
Spark-Streaming概述
随着大数据技术的不断发展,人们对于大数据的实时性处理要求也在不断提高,传统的 MapReduce 等批处理框架在某些特定领域,例如实时用户推荐、用户行为分析这些应用场景上逐渐不能满足人们对实时性的需求,因此诞生了一批如 S3、Samza、Storm、Flink等流式分析、实时计算框架。
Spark 由于其内部优秀的调度机制、快速的分布式计算能力,能够以极快的速度进行迭代计算。正是由于具有这样的优势,Spark 能够在某些程度上进行实时处理,Spark Streaming 正是构建在此之上的流式框架。
什么是Spark Streaming
Spark Streaming类似于Apache Storm(来一条数据处理一条,延迟低,响应快,低吞吐量),用于流式数据的处理;
Spark Streaming具有有高吞吐量和容错能力强等特点;
Spark Streaming支持的数据输入源很多,例如:Kafka(最重要的数据源)、Flume、Twitter 和 TCP 套接字等;
数据输入后可用高度抽象API,如:map、reduce、join、window等进行运算;
处理结果能保存在很多地方,如HDFS、数据库等;
Spark Streaming 能与 MLlib 以及 Graphx 融合;

Spark Streaming 与 Spark 基于 RDD 的概念比较类似;
Spark Streaming使用离散化流(Discretized Stream)作为抽象表示,称为DStream。
DStream是随时间推移而收到的数据的序列。在内部,每个时间区间收到的数据都作为 RDD 存在,DStream 是由这些 RDD 所组成的序列。
DStream 可以从各种输入源创建,比如 Flume、Kafka 或者 HDFS。创建出来的 DStream 支持两种操作:
-
转化操作,会生成一个新的DStream
-
输出操作(output operation),把数据写入外部系统中
DStream 提供了许多与 RDD 所支持的操作相类似的操作支持,还增加了与时间相关的新操作,比如滑动窗口。
Spark Streaming架构
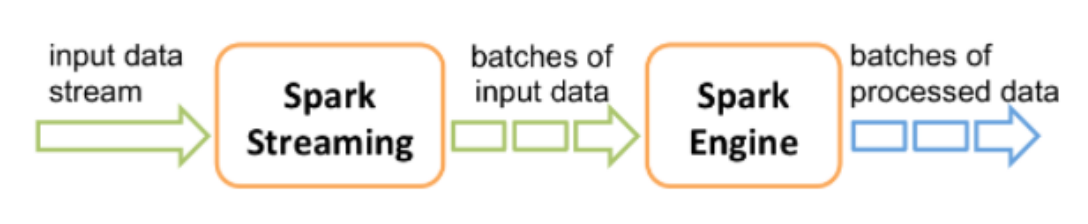
Spark Streaming使用 mini-batch 的架构,把流式计算当作一系列连续的小规模批处理来对待。
Spark Streaming从各种输入源中读取数据,并把数据分组为小的批次。新的批次按均匀的时间间隔创建出来。
在每个时间区间开始的时候,一个新的批次就创建出来,在该区间内收到的数据都会被添加到这个批次中。在时间区间结束时,批次停止增长。
时间区间的大小是由批次间隔这个参数决定的。批次间隔一般设在500毫秒到几秒之间,由开发者配置。
每个输入批次都形成一个RDD,以 Spark 作业的方式处理并生成其他的 RDD。 处理的结果可以以批处理的方式传给外部系统。
Spark Streaming的编程抽象是离散化流,也就是DStream。它是一个 RDD 序列,每个RDD代表数据流中一个时间片内的数据。

应用于 DStream 上的转换操作都会转换为底层RDD上的操作。如对行 DStream 中的每个RDD应用flatMap操作以生成单词 DStream 的RDD。
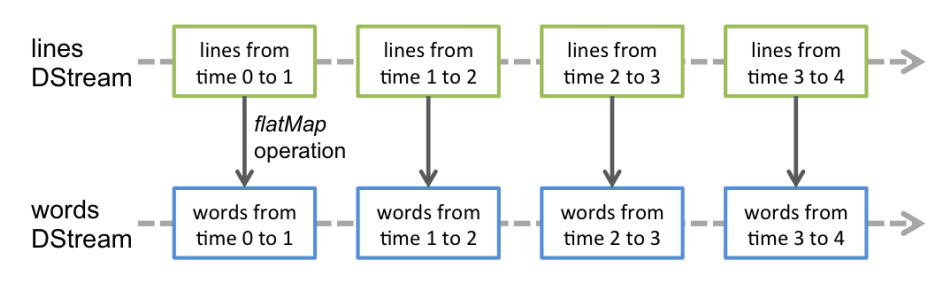
这些底层的RDD转换是由Spark引擎完成的。DStream操作隐藏了大部分这些细节,为开发人员提供了更高级别的API以方便使用。
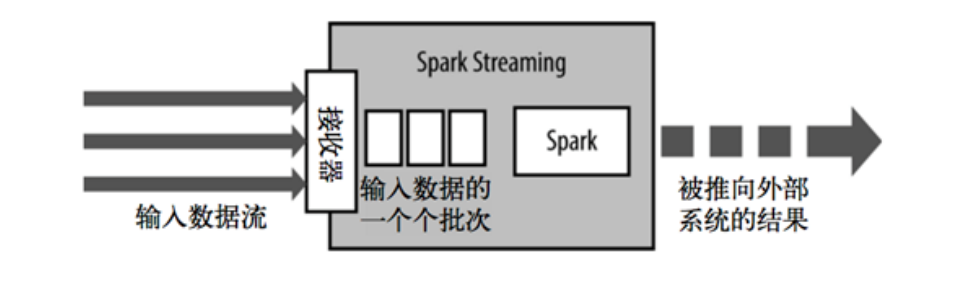
Spark Streaming为每个输入源启动对应的接收器。接收器运行在Executor中,从输入源收集数据并保存为 RDD ;
默认情况下接收到的数据后会复制到另一个Executor中,进行容错;
Driver 中的 StreamingContext 会周期性地运行 Spark 作业来处理这些数据;
