
Spark安装集群模式
集群模式–Standalone模式
参考:http://spark.apache.org/docs/latest/spark-standalone.html
-
分布式部署才能真正体现分布式计算的价值
-
与单机运行的模式不同,这里必须先启动Spark的Master和Worker守护进程;关闭 yarn 对应的服务
-
不用启动Hadoop服务,除非要使用HDFS的服务
使用jps检查,可以发现:
-
linux121:Master、Worker
-
linux122:Worker
-
linux123:Worker
使用浏览器查看(linux121:8080)
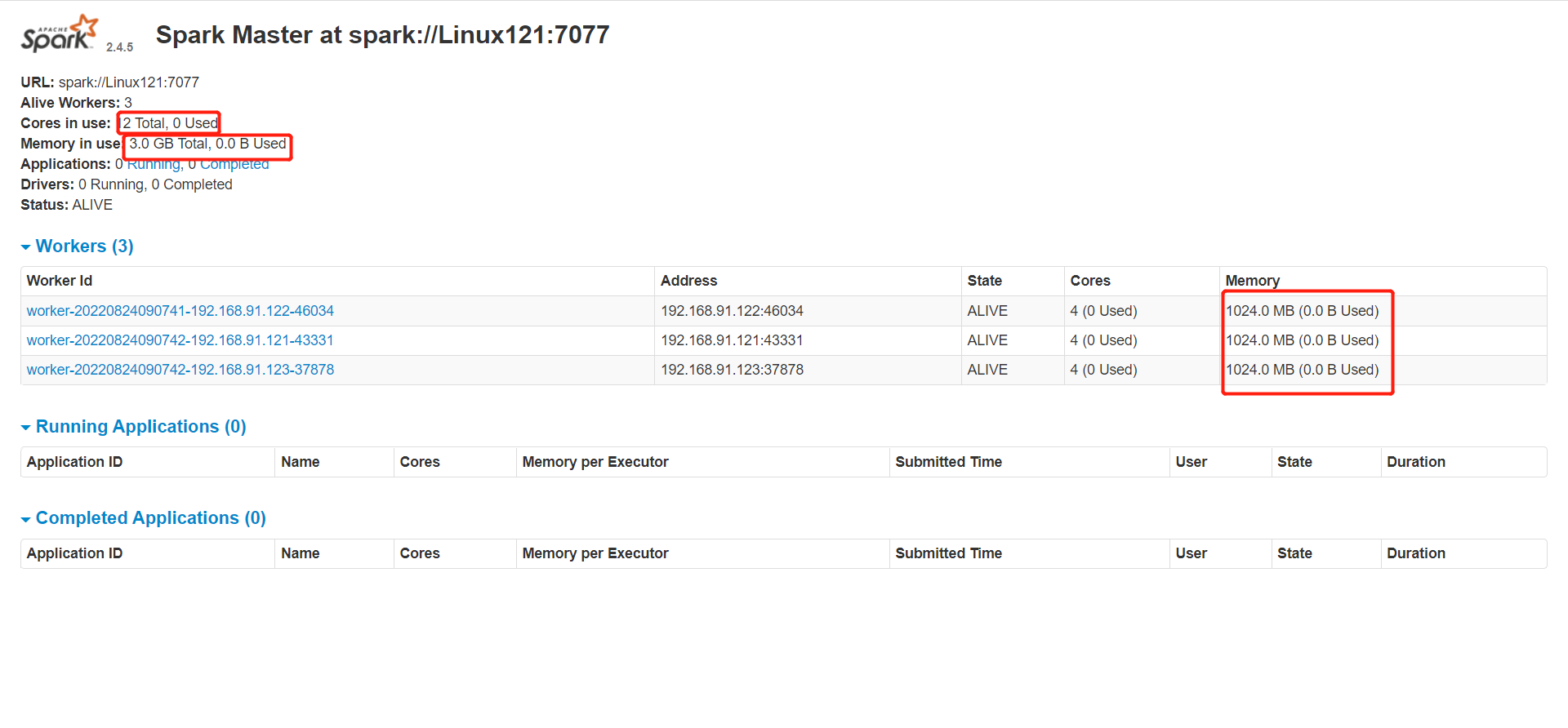
Standalone 配置
-
sbin/start-master.sh / sbin/stop-master.sh
启停主节点
-
sbin/start-slaves.sh / sbin/stop-slave.sh
启停所有从节点
-
sbin/start-slave.sh / sbin/stop-slaves.sh
启停当前机器的从节点
-
sbin/start-all.sh / sbin/stop-all.sh
启停主节点和从节点
备注:./sbin/start-slave.sh [options];启动节点上的worker进程,调试中较为常用
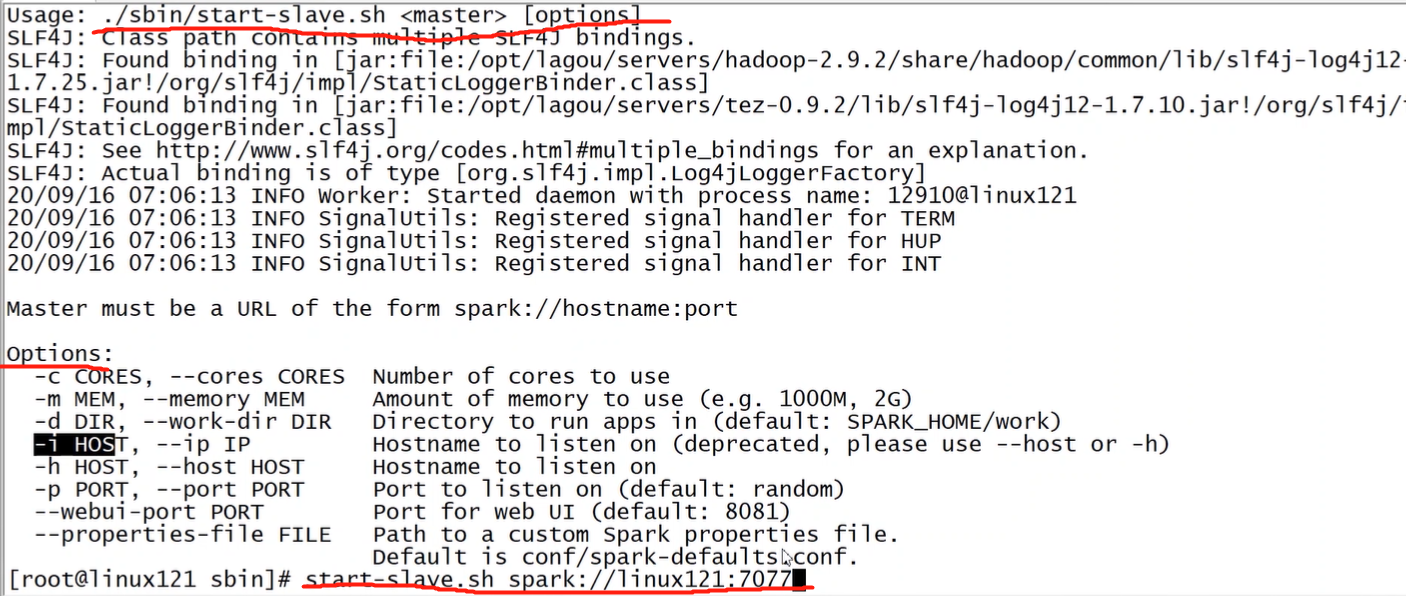
在 spark-env.sh 中定义:
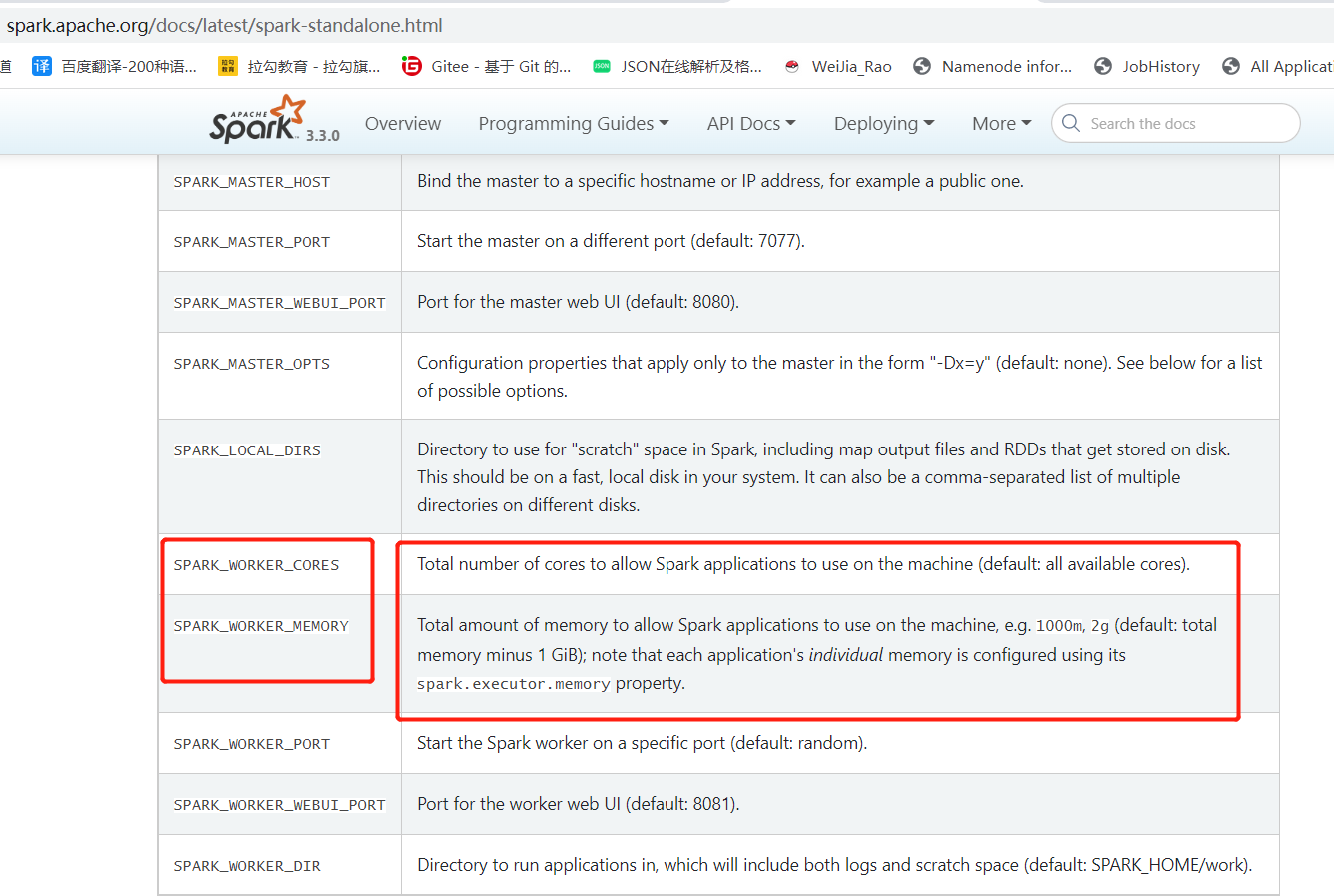
