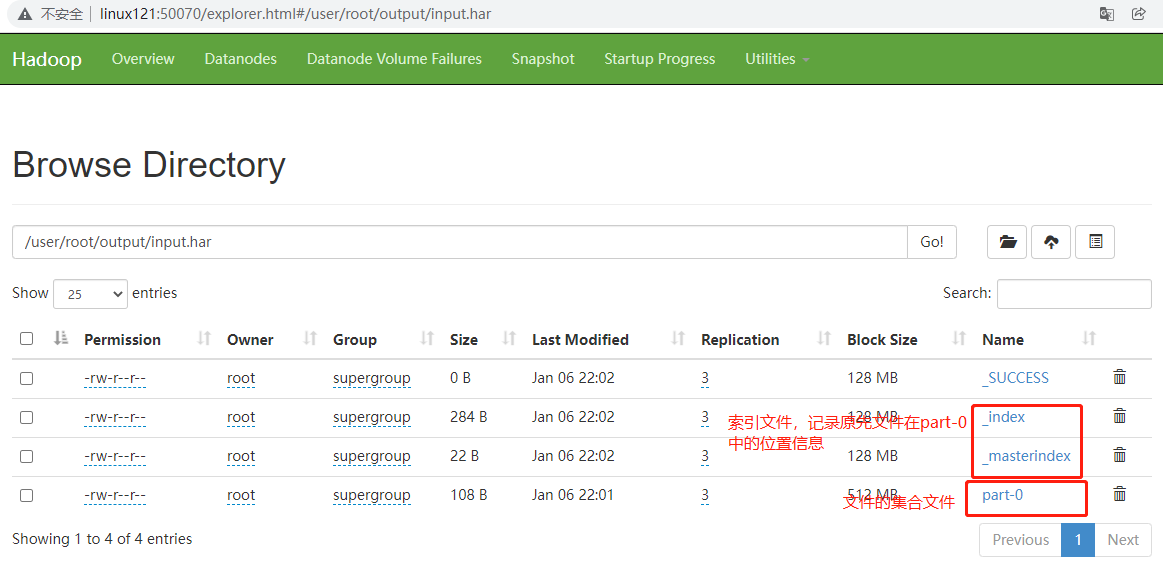
- 查看归档
1 | [root@linux121 hadoop-2.9.2]$ hdfs dfs -ls -R /user/root/output/input.har |
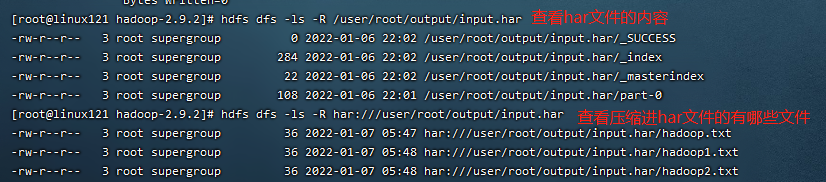
- 解归档文件
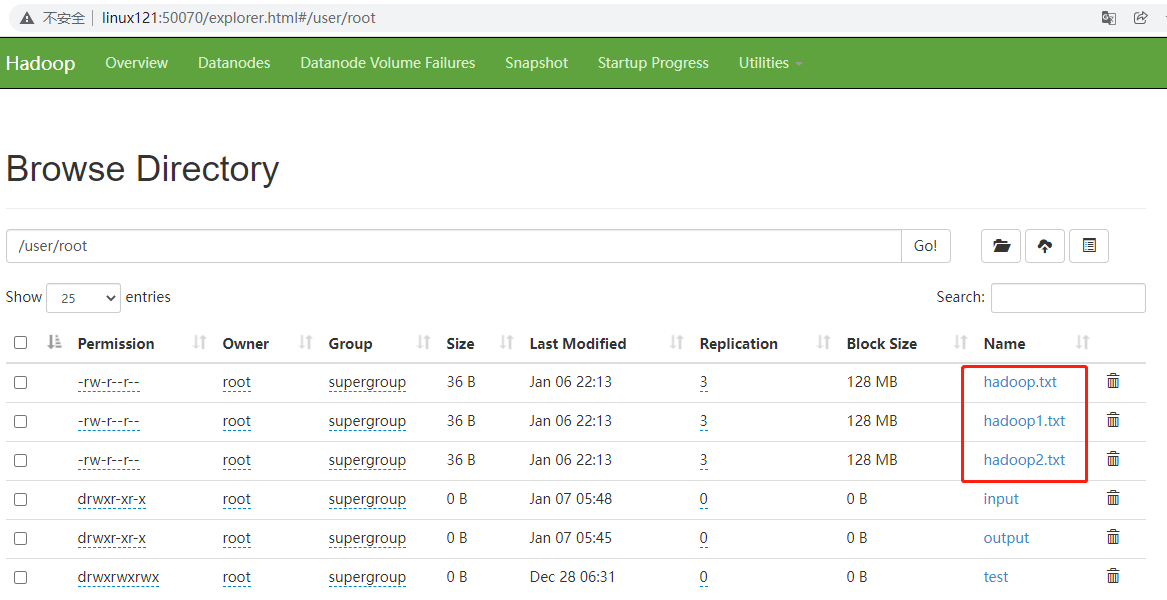
把压缩进har文件的所有内容复制到/user/root。
1 | [root@linux121 hadoop-2.9.2]$ hdfs dfs -cp har:///user/root/output/input.har/* /user/root |
 wechat
wechat alipay
alipay




