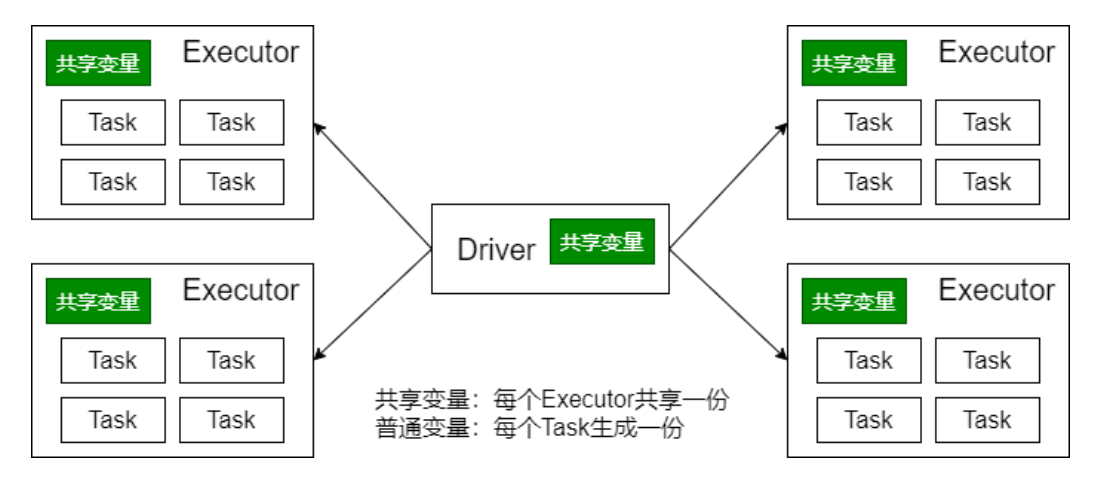
有时候需要在多个任务之间共享变量,或者在任务(Task)和Driver Program之间共享变量 。
为了满足这种需求,Spark提供了两种类型的变量:
广播变量、累加器主要作用是为了优化Spark程序。
广播变量
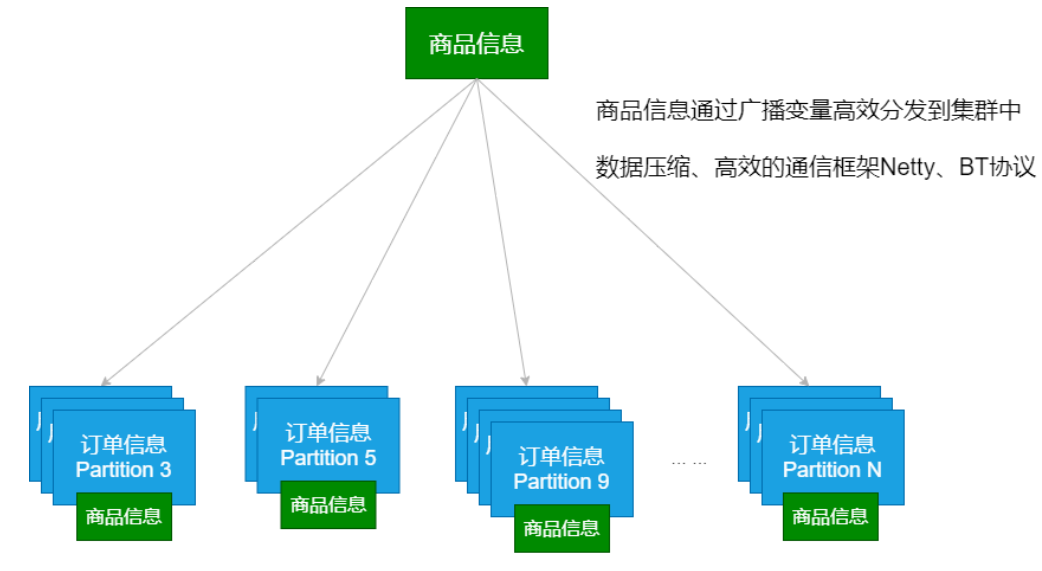
广播变量将变量在节点的 Executor 之间进行共享(由Driver广播出去);
广播变量用来高效分发较大的对象。向所有工作节点(Executor)发送一个较大的只读值,以供一个或多个操作使用。
使用广播变量的过程如下:
对一个类型 T 的对象调用 SparkContext.broadcast 创建出一个 Broadcast[T]对象。 任何可序列化的类型都可以这么实现(在 Driver 端)