测试在 spark-env.sh 中增加参数,分发到集群,重启服务:
1 | export SPARK_WORKER_CORES=10 |
在浏览器中观察集群状态,测试完成后将以上两个参数分别改为2、2g,重启服务。
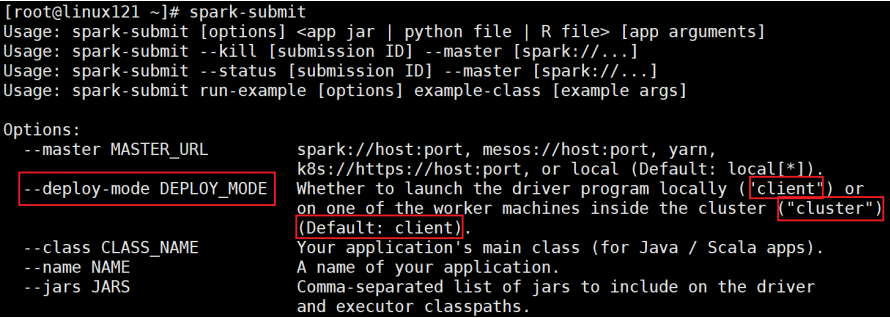
运行模式(cluster / client)
最大的区别:Driver运行在哪里;
client是缺省的模式,能看见返回结果,适合调试;cluster与此相反;
-
Client模式(缺省)。Driver运行在提交任务的Client,此时可以在Client模式下,看见应用的返回结果,适合交互、调试
-
Cluster模式。Driver运行在Spark集群中,看不见程序的返回结果,合适生产环境
-
测试1(Client 模式):
1
[root@Linux121 ~]# spark-submit --class org.apache.spark.examples.SparkPi $SPARK_HOME/examples/jars/spark-examples_2.11-2.4.5.jar 1000
再次使用 jps 检查集群中的进程:
-
Master进程做为cluster manager,管理集群资源
-
Worker 管理节点资源
-
SparkSubmit 做为Client端,运行 Driver 程序。Spark Application执行完成,进程终止
-
CoarseGrainedExecutorBackend,运行在Worker上,用来并发执行应用程序
-
-
测试2(Cluster 模式):
1
