运行MapReduce程序时,输入的文件格式包括:基于行的日志文件、二进制格式文件、数据库表等。
InputFormat是MapReduce框架用来读取数据的类。
TextInputFormat (普通文本文件,MR框架默认的读取实现类型)
KeyValueTextInputFormat(读取一行文本数据按照指定分隔符,把数据封装为kv类型)
NLineInputF ormat(读取数据按照行数进行划分分片)
CombineTextInputFormat(合并小文件,避免启动过多MapTask任务)
自定义InputFormat
CombineTextInputFormat案例
MR框架默认的TextInputFormat切片机制按文件划分切片,文件无论多小,都是单独一个切片,然后由一个MapTask处理,如果有大量小文件,就对应的会生成并启动大量的 MapTask,而每个MapTask处理的数据量很小大量时间浪费在初始化资源启动收回等阶段,这种方式导致资源利用率不高。
CombineTextInputFormat 用于小文件过多的场景,它可以将多个小文件从逻辑上划分成一个切片,这样多个小文件就可以交给一个MapTask处理,提高资源利用率。
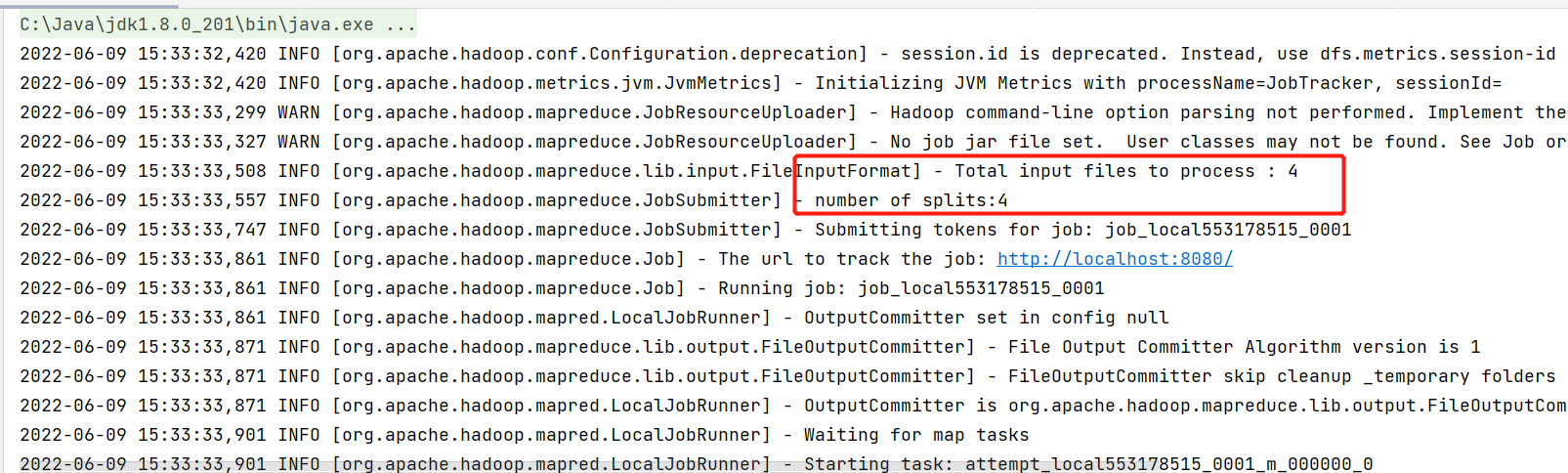
准备多个小文件,运行WordCount案例,将输入数据中的多个小文件合并为一个切片处理。
在博客MapReduce编程规范及示例编写 中maven工程wordcount里的wc包WordCountDriver改造。
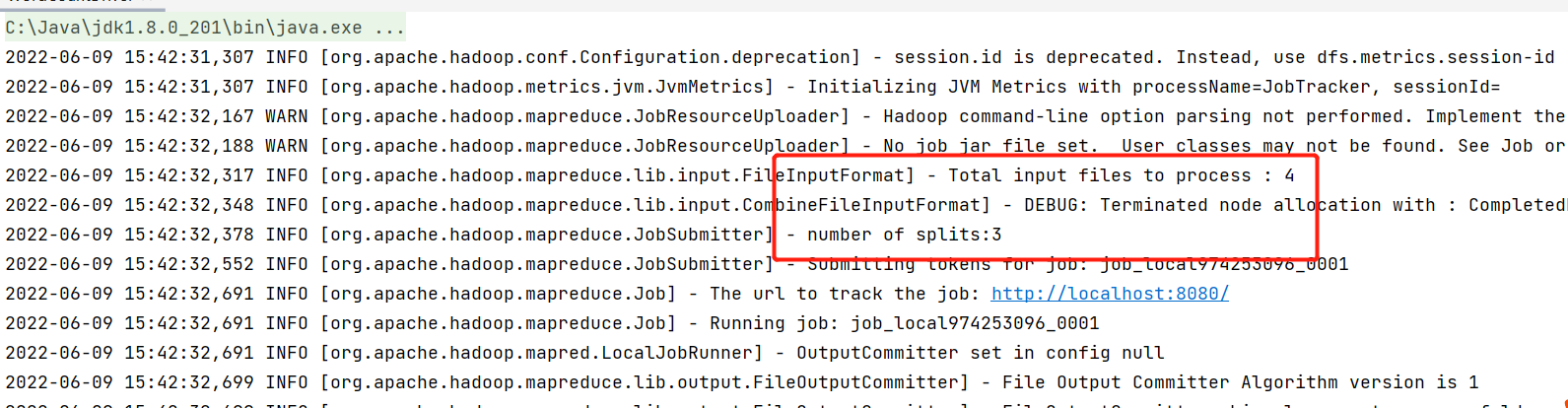
1 2 3 4 5 6 7 8 9 10 11 #添加 // 如果不设置InputFormat,它默认用的是TextInputFormat.class job.setInputFormatClass(CombineTextInputFormat.class); //虚拟存储切片最大值设置4m CombineTextInputFormat.setMaxInputSplitSize(job, 4194304); #修改文件地址 //6. 指定job读取数据路径 FileInputFormat.setInputPaths(job, new Path("E:\\bigdatafile\\input\\small_file")); //指定读取数据的原始路径 //7. 指定job输出结果路径 FileOutputFormat.setOutputPath(job, new Path("E:\\bigdatafile\\output\\small_file")); //指定结果数据输出路径
CombineTextInputFormat切片原理
切片生成过程分为两部分:虚拟存储过程和切片过程
假设设置setMaxInputSplitSize值为4M,四个小文件:1.txt -->2M ;2.txt–>7M;3.txt–>0.3M;4.txt—>8.2M
虚拟存储过程
把输入目录下所有文件大小,依次和设置的setMaxInputSplitSize值进行比较,如果不大于设置的最大值,逻辑上划分一个块。如果输入文件大于设置的最大值且大于两倍,那么以最大值切割一块;当剩余数据大小超过设置的最大值且不大于最大值2倍,此时将文件均分成2个虚拟存储块(防止出现太小切片)。
比如如setMaxInputSplitSize值为4M,输入文件大小为8.02M,则先逻辑上分出一个4M的块。剩余的大小为4.02M,如果按照4M逻辑划分,就会出现0.02M的非常小的虚拟存储文件,所以将剩余的4.02M文件切分成(2.01M和2.01M)两个文件。
1.txt–>2M;2M<4M;一个块;
所有块信息:2M,3.5M,3.5M,0.3M,4M,2.1M,2.1M 共7个虚拟存储块。
切片过程
判断虚拟存储的文件大小是否大于setMaxInputSplitSize值,大于等于则单独形成一个切片。如果不大于则跟下一个虚拟存储文件进行合并,共同形成一个切片。
最终会形成3个切片,大小分别为:(2+3.5)M,(3.5+0.3+4)M,(2.1+2.1)M
注意:虚拟存储切片最大值设置最好根据实际的小文件大小情况来设置具体的值。
HDFS还是MapReduce,在处理小文件时效率都非常低,但又难免面临处理大量小文件的场景,此时,就需要有相应解决方案。可以自定义InputFormat实现小文件的合并。
定义一个类继承FileInputFormat(TextInputFormat的父类就是FileInputFormat)
