1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
| package cn.lagou.streaming.graphx
import org.apache.spark.graphx.{Edge, EdgeTriplet, Graph, VertexId, VertexRDD}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
case class User(name: String, age: Int, inDegress: Int, outDegress: Int)
object GraphXExample1 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName(this.getClass.getCanonicalName)
.setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("warn")
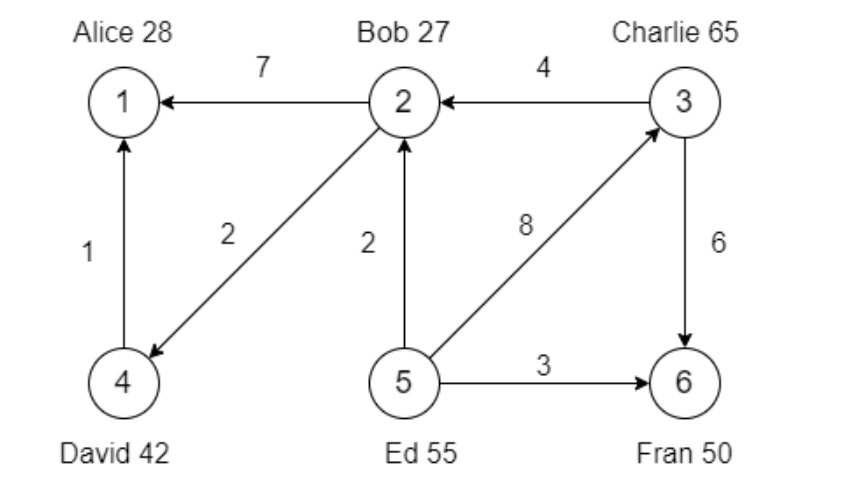
val vertexArray: Array[(VertexId, (String, Int))] = Array(
(1L, ("Alice", 28)),
(2L, ("Bob", 27)),
(3L, ("Charlie", 65)),
(4L, ("David", 42)),
(5L, ("Ed", 55)),
(6L, ("Fran", 50))
)
val vertexRDD: RDD[(VertexId, (String, Int))] = sc.makeRDD(vertexArray)
val edgeArray: Array[Edge[Int]] = Array(
Edge(2L, 1L, 7),
Edge(2L, 4L, 2),
Edge(3L, 2L, 4),
Edge(3L, 6L, 6),
Edge(4L, 1L, 1),
Edge(5L, 2L, 2),
Edge(5L, 3L, 8),
Edge(5L, 6L, 3)
)
val edgeRDD: RDD[Edge[Int]] = sc.makeRDD(edgeArray)
val graph: Graph[(String, Int), Int] = Graph(vertexRDD, edgeRDD)
graph.vertices
.filter{case (_, (_, age)) => age > 30}
.foreach(println)
graph.edges
.filter(edge => edge.attr > 5)
.foreach(println)
graph.triplets
.filter { t => t.attr > 5 }
.foreach(println)
println("属性操作一----------------------------------------------------------------------------")
val inDegress: (VertexId, Int) = graph.inDegrees
.reduce((x, y) => if (x._2 > y._2) x else y)
println(s"inDegress = $inDegress")
val outDegress: (VertexId, Int) = graph.outDegrees
.reduce((x, y) => if (x._2 > y._2) x else y)
println(s"outDegress = $outDegress")
val degress: (VertexId, Int) = graph.degrees
.reduce((x, y) => if (x._2 > y._2) x else y)
println(s"degress = $degress")
println("属性操作二----------------------------------------------------------------------------")
