
MR调优
Job执行三原则
充分利用集群资源
Job运行时,尽量让所有的节点都有任务处理,这样能尽量保证集群资源被充分利用,任务的并发度达到最大。可以通过调整处理的数据量大小,以及调整map和reduce个数来实现。
-
Reduce个数的控制使用“mapreduce.job.reduces”
-
Map个数取决于使用了哪种InputFormat,默认的TextFileInputFormat将根据block的个数来分配map数(一个block一个map)。
reduce阶段尽量放在一轮
努力避免出现以下场景
-
观察Job如果大多数ReduceTask在第一轮运行完后,剩下很少甚至一个ReduceTask刚开始运行。这种情况下,这个ReduceTask的执行时间将决定了该job的运行时间。可以考虑将reduce个数减少。
-
观察Job的执行情况如果是MapTask运行完成后,只有个别节点有ReduceTask在运行。这时候集群资源没有得到充分利用,需要增加Reduce的并行度以便每个节点都有任务处理。
每个task的执行时间要合理
- 一个job中,每个MapTask或ReduceTask的执行时间只有几秒钟,这就意味着这个job的大部分时间都消耗在task的调度和进程启停上了,因此可以考虑增加每个task处理的数据大小。建议一个task处理时间为1分钟。
Shuffle调优
Shuffle阶段是MapReduce性能的关键部分,包括了从MapTaskask将中间数据写到磁盘一直到ReduceTask拷贝数据并最终放到Reduce函数的全部过程。这一块Hadoop提供了大量的调优参数。
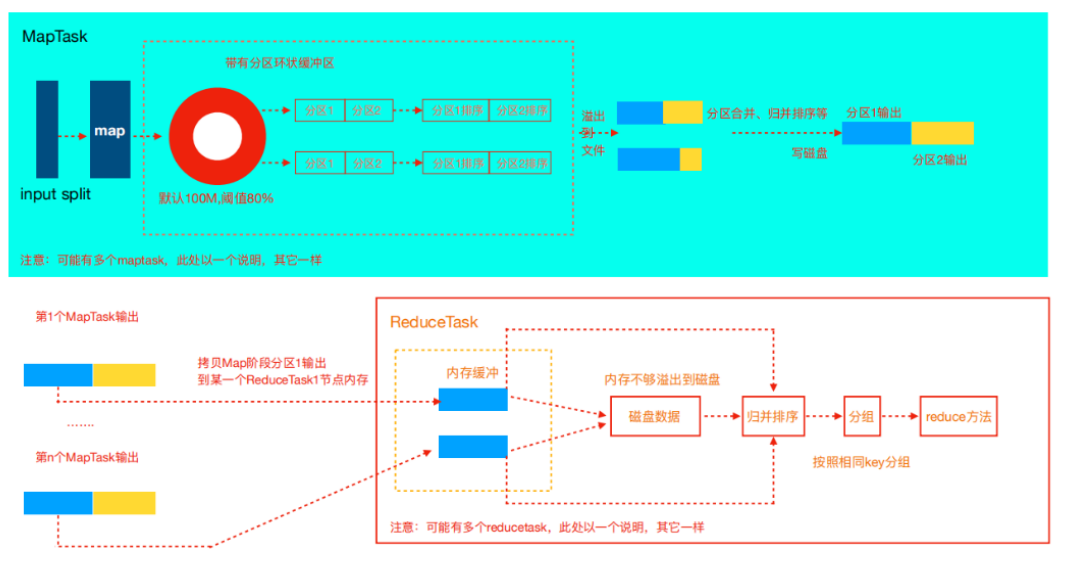
Map阶段
Map内存使用
判断Map分配的内存是否够用,可以查看运行完成的job的Counters中(历史服务器),对应的task是否发生过多次GC,以及GC时间占总task运行时间之比。通常,GC时间不应超过task运行时间的10%, 即GC time elapsed (ms)/CPU time spent (ms)<10%。
Map需要的内存还需要随着环形缓冲区的调大而对应调整。可以通过mapreduce.map.memory.mb参数进行调整。
Ma需要的CPU核数可以通过mapreduce.map.cpu.vcores参数调整。
可以看到内存默认是1G,CPU默认是1核。
如果集群资源充足建议调整:mapreduce.map.memory.mb=3G(默认1G)mapreduce.map.cpu.vcores=1(默认也是1)
环形缓冲区
Map方法执行后首先把数据写入环形缓冲区,为什么MR框架选择先写内存而不是直接写磁盘?这样的目的主要是为了减少磁盘i/o。
环形缓冲默认100M(mapreduce.task.io.sort.mb),当到达80%(mapreduce.map.sort.spill.percent)时就会溢写磁盘。每达到80%都会重写溢写到一个新的文件。
当集群内存资源充足,考虑增大mapreduce.task.io.sort.mb提高溢写的效率,而且会减少中间结果的文件数量。
建议:调整mapreduce.task.io.sort.mb=512M。当文件溢写完后,会对这些文件进行合并,默认每次合并10(mapreduce.task.io.sort.factor)个溢写的文件,建议调整mapreduce.task.io.sort.factor=64。这样可以提高合并的并行度,减少合并的次数,降低对磁盘操作的次数。
Combiner
在Map阶段,有一个可选过程,将同一个key值的中间结果合并,叫做Combiner。(一般将reduce类设置为combiner即可)通过Combine,一般情况下可以显著减少Map输出的中间结果,从而减少shuffle过程的网络带宽占用。
建议:不影响最终结果的情况下,加上Combiner!