重写isSplitable()指定为不可切分;重写createRecordReader()方法,创建自己的RecorderReader对象(实现自定义读取数据)
改变默认读取数据方式,实现一次读取一个完整文件作为kv输出
Driver指定使用的InputFormat类型
在博客MapReduce编程规范及示例编写 中maven工程wordcount里编写案例,创建inputformat包。
编写CustomFileInputformat类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 package com.lagou.mr.inputformat; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.BytesWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.InputSplit; import org.apache.hadoop.mapreduce.JobContext; import org.apache.hadoop.mapreduce.RecordReader; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import java.io.IOException; /** * SequenceFile文件中以kv形式存储文件,key-->文件路径+文件名称,value-->文件的整个内容 */ public class CustomFileInputformat extends FileInputFormat<Text, BytesWritable> { //重写是否可切分,设置文件不可切分 @Override protected boolean isSplitable(JobContext context, Path filename) { return false; } //获取自定义RecordReader对象用来读取数据 @Override public RecordReader<Text, BytesWritable> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException { CustomRecordReader recordReader = new CustomRecordReader(); //调用recordReader的初始化方法 recordReader.initialize(split, context); return recordReader; } }
编写CustomRecordReader类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 package com.lagou.mr.inputformat; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.BytesWritable; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.InputSplit; import org.apache.hadoop.mapreduce.RecordReader; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import java.io.IOException; /** *负责读取数据,一次读取整个文件内容,封装成kv输出 */ public class CustomRecordReader extends RecordReader<Text, BytesWritable> { //hadoop配置文件对象 private Configuration configuration; //切片 private FileSplit split; //定义key,value的成员变量 private Text k = new Text(); private BytesWritable value = new BytesWritable(); //初始化方法,把切片以及上下文提升为全局 @Override public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException { //获取到文件切片以及配置文件对象 this.split = (FileSplit) split; configuration = context.getConfiguration(); } private boolean isProgress = true; //用来读取数据的方法 @Override public boolean nextKeyValue() throws IOException, InterruptedException { if (isProgress) { // 1 存储读到的数据,大小为切片信息中文件的大小 byte[] contents = new byte[(int) split.getLength()]; FileSystem fs = null; FSDataInputStream fis = null; try { // 2 获取切片中的path信息 Path path = split.getPath(); // 3 获取文件系统对象 fs = path.getFileSystem(configuration); // 4 读取数据输入流 fis = fs.open(path); // 5 读取数据输入流并存储到contents IOUtils.readFully(fis, contents, 0, contents.length); // 6 获取文件路径及名称 String name = split.getPath().toString(); // 7 封装key和value k.set(name); value.set(contents, 0, contents.length); } catch (Exception e) { } finally { //关闭输入流 IOUtils.closeStream(fis); } //把再次读取的开关置为false isProgress = false; //返回读取到数据 return true; } //返回未读取到数据 return false; } //获取到key @Override public Text getCurrentKey() throws IOException, InterruptedException { //返回key return k; } //获取到value @Override public BytesWritable getCurrentValue() throws IOException, InterruptedException { //返回value return value; } //获取进度 @Override public float getProgress() throws IOException, InterruptedException { return 0; } //关闭资源 @Override public void close() throws IOException { } }
编写SequenceFileMapper类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package com.lagou.mr.inputformat; import org.apache.hadoop.io.BytesWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class SequenceFileMapper extends Mapper<Text, BytesWritable,Text,BytesWritable> { @Override protected void map(Text key, BytesWritable value, Context context) throws IOException, InterruptedException { //读取内容直接输出 context.write(key, value); } }
编写SequenceFileReducer类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package com.lagou.mr.inputformat; import org.apache.hadoop.io.BytesWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class SequenceFileReducer extends Reducer<Text, BytesWritable,Text,BytesWritable> { @Override protected void reduce(Text key, Iterable<BytesWritable> values, Context context) throws IOException, InterruptedException { //输出value值,其中只有一个BytesWritable 所以直接next取出即可 context.write(key, values.iterator().next()); } }
