
RDD编程之持久化-缓存与容错机制Checkpoint
RDD持久化/缓存
涉及到的算子:persist、cache、unpersist;都是 Transformation
缓存是将计算结果写入不同的介质,用户定义可定义存储级别(存储级别定义了缓存存储的介质,目前支持内存、堆外内存、磁盘);
通过缓存,Spark避免了RDD上的重复计算,能够极大地提升计算速度;
RDD持久化或缓存,是Spark最重要的特征之一。可以说,缓存是Spark构建迭代式算法和快速交互式查询的关键因素;
Spark速度非常快的原因之一,就是在内存中持久化(或缓存)一个数据集。当持久化一个RDD后,每一个节点都将把计算的分片结果保存在内存中,并在对此数据集(或者衍生出的数据集)进行的其他动作(Action)中重用。这使得后续的动作变得更加迅速;
使用persist()方法对一个RDD标记为持久化。之所以说“标记为持久化”,是因为出现persist()语句的地方,并不会马上计算生成RDD并把它持久化,而是要等到遇到第一个行动操作触发真正计算以后,才会把计算结果进行持久化;
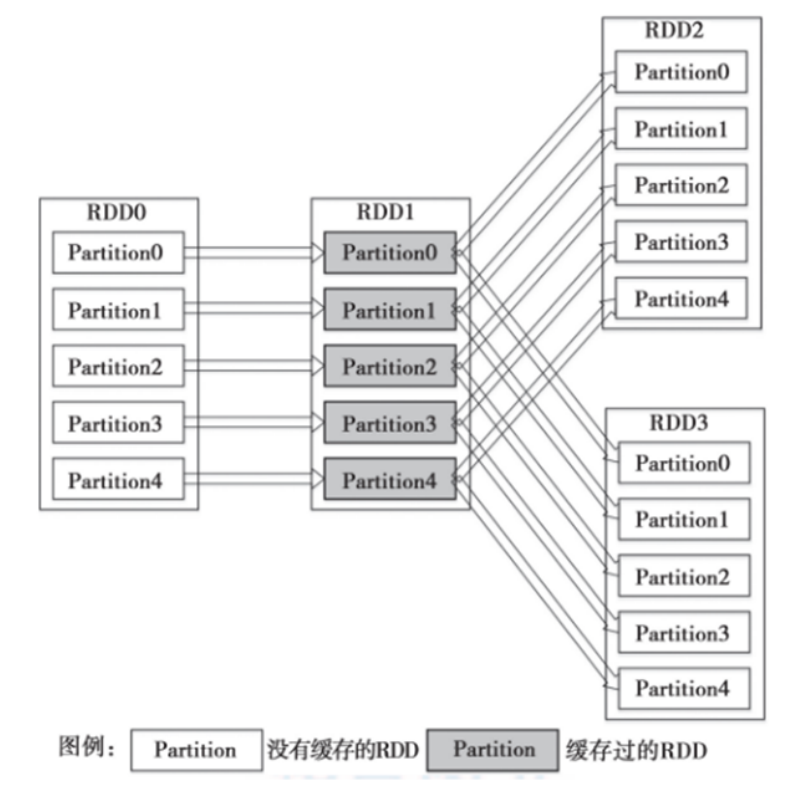
通过persist()或cache()方法可以标记一个要被持久化的RDD,持久化被触发,RDD将会被保留在计算节点的内存中并重用;
什么时候缓存数据,需要对空间和速度进行权衡。一般情况下,如果多个动作需要用到某个 RDD,而它的计算代价又很高,那么就应该把这个 RDD 缓存起来;
**缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除。**RDD的缓存的容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列的转换,丢失的数据会被重算。RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
persist()的参数可以指定持久化级别参数;
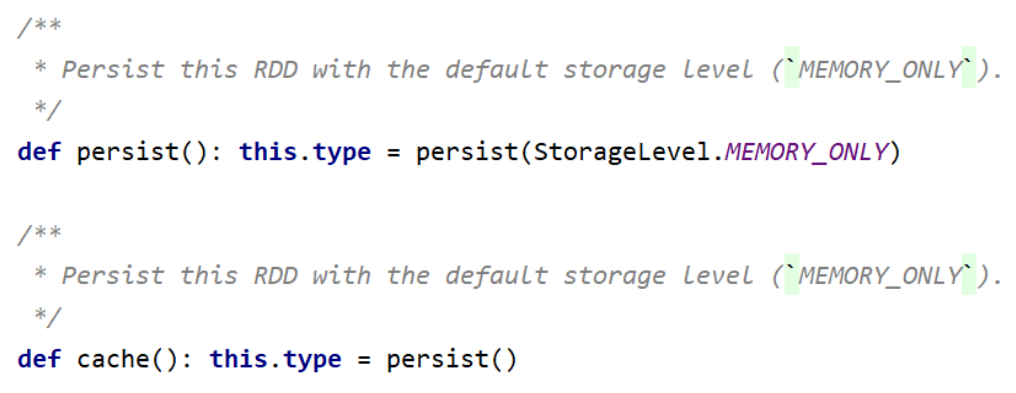
使用cache()方法时,会调用persist(MEMORY_ONLY),即:
1 | cache() == persist(StorageLevel.Memeory_ONLY) |
使用unpersist()方法手动地把持久化的RDD从缓存中移除;

1 | object StorageLevel { |
| 存储级别 | 描述 |
|---|---|
| MEMORY_ONLY | 将RDD 作为反序列化的对象存储JVM 中。如果RDD不能被内存装下,一些分区将不会被缓存,并且在需要的时候被重新计算。 默认的缓存级别 |