Copy阶段
-
对Map的中间结果进行压缩,当数据量大时,会显著减少网络传输的数据量,但是也因为多了压缩和解压,带来了更多的CPU消耗。因此需要做好权衡。当任务属于网络瓶颈类型时,压缩Map中间结果效果明显。
-
在实际经验中Hadoop的运行的瓶颈一般都是IO而不是CPU,压缩一般可以10倍的减少IO操作
Reduce阶段
Reduce资源
每个Reduce资源
1 | mapreduce.reduce.memory.mb=5G(默认1G) |
Copy
ReduceTask在copy的过程中默认使用5(mapreduce.reduce.shuffle.parallelcopies参数控制)个并行度进行复制数据。
该值在实际服务器上比较小,建议调整为50-100.
溢写归并
Copy过来的数据会先放入内存缓冲区中,然后当使用内存达到一定量的时候spill磁盘。这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置。这个内存大小的控制是通过mapreduce.reduce.shuffle.input.buffer.percent(default 0.7)控制的。
shuffile在reduce内存中的数据最多使用内存量为:0.7 × maxHeap of reduce task,内存到磁盘merge的启动可以通过mapreduce.reduce.shuffle.merge.percent(default0.66)配置。
copy完成后,reduce进入归并排序阶段,合并因子默认为10(mapreduce.task.io.sort.factor参数控制),如果map输出很多,则需要合并很多趟,所以可以提高此参数来减少合并次数。
1 | mapreduce.reduce.shuffle.parallelcopies #复制数据的并行度,默认5;建议调整为50-100 |
Job调优
推测执行
集群规模很大时(几百上千台节点的集群),个别机器出现软硬件故障的概率就变大了,并且会因此延长整个任务的执行时间推测执行通过将一个task分给多台机器跑,取先运行完的那个,会很好的解决这个问题。
建议:大型集群建议开启,小集群建议关闭!集群的推测执行都是关闭的。在需要推测执行的作业执行的时候开启(即代码中通过configuration配置)
Slow Start
MapReduce的AM在申请资源的时候,会一次性申请所有的Map资源,延后申请reduce的资源,这样就能达到先执行完大部分Map再执行Reduce的目的。
当多少占比的Map执行完后开始执行Reduce。默认5%的Map跑完后开始起Reduce。
如果想要Map完全结束后执行Reduce调整该值为1,设置mapreduce.job.reduce.slowstart.completedmaps
小文件优化
HDFS:hadoop的存储每个文件都会在NameNode上记录元数据,如果同样大小的文件,文件很小的话,就会产生很多文件,造成NameNode的压力。
MR:Mapreduce中一个map默认处理一个分片或者一个小文件,如果map的启动时间都比数据处理的时间还要长,那么就会造成性能低,而且在map端溢写磁盘的时候每一个map最终会产生reduce数量个数的中间结果,如果map数量特别多,就会造成临时文件很多,而且在reduce拉取数据的时候增加磁盘的IO。
如何处理小文件?
-
从源头解决,尽量在HDFS上不存储小文件,也就是数据上传HDFS的时候就合并小文件
-
通过运行MR程序合并HDFS上已经存在的小文件
-
MR计算的时候可以使用CombineTextInputFormat来降低MapTask并行度
数据倾斜
MR是一个并行处理的任务,整个Job花费的时间是作业中所有Task最慢的那个了。
为什么会这样呢?为什么会有的Task快有的Task慢?
-
每个Reduce处理的数据量不是同一个级别的,所有数据量少的Task已经跑完了,数据量大的Task则需要更多时间。
-
有可能就是某些作业所在的NodeManager有问题或者container有问题,导致作业执行缓慢。
那么为什么会产生数据倾斜呢?
数据本身就不平衡,所以在默认的hashpartition时造成分区数据不一致问题
那如何解决数据倾斜的问题呢?
-
默认的是hash算法进行分区,我们可以尝试自定义分区,修改分区实现逻辑,结合业务特点,使得每个分区数据基本平衡
-
可以尝试修改分区的键,让其符合hash分区,并且使得最后的分区平衡,比如在key前加随机数n-key。
-
抽取导致倾斜的key对应的数据单独处理。
注意: 以上一、二两种并不能完全解决数据倾斜,但是调整到相对不倾斜即可。三能完全解决数据倾斜,但是增加了开发难度,工作量加大。
 wechat
wechat alipay
alipay