编写SequenceFileDriver类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 package com.lagou.mr.inputformat; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.BytesWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class SequenceFileDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { // 1. 获取配置文件对象,获取job对象实例 final Configuration conf = new Configuration(); final Job job = Job.getInstance(conf, "SequenceFileDriver"); // 2. 指定程序jar的本地路径 job.setJarByClass(SequenceFileDriver.class); // 3. 指定Mapper/Reducer类 job.setMapperClass(SequenceFileMapper.class); job.setReducerClass(SequenceFileReducer.class); // 4. 指定Mapper输出的kv数据类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(BytesWritable.class); // 5. 指定最终输出的kv数据类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(BytesWritable.class); // 7 使用自定义InputFormat读取数据 job.setInputFormatClass(CustomFileInputformat.class); // 8. 指定job输出结果路径 FileInputFormat.setInputPaths(job, new Path("E:\\bigdatafile\\input\\small_file"));//指定读取数据的原始 路径 // 9. 指定job输出结果路径 FileOutputFormat.setOutputPath(job, new Path("E:\\bigdatafile\\output\\inputformat")); //指定结果数据输出 路径 // 10. 提交作业 final boolean flag = job.waitForCompletion(true); //jvm退出:正常退出0,非0值则是错误退出 System.exit(flag ? 0 : 1); } }
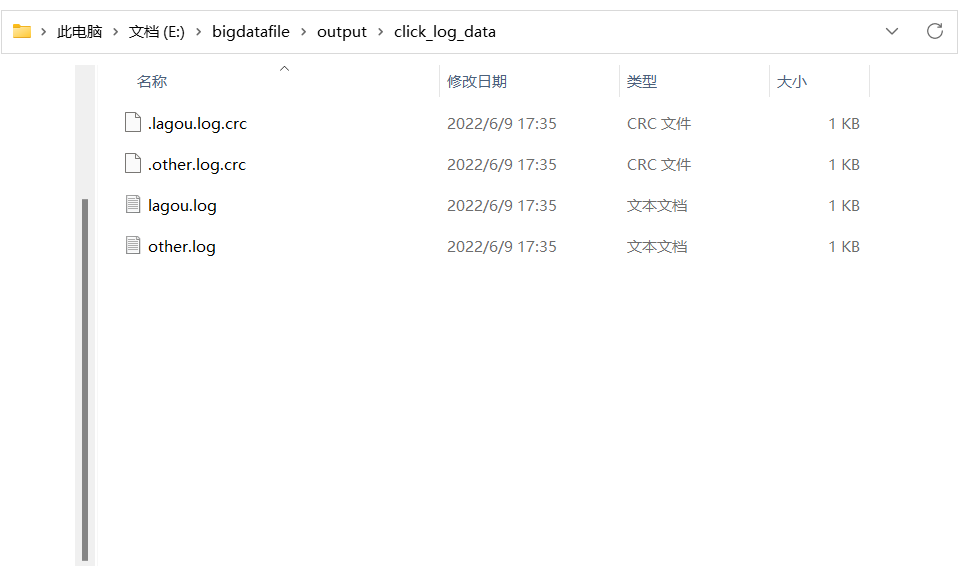
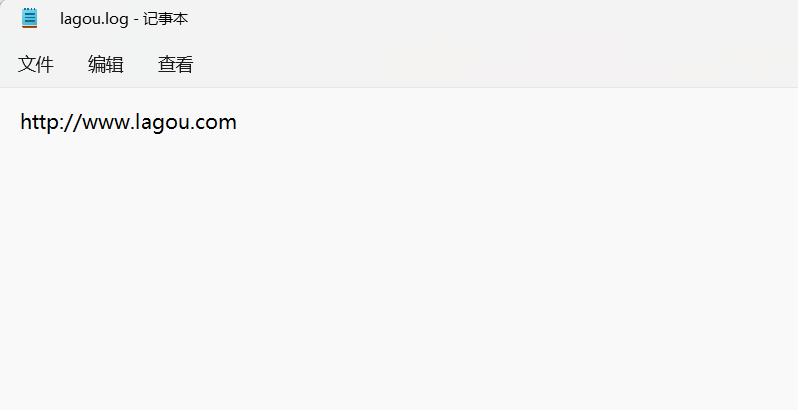
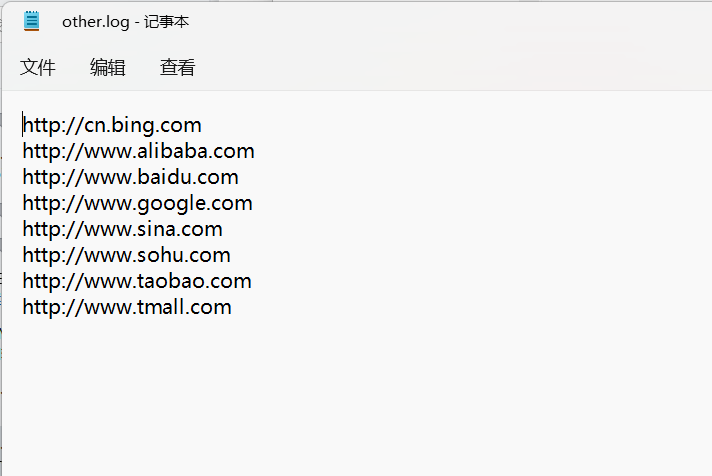
输出结果
OutputFormat:是MapReduce输出数据的基类,所有MapReduce的数据输出都实现了OutputFormat抽象类。
TextOutputFormat,默认的输出格式是TextOutputFormat,它把每条记录写为文本行。它的键和值可以是任意类型,因为TextOutputFormat调用toString()方 法把它们转换为字符串。
SequenceFileOutputFormat,将SequenceFileOutputFormat输出作为后续MapReduce任务的输入,这是一种好的输出格式,因为它的格式紧凑,很容易被压缩。
自定义一个类继承FileOutputFormat。
改写RecordWriter,改写输出数据的方法write()。
在博客MapReduce编程规范及示例编写 中maven工程wordcount里编写案例,创建outputformat包。