[root@Linux121 ~]# spark-submit --class org.apache.spark.examples.SparkPi --deploy-mode cluster $SPARK_HOME/examples/jars/spark-examples_2.11-2.4.5.jar 1000
-
SparkSubmit 进程会在应用程序提交给集群之后就退出
-
Master会在集群中选择一个 Worker 进程生成一个子进程 DriverWrapper 来启动 Driver 程序
-
Worker节点上会启动 CoarseGrainedExecutorBackend
-
DriverWrapper 进程会占用 Worker 进程的一个core(缺省分配1个core,1G内存)
-
应用程序的结果,会在执行 Driver 程序的节点的 stdout 中输出,而不是打印在屏幕上
-
在启动 DriverWrapper 的节点上,进入 $SPARK_HOME/work/,可以看见类似 driver-20200810233021-0000 的目录,这个就是 driver 运行时的日志文件,进入该目录,会发现:
-
jar 文件,这就是移动的计算
-
stderr 运行日志
-
stdout 输出结果
History Server
1 | # spark-defaults.conf |
spark.history.retainedApplications。设置缓存Cache中保存的应用程序历史记录的个数(默认50),如果超过这个值,旧的将被删除;
缓存文件数不表示实际显示的文件总数。只是表示不在缓存中的文件可能需要从硬盘读取,速度稍有差别
前提条件:启动hdfs服务(日志写到HDFS)