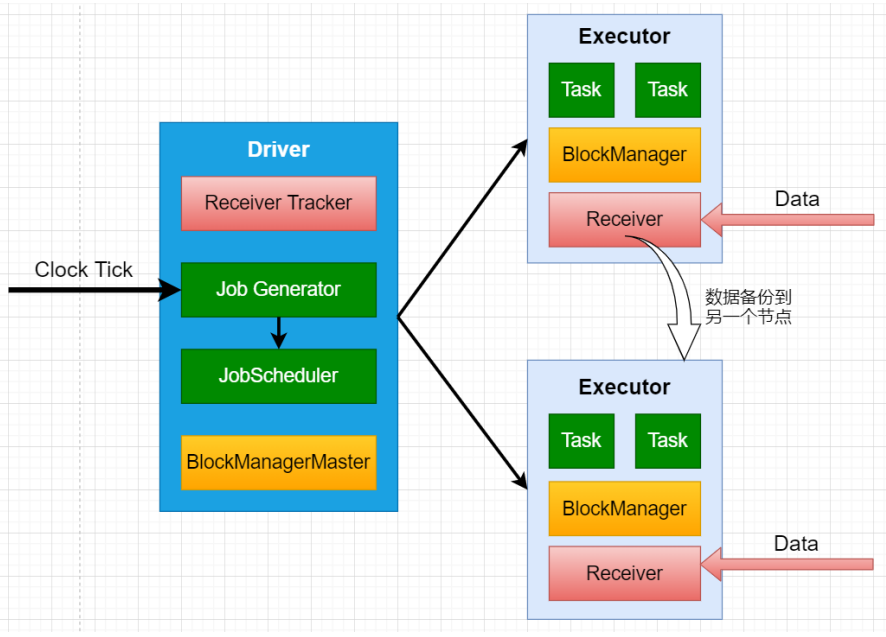
SparkStreaming运行流程:
-
1、客户端提交Spark Streaming作业后启动Driver,Driver启动Receiver,Receiver接收数据源的数据
-
2、每个作业包含多个Executor,每个Executor以线程的方式运行task,Spark Streaming至少包含一个receiver task(一般情况下)
-
3、Receiver接收数据后生成Block,并把BlockId汇报给Driver,然后备份到另外一个 Executor 上
-
4、ReceiverTracker维护 Reciver 汇报的BlockId
-
5、Driver定时启动JobGenerator,根据Dstream的关系生成逻辑RDD,然后创建Jobset,交给JobScheduler
-
6、JobScheduler负责调度Jobset,交给DAGScheduler,DAGScheduler根据逻辑RDD,生成相应的Stages,每个stage包含一到多个Task,将TaskSet提交给TaskSchedule
-
7、TaskScheduler负责把 Task 调度到 Executor 上,并维护 Task 的运行状态
Spark Streaming 优缺点
与传统流式框架相比,Spark Streaming 最大的不同点在于它对待数据是粗粒度的处理方式,即一次处理一小批数据,而其他框架往往采用细粒度的处理模式,即依次处理一条数据。Spark Streaming 这样的设计实现既为其带来了显而易见的优点,又引入了不可避免的缺点。
-
优点
-
Spark Streaming 内部的实现和调度方式高度依赖 Spark 的 DAG 调度器和RDD,这就决定了 Spark Streaming 的设计初衷必须是粗粒度方式的。同时,由于 Spark 内部调度器足够快速和高效,可以快速地处理小批量数据,这就获得准实时的特性
-
Spark Streaming 的粗粒度执行方式使其确保 ”处理且仅处理一次” 的特性(EOS),同时也可以更方便地实现容错恢复机制
-
由于 Spark Streaming 的 DStream 本质是 RDD 在流式数据上的抽象,因此基于 RDD 的各种操作也有相应的基于 DStream 的版本,这样就大大降低了用户对于新框架的学习成本,在了解 Spark 的情况下用户将很容易使用 Spark Streaming
-
由于 DStream 是在 RDD 上的抽象,那么也就更容易与 RDD 进行交互操作,在需要将流式数据和批处理数据结合进行分析的情况下,将会变得非常方便
-
-
缺点
- Spark Streaming 的粗粒度处理方式也造成了不可避免的延迟。在细粒度处理方式下,理想情况下每一条记录都会被实时处理,而在 Spark Streaming 中,数据需要汇总到一定的量后再一次性处理,这就增加了数据处理的延迟,这种延迟是由框架的设计引入的,并不是由网络或其他情况造成的
Structured Streaming
Spark Streaming计算逻辑是把数据按时间划分为DStream,存在以下问题:
-
框架自身只能根据 Batch Time 单元进行数据处理,很难处理基于event time(即时间戳)的数据,很难处理延迟,乱序的数据
-
流式和批量处理的 API 不完全一致,两种使用场景中,程序代码还是需要一定的转换
-
端到端的数据容错保障逻辑需要用户自己构建,难以处理增量更新和持久化存储等一致性问题
基于以上问题,提出了下一代 Structure Streaming 。将数据源映射为一张无界长度的表,通过表的计算,输出结果映射为另一张表。
以结构化的方式去操作流式数据,简化了实时计算过程,同时还复用了 Catalyst 引擎来优化SQL操作。此外还能支持增量计算和基于event time的计算。
 wechat
wechat alipay
alipay