编写CustomOutputFormat类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 package com.lagou.mr.outputformat; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.RecordWriter; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class CustomOutputFormat extends FileOutputFormat<Text, NullWritable> { //写出数据的对象 @Override public RecordWriter<Text, NullWritable> getRecordWriter(TaskAttemptContext context) throws IOException, InterruptedException { //获取文件系统对象 final FileSystem fs = FileSystem.get(context.getConfiguration()); //指定输出数据的文件 final Path lagouPath = new Path("E:\\bigdatafile\\output\\click_log_data\\lagou.log"); final Path otherLog = new Path("E:\\bigdatafile\\output\\click_log_data\\other.log"); //获取输出流 final FSDataOutputStream lagouOut = fs.create(lagouPath); final FSDataOutputStream otherOut = fs.create(otherLog); return new CustomWriter(lagouOut, otherOut); } }
编写CustomWriter类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 package com.lagou.mr.outputformat; import org.apache.hadoop.fs.FSDataOutputStream; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.RecordWriter; import org.apache.hadoop.mapreduce.TaskAttemptContext; import java.io.IOException; public class CustomWriter extends RecordWriter<Text, NullWritable> { //定义成员变量 private FSDataOutputStream lagouOut; private FSDataOutputStream otherOut; //定义构造方法接受两个输出流 public CustomWriter(FSDataOutputStream lagouOut,FSDataOutputStream otherOut) { this.lagouOut=lagouOut; this.otherOut=otherOut; } //写出数据的逻辑 @Override public void write(Text key, NullWritable value) throws IOException, InterruptedException { // 判断是否包含“lagou”输出到不同文件 if (key.toString().contains("lagou")) { lagouOut.write(key.toString().getBytes()); lagouOut.write("\r\n".getBytes()); } else { otherOut.write(key.toString().getBytes()); otherOut.write("\r\n".getBytes()); } } //关闭资源 @Override public void close(TaskAttemptContext context) throws IOException, InterruptedException { IOUtils.closeStream(lagouOut); IOUtils.closeStream(otherOut); } }