| MEMORY_AND_DISK | 将RDD 作为反序列化的的对象存储在JVM 中。如果RDD不能被与内存装下,超出的分区将被保存在硬盘上,并且在需要时被读取 |
| MEMORY_ONLY_SER | 将RDD 作为序列化的的对象进行存储(每一分区一个字节数组)。 通常来说,这比将对象反序列化的空间利用率更高,读取时会比较占用CPU |
| MEMORY_AND_DISK_SER | 与MEMORY_ONLY_SER 相似,但是把超出内存的分区将存储在硬盘上而不是在每次需要的时候重新计算 |
| DISK_ONLY | 只将RDD 分区存储在硬盘上 |
| DISK_ONLY_2等带2的 | 与上述的存储级别一样,但是将每一个分区都复制到集群的两个结点上 |
cache RDD 以 分区为单位;程序执行完毕后,系统会清理cache数据;
1 | scala> val list = List("Hadoop","Spark","Hive") |
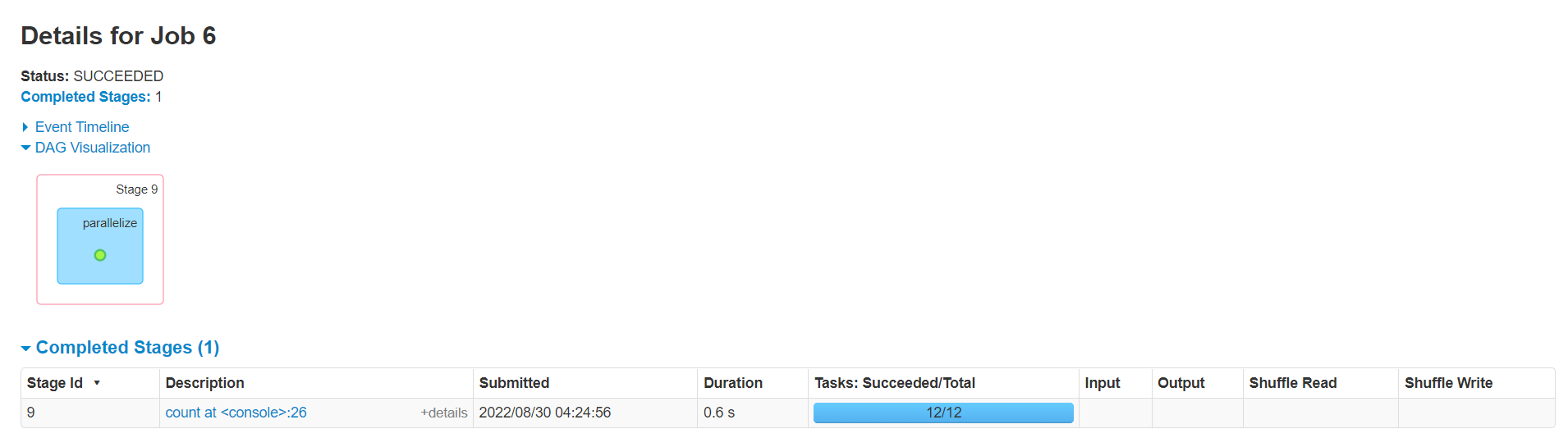
被缓存的RDD在DAG图中有一个绿色的圆点。
RDD容错机制Checkpoint
涉及到的算子:checkpoint;也是 Transformation
Spark中对于数据的保存除了持久化操作之外,还提供了检查点的机制;
**检查点本质是通过将RDD写入高可靠的磁盘,主要目的是为了容错。**检查点通过将数据写入到HDFS文件系统实现了RDD的检查点功能。
Lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销。
cache 和 checkpoint 是有显著区别的,缓存把 RDD 计算出来然后放在内存中,但是 RDD 的依赖链不能丢掉, 当某个点某个 executor 宕了,上面 cache 的RDD就会丢掉, 需要通过依赖链重放计算。不同的是,checkpoint 是把 RDD 保存在 HDFS 中,是多副本可靠存储,此时依赖链可以丢掉,所以斩断了依赖链。
以下场景适合使用检查点机制:
-
DAG中的Lineage过长,如果重算,则开销太大
-
在宽依赖上做 Checkpoint 获得的收益更大
与cache类似 checkpoint 也是 lazy 的。
1 | scala> val rdd1 = sc.parallelize(1 to 100000) |
备注:checkpoint的文件作业执行完毕后不会被删除
 wechat
wechat alipay
alipay