启动historyserver,使用 jps 检查,可以看见 HistoryServer 进程。如果看见该进程,请检查对应的日志。
1 | [root@Linux121 ~]# $SPARK_HOME/sbin/start-history-server.sh |
web端地址:http://linux121:18080/
高可用配置
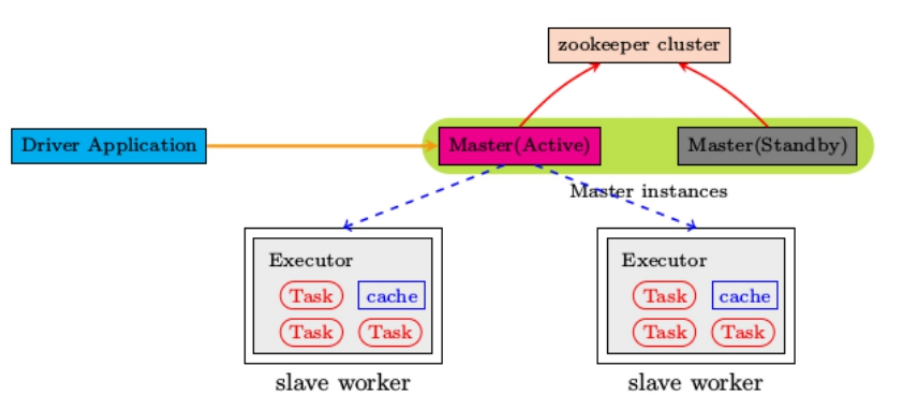
Spark Standalone集群是 Master-Slaves 架构的集群模式,和大部分的Master-Slaves结构集群一样,存着Master单点故障的问题。如何解决这个问题,Spark提供了两种方案:
-
1. 基于zookeeper的Standby Master
适用于生产模式。将 Spark 集群连接到Zookeeper,利用 Zookeeper 提供的选举和状态保存的功能,一个 Master 处于 Active 状态,其他 Master 处于Standby状态;
保证在ZK中的元数据主要是集群的信息,包括:Worker,Driver和Application以及Executors的信息;
如果Active的Master挂掉了,通过选举产生新的 Active 的 Master,然后执行状态恢复,整个恢复过程可能需要1~2分钟;
-
2. 基于文件系统的单点恢复(Single-Node Rcovery with Local File System)
主要用于开发或者测试环境。将 Spark Application 和 Worker 的注册信息保存在文件中,一旦Master发生故障,就可以重新启动Master进程,将系统恢复到之前的状态
配置步骤:
-
1、安装ZooKeeper,并启动
-
2、修改 spark-env.sh 文件,并分发到集群中
1
2
3
4
5
6
7
8
9
10
11
12[root@Linux121 ~]# cd $SPARK_HOME/conf
[root@Linux121 conf]# vim spark-env.sh
# 注释以下两行!!!
# export SPARK_MASTER_HOST=linux121
# export SPARK_MASTER_PORT=7077
# 添加以下内容
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=linux121,linux122,linux123 -Dspark.deploy.zookeeper.dir=/spark"
[root@Linux121 conf]# scp spark-env.sh Linux122:$PWD
[root@Linux121 conf]# scp spark-env.sh Linux123:$PWD备注:
-
spark.deploy.recoveryMode:可选值 Zookeeper、FileSystem、None
-
deploy.zookeeper.url:Zookeeper的URL,主机名:端口号(缺省2181)
-
deploy.zookeeper.dir:保存集群元数据信息的地址,在ZooKeeper中保存该信息
-
-
3、启动 Spark 集群(linux121)
1
[root@Linux121 conf]# $SPARK_HOME/sbin/start-all.sh
浏览器输入:http://linux121:8080/,刚开始 Master 的状态是STANDBY,稍等一会变为:RECOVERING,最终是:ALIVE
-
4、在 linux122 上启动master
1
[root@Linux122 ~]# $SPARK_HOME/sbin/start-master.sh
进入浏览器输入:http://linux122:8080/,此时 Master 的状态为:STANDBY
-
5、杀到linux121上 Master 进程,再观察 linux122 上 Master 状态,由 STANDBY => RECOVERING => ALIVE
小结:
-
配置每个worker的core、memory
-
运行模式:cluster、client;client缺省模式,有返回结果,适合调试;cluster与此相反
-
History server
-
高可用(ZK、Local Flile;在ZK中记录集群的状态)
集群模式–Yarn模式
参考:http://spark.apache.org/docs/latest/running-on-yarn.html
需要启动的服务:hdfs服务、yarn服务
需要关闭 Standalone 对应的服务(即集群中的Master、Worker进程),一山不容二虎!
在Yarn模式中,Spark应用程序有两种运行模式:二者的主要区别:Driver在哪里;
-
yarn-client。Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出
-