编写OutputMapper类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 package com.lagou.mr.outputformat; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; public class OutputMapper extends Mapper<LongWritable, Text,Text, NullWritable> { @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { context.write(value, NullWritable.get()); } }
编写OutputReducer类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package com.lagou.mr.outputformat; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; public class OutputReducer extends Reducer<Text, NullWritable,Text,NullWritable> { @Override protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException { context.write(key,NullWritable.get()); } }
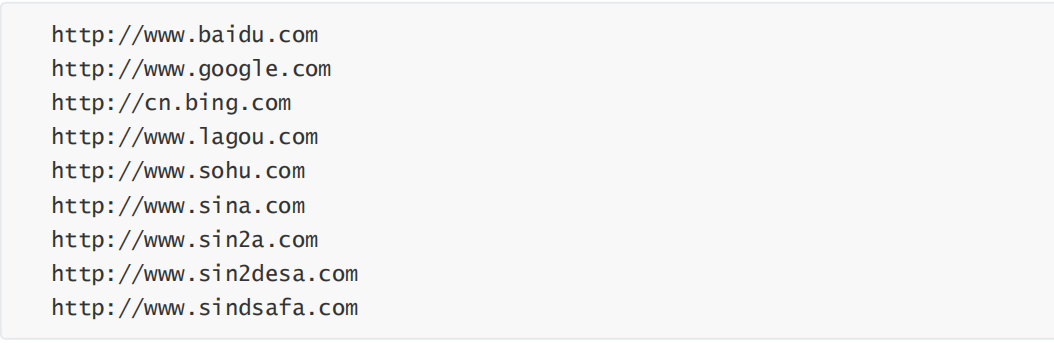
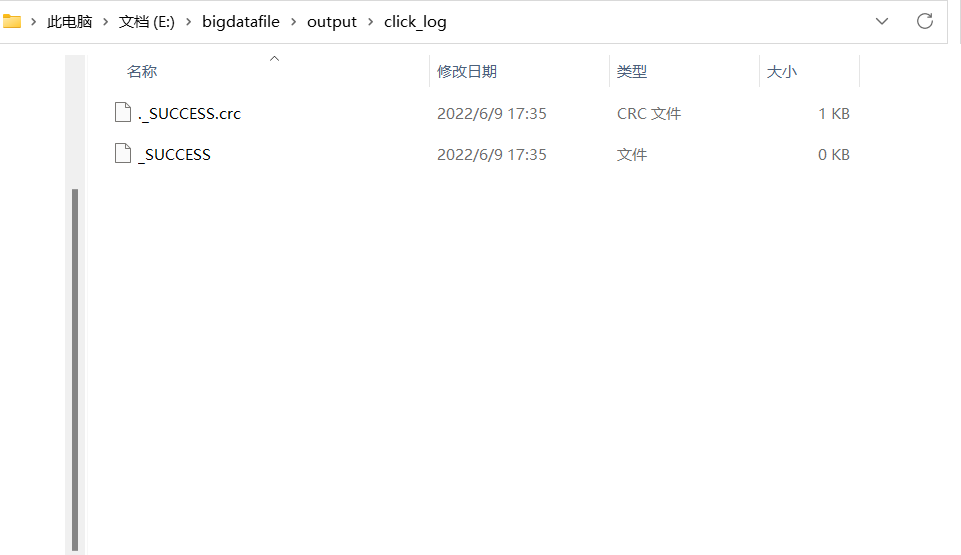
编写OutputDriver类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 package com.lagou.mr.outputformat; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; public class OutputDriver { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { // 1. 获取配置文件对象,获取job对象实例 final Configuration conf = new Configuration(); final Job job = Job.getInstance(conf, "OutputDriver"); // 2. 指定程序jar的本地路径 job.setJarByClass(OutputDriver.class); // 3. 指定Mapper/Reducer类 job.setMapperClass(OutputMapper.class); job.setReducerClass(OutputReducer.class); // 4. 指定Mapper输出的kv数据类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(NullWritable.class); // 5. 指定最终输出的kv数据类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); // 7 使用自定义OutputFormat输出数据 job.setOutputFormatClass(CustomOutputFormat.class); // 8. 指定job输出结果路径 FileInputFormat.setInputPaths(job, new Path("E:\\bigdatafile\\input\\click_log.data")); // outputformat继承自fileoutputformat 而fileoutputformat要输出一个_SUCCESS 文件,所以,在这还得指定一个输出目录 // 9. 指定job输出结果路径 FileOutputFormat.setOutputPath(job, new Path("E:\\bigdatafile\\output\\click_log")); // 10. 提交作业 final boolean flag = job.waitForCompletion(true); //jvm退出:正常退出0,非0值则是错误退出 System.exit(flag ? 0 : 1); } }


 wechat
wechat alipay
alipay