graph.mapVertices{case (id, (name, age)) => (id, (name, age+100))}
.vertices
.foreach(println)
graph.mapEdges(e => e.attr * 2)
.edges
.foreach(println)
println("转换操作----------------------------------------------------------------------------")
val subGraph: Graph[(String, Int), Int] = graph.subgraph(vpred = (id, vd) => vd._2 > 30)
subGraph.edges.foreach(println)
subGraph.vertices.foreach(println)
println("结构操作----------------------------------------------------------------------------")
val initailUserGraph: Graph[User, Int] = graph.mapVertices { case (id, (name, age)) =>
User(name, age, 0, 0)
}
val userGraph: Graph[User, Int] = initailUserGraph.outerJoinVertices(initailUserGraph.inDegrees) {
case (id, u, inDeg) => User(u.name, u.age, inDeg.getOrElse(0), u.outDegress)
}.outerJoinVertices(initailUserGraph.outDegrees) {
case (id, u, outDeg) => User(u.name, u.age, u.inDegress, outDeg.getOrElse(0))
}
userGraph.vertices.filter{case (_, user) => user.inDegress==user.outDegress}
.foreach(println)
println("连接操作----------------------------------------------------------------------------")
val sourceId: VertexId = 5L
val initailGraph: Graph[Double, Int] = graph.mapVertices((id, _) => if (id == sourceId) 0.0 else Double.PositiveInfinity)
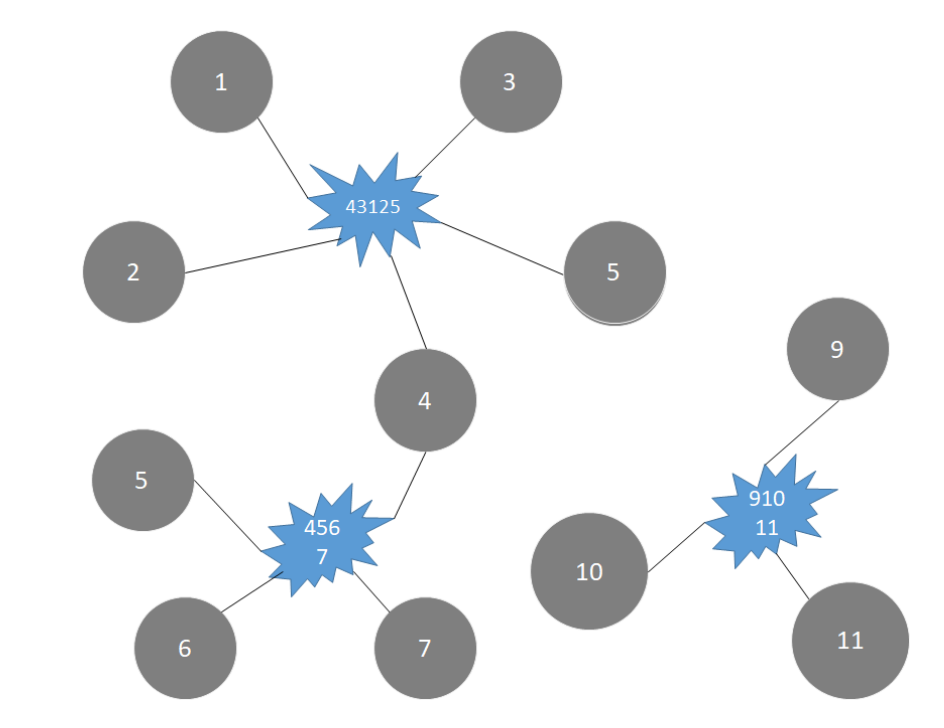
val disGraph: Graph[Double, Int] = initailGraph.pregel(Double.PositiveInfinity)(
(id, dist, newDist) => math.min(dist, newDist),
triplet => {
if (triplet.srcAttr + triplet.attr < triplet.dstAttr) {
Iterator((triplet.dstId, triplet.srcAttr + triplet.attr))
} else
Iterator.empty
},
(dista, distb) => math.min(dista, distb)
)
disGraph.vertices.foreach(println)
println("聚合操作----------------------------------------------------------------------------")
sc.stop()
}
}
|


 wechat
wechat alipay
alipay