yarn-cluster。Driver程序运行在由RM启动的 AppMaster中,适用于生产环境
-
1、关闭 Standalon 模式下对应的服务;开启 hdfs、yarn、historyserver 服务
-
2、修改 yarn-site.xml 配置
在 $HADOOP_HOME/etc/hadoop/yarn-site.xml 中增加,分发到集群,重启 yarn服务
1
2
3
4
5
6
7
8
9
10
11
12
13
14[root@Linux121 ~]# cd $HADOOP_HOME/etc/hadoop
[root@Linux121 hadoop]# vim yarn-site.xml
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
[root@Linux121 hadoop]# scp yarn-site.xml Linux122:$PWD
[root@Linux121 hadoop]# scp yarn-site.xml Linux123:$PWD备注:
-
yarn.nodemanager.pmem-check-enabled。是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认是true
-
yarn.nodemanager.vmem-check-enabled。是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true
-
-
3、修改配置,分发到集群
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# spark-env.sh 中这一项必须要有
[root@Linux121 ~]# cd $SPARK_HOME/conf
[root@Linux121 conf]# vim spark-env.sh
export HADOOP_CONF_DIR=/opt/lagou/servers/hadoop-2.9.2/etc/hadoop
# spark-defaults.conf(以下是优化)
# 与 hadoop historyserver集成
[root@Linux121 conf]# vim spark-default.conf
spark.yarn.historyServer.address Linux121:18080
# 添加(以下是优化)
spark.yarn.jars hdfs:///spark-yarn/jars/*.jar
# 将 $SPARK_HOME/jars 下的jar包上传到hdfs
[root@Linux121 conf]# hdfs dfs -mkdir -p /spark-yarn/jars/
[root@Linux121 conf]# cd $SPARK_HOME/jars
[root@Linux121 jars]# hdfs dfs -put * /spark-yarn/jars/ -
4、测试
1
2# client
[root@Linux121 conf]# spark-submit --master yarn --deploy-mode client --class org.apache.spark.examples.SparkPi $SPARK_HOME/jars/spark-examples_2.12-2.4.5.jar 2000在提取App节点上可以看见:SparkSubmit、CoarseGrainedExecutorBackend
