
MapReduce中的排序
排序是MapReduce框架中最重要的操作之一。
MapTask和ReduceTask均会对数据按照key进行排序。该操作属于Hadoop的默认行为。任何应用程序中的数据均会被排序,而不管逻辑.上是否需要。默认排序是按照字典顺序排序,且实现该排序的方法是快速排序。
-
MapTask它会将处理的结果暂时放到环形缓冲区中,当环形缓冲区使用率达到一定阈值后,再对缓冲区中的数据进行一次快速排序,并将这些有序数据溢写到磁盘上,溢写完毕后,它会对磁盘上所有文件进行归并排序。
-
ReduceTask 当所有数据拷贝完毕后,ReduceTask统-对内存和磁盘上的所有数据进行一次归并排序。
- 部分排序.
MapReduce根据输入记录的键对数据集排序。保证输出的每个文件内部有序。
- 全排序
最终输出结果只有一个文件,且文件内部有序。实现方式是只设置- -个ReduceTask。但该方法在处理大型文件时效率极低,因为- -台机器处理所有文件,完全丧失了MapReduce所提供的并行架构。
- 辅助排序: ( GroupingComparator分组)
在Reduce端对key进行分组。应用于:在接收的key为bean对象时,想让一个或几个字段相同(全部
字段比较不相同)的key进入到同一个reduce方法时,可以采用分组排序。
- 二次排序
在自定义排序过程中,如果compareTo中的判断条件为两个即为二次排序。
WritableComparable
Bean对象如果作为Map输出的key时,需要实现WritableComparable接口并重写compareTo方法指定排序规则。
全排序
基于统计的播放时长案例的输出结果对总时长进行排序。实现全局排序只能设置一个ReduceTask!!
播放时长案例输出结果
1 | 00fdaf3 33180 33420 00fdaf3 66600 |
需求分析
如何设计map()方法输出的key,value
MR框架中shuffle阶段的排序是默认行为,不管你是否需要都会进行排序。
key:把所有字段封装成为一个bean对象,并且指定bean对象作为key输出,如果作为key输出,需要实现排序接口,指定自己的排序规则;
在博客MapReduce编程规范及示例编写中maven工程wordcount里编写案例。
-
创建SpeakBean对象,Bean对象实现WritableComparable接口
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112package com.lagou.mr.sort;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.util.Objects;
//因为这个类的实例对象要作为map输出的key,所以要实现writablecomparalbe接口
public class SpeakBean implements WritableComparable<SpeakBean> {
//定义属性
private Long selfDrutation;//自有内容播放时长
private Long thirdPartDuration;//第三方内容播放时长
private String deviceId;//设备id
private Long sumDuration;//总时长
//准备构造方法
public SpeakBean() {
}
public SpeakBean(Long selfDrutation, Long thirdPartDuration, String deviceId, Long sumDuration) {
this.selfDrutation = selfDrutation;
this.thirdPartDuration = thirdPartDuration;
this.deviceId = deviceId;
this.sumDuration = sumDuration;
}
public Long getSelfDrutation() {
return selfDrutation;
}
public void setSelfDrutation(Long selfDrutation) {
this.selfDrutation = selfDrutation;
}
public Long getThirdPartDuration() {
return thirdPartDuration;
}
public void setThirdPartDuration(Long thirdPartDuration) {
this.thirdPartDuration = thirdPartDuration;
}
public String getDeviceId() {
return deviceId;
}
public void setDeviceId(String deviceId) {
this.deviceId = deviceId;
}
public Long getSumDuration() {
return sumDuration;
}
public void setSumDuration(Long sumDuration) {
this.sumDuration = sumDuration;
}
//序列化方法
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(selfDrutation);
out.writeLong(thirdPartDuration);
out.writeUTF(deviceId);
out.writeLong(sumDuration);
}
//反序列化方法
@Override
public void readFields(DataInput in) throws IOException {
this.selfDrutation = in.readLong();
this.thirdPartDuration = in.readLong();
this.deviceId = in.readUTF();
this.sumDuration = in.readLong();
}
//指定排序规则,我们希望按照总时长进行排序
@Override
public int compareTo(SpeakBean o) { //返回值三种:0:相等 1:小于 -1:大于
System.out.println("compareTo 方法执行了。。。");
//指定按照bean对象的总时长字段的值进行比较
if (this.sumDuration > o.sumDuration) {
return -1;
} else if (this.sumDuration < o.sumDuration) {
return 1;
} else {
return 0; //加入第二个判断条件,二次排序
}
}
@Override
public boolean equals(Object o) {
System.out.println("equals方法执行了。。。");
return super.equals(o);
}
@Override
public int hashCode() {
return Objects.hash(getSelfDrutation(), getThirdPartDuration(), getDeviceId(), getSumDuration());
}
@Override
public String toString() {
return selfDrutation +
"\t" + thirdPartDuration +
"\t" + deviceId + '\t' +
sumDuration
;
}
} -
编写Mapper类,名称为SortMapper。
- 读取结果文件,按照制表符进行切分
- 解析出相应字段封装为SpeakBean
- SpeakBean实现WritableComparable接口重写compareTo方法
- map()方法输出kv;key–>SpeakBean,value–>NullWritable.get()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26package com.lagou.mr.sort;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.awt.image.BandCombineOp;
import java.io.IOException;
public class SortMapper extends Mapper<LongWritable, Text, SpeakBean, NullWritable> {
final SpeakBean bean = new SpeakBean();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1 读取一行文本,转为字符串,切分
final String[] fields = value.toString().split("\t");
//2 解析出各个字段封装成SpeakBean对象
bean.setDeviceId(fields[0]);
bean.setSelfDrutation(Long.parseLong(fields[1]));
bean.setThirdPartDuration(Long.parseLong(fields[2]));
bean.setSumDuration(Long.parseLong(fields[4]));
//3 SpeakBean作为key输出
context.write(bean, NullWritable.get());
}
} -
编写Reducer类,名称为SortReducer。
- 循环遍历输出
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22package com.lagou.mr.sort;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class SortReducer extends Reducer<SpeakBean, NullWritable, SpeakBean, NullWritable> {
//reduce方法的调用是相同key的value组成一个集合调用一次
/*
java中如何判断两个对象是否相等?