在集群的其他节点上可以看见:CoarseGrainedExecutorBackend
在提取App节点上可以看见:程序计算的结果(即可以看见计算返回的结果)
1
2# cluster
[root@Linux121 conf]# spark-submit --master yarn --deploy-mode cluster --class org.apache.spark.examples.SparkPi $SPARK_HOME/examples/jars/spark-examples_2.12-2.4.5.jar 2000在提取App节点上可以看见:SparkSubmit
在集群的其他节点上可以看见:CoarseGrainedExecutorBackend、ApplicationMaster(Driver运行在此)
在提取App节点上看不见最终的结果
-
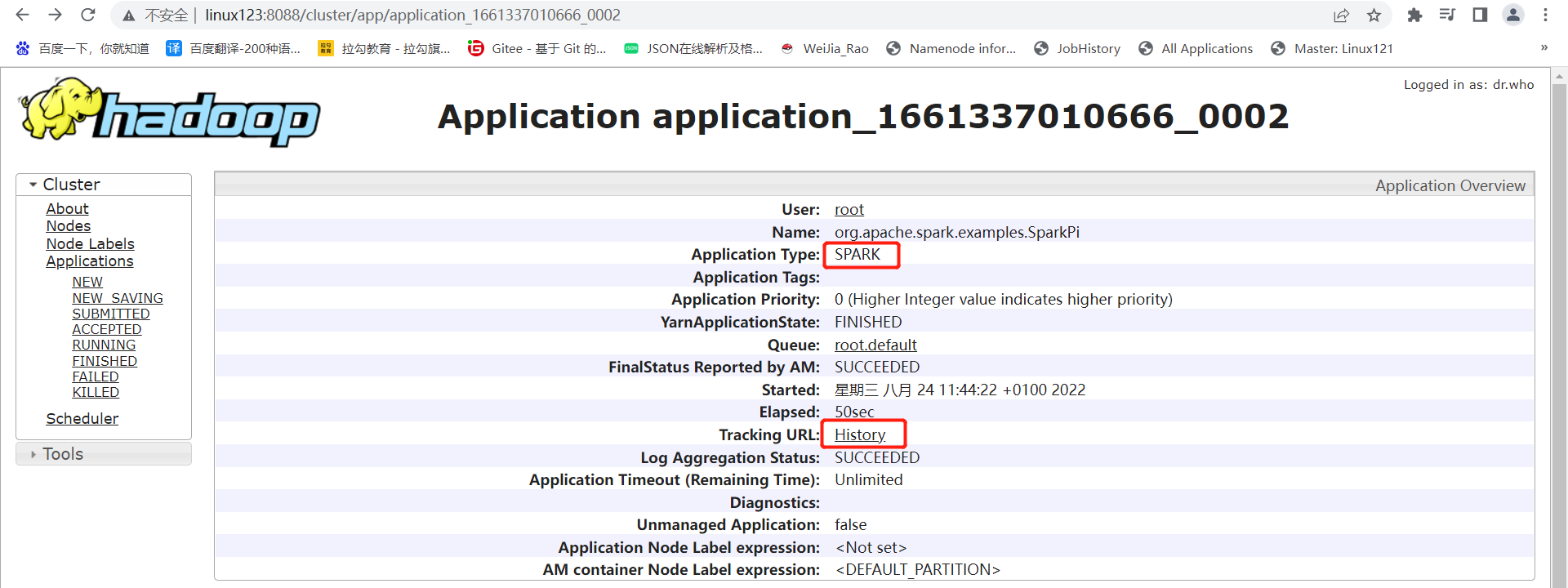
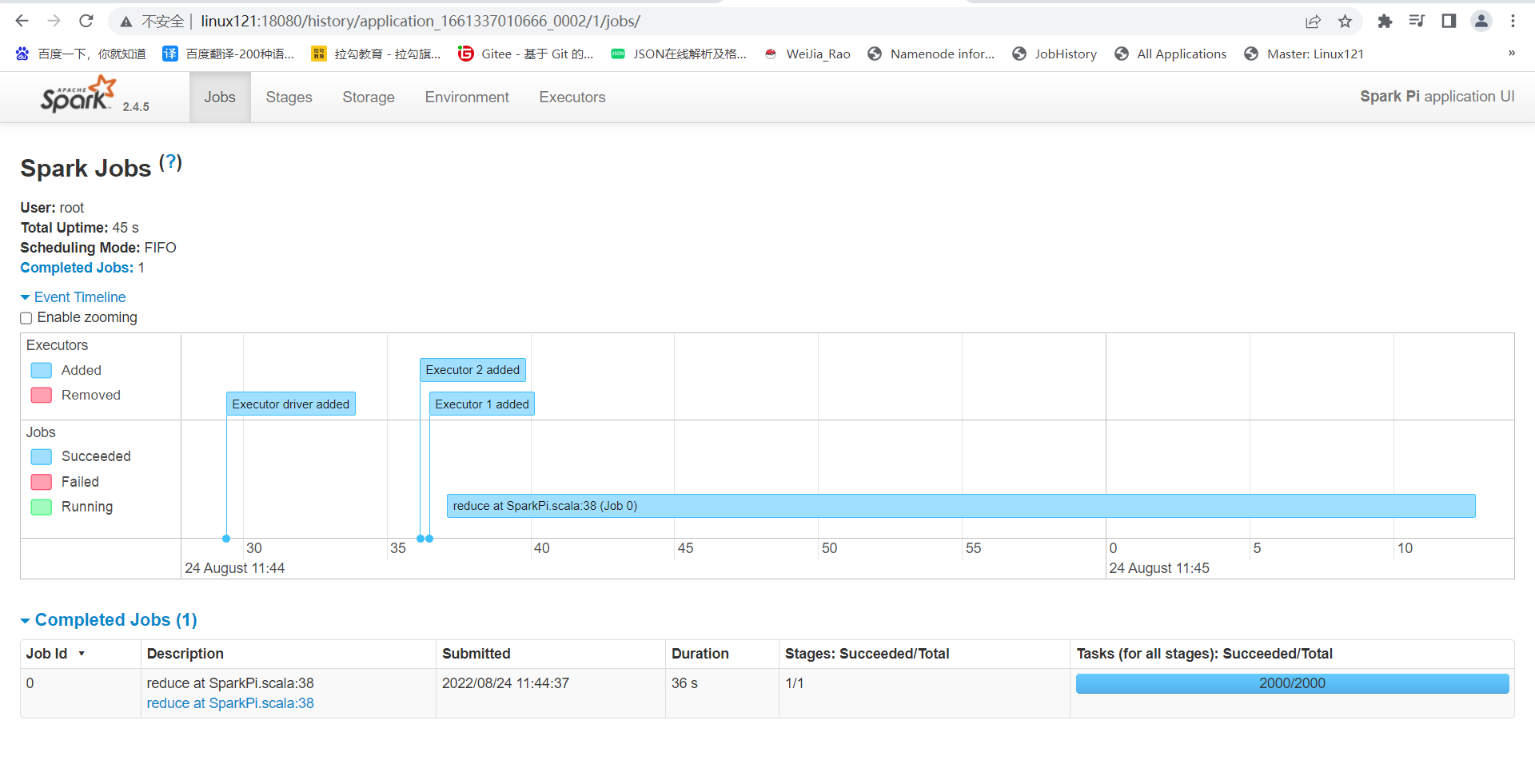
整合HistoryServer服务
前提:Hadoop的 HDFS、Yarn、HistoryServer 正常;Spark historyserver服务正常;
Hadoop:JobHistoryServer
Spark:HistoryServer
-
1、修改 spark-defaults.conf,并分发到集群
1
2
3
4
5
6
7
8
9
10# 修改spark-defaults.conf
spark.master spark://linux121:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://linux121:9000/spark-eventlog
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 512m
# 新增
spark.yarn.historyServer.address linux121:18080
spark.history.ui.port 18080 -
2、重启/启动 spark 历史服务
1
2[root@Linux121 conf]# stop-history-server.sh
[root@Linux121 conf]# start-history-server.sh -
3、提交任务
1
[root@Linux121 conf]# spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode client $SPARK_HOME/examples/jars/spark-examples_2.12-2.4.5.jar 100
-
4、Web页面查看日志(图见上)
备注:
1、在课程学习的过程中,大多数情况使用Standalone模式 或者 local模式
2、建议不使用HA;更多关注的Spark开发
-
 wechat
wechat alipay
alipay