根据equals方法,比较还是地址值
*/
@Override
protected void reduce(SpeakBean key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
//讨论按照总流量排序这件事情,还需要在reduce端处理吗?因为之前已经利用mr的shuffle对数据进行了排序
//为了避免前面compareTo方法导致总流量相等被当成对象相等,而合并了key,所以遍历values获取每个key(bean对象)
for (NullWritable value : values) { //遍历value同时,key也会随着遍历。
context.write(key, value);
}
}
} -
编写Driver类,名称为SortDriver。
1 | package com.lagou.mr.sort; |
总结
- 自定义对象作为Map的key输出时,需要实现WritableComparable接口,排序:重写compareTo()方法,序列以及反序列化方法
- 再次理解reduce()方法的参数;reduce()方法是map输出的kv中key相同的kv中的v组成一个集合调用一次reduce()方法,选择遍历values得到所有的key.
- 默认reduceTask数量是1个;
- 对于全局排序需要保证只有一个reduceTask!!
分区排序(默认的分区规则,区内有序)
GroupingComparator
GroupingComparator是mapreduce当中reduce端的一个功能组件,主要的作用是决定哪些数据作为一组,调用一次reduce的逻辑,默认是每个不同的key,作为多个不同的组,每个组调用一次reduce逻辑,我们可以自定义GroupingComparator实现不同的key作为同一个组,调用一次reduce逻辑。
-
需求,需要求出每一个订单中成交金额最大的一笔交易。原始数据如下图
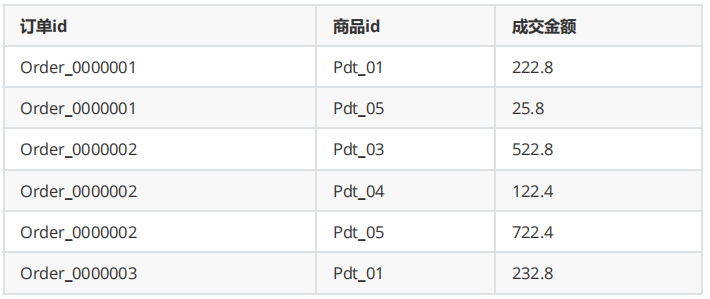
-
实现步骤
在博客MapReduce编程规范及示例编写中maven工程wordcount里编写案例。
- 编写OrderBean类
OrderBean定义两个字段,一个字段是orderId,第二个字段是金额(注意金额一定要使用Double或者DoubleWritable类型,否则没法按照金额顺序排序)。排序规则指定为先按照订单Id排序,订单Id相等再按照金额降序排!
1 | package com.lagou.mr.group; |
- 自定义分区器,编写CustomPartitioner类。
保证ID相同的订单去往同个分区最终去往同一个Reduce中
1 | package com.lagou.mr.group; |
- 自定义CustomGroupingComparator
保证id相同的订单进入一个分组中,进入分组的数据已经是按照金额降序排序。reduce()方法取出第一个即是金额最高的交易
1 | package com.lagou.mr.group; |
- 编写Mapper类,GroupMapper
读取一行文本数据,切分出每个字段;
订单id和金额封装为一个Bean对象,Bean对象的排序规则指定为先按照订单Id排序,订单Id 相等再按照金额降序排;
map()方法输出kv;key–>bean对象,value–>NullWritable.get();
1 | package com.lagou.mr.group; |
- 编写Reducer类,GroupReducer
每个reduce()方法写出一组key的第一个
1 | package com.lagou.mr.group; |
- 编写Driver类,GroupDriver
1 | package com.lagou.mr.group; |
 wechat
wechat alipay
alipay