通过 value 属性访问该对象的值(在 Executor 中)
变量只会被发到各个 Executor 一次,作为只读值处理
广播变量的相关参数:
spark.broadcast.blockSize(缺省值:4m)
spark.broadcast.checksum(缺省值:true)
spark.broadcast.compress(缺省值:true)
广播变量的运用
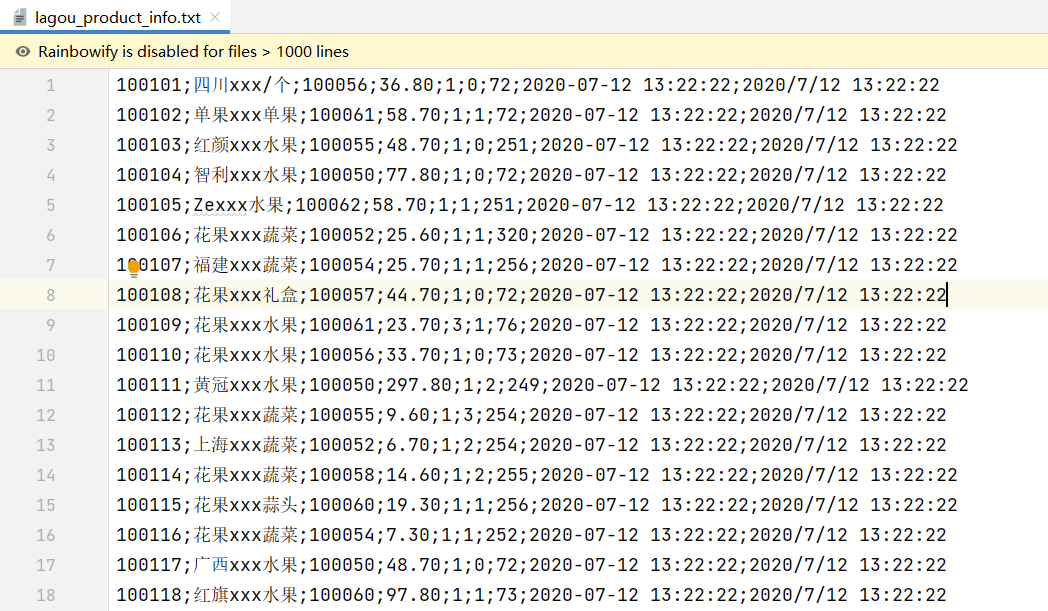
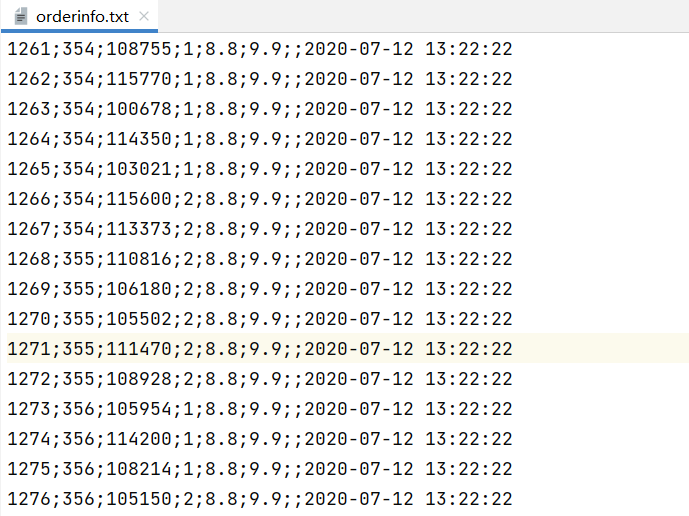
数据格式:
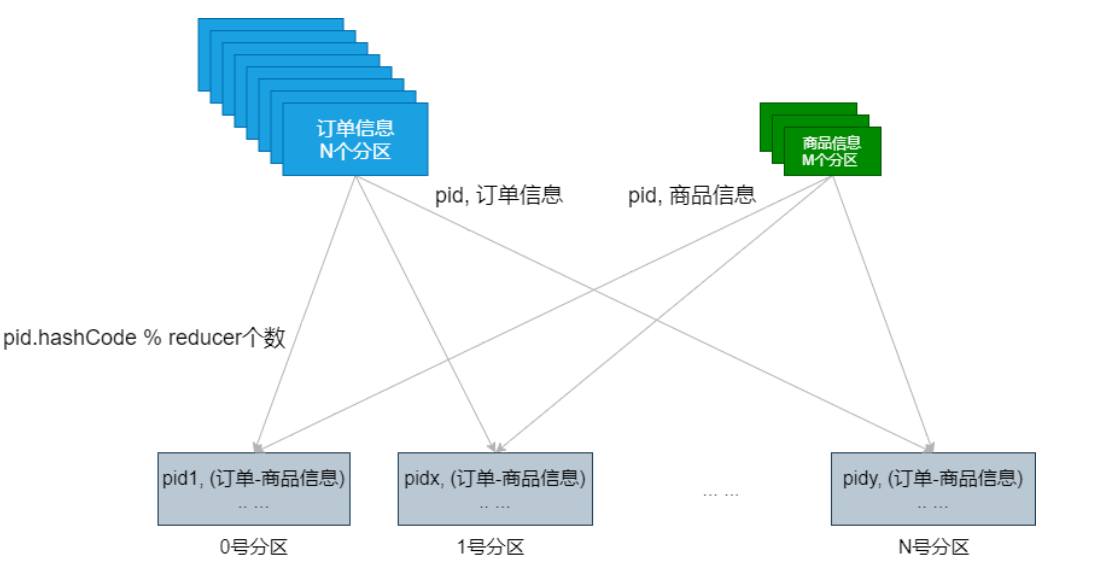
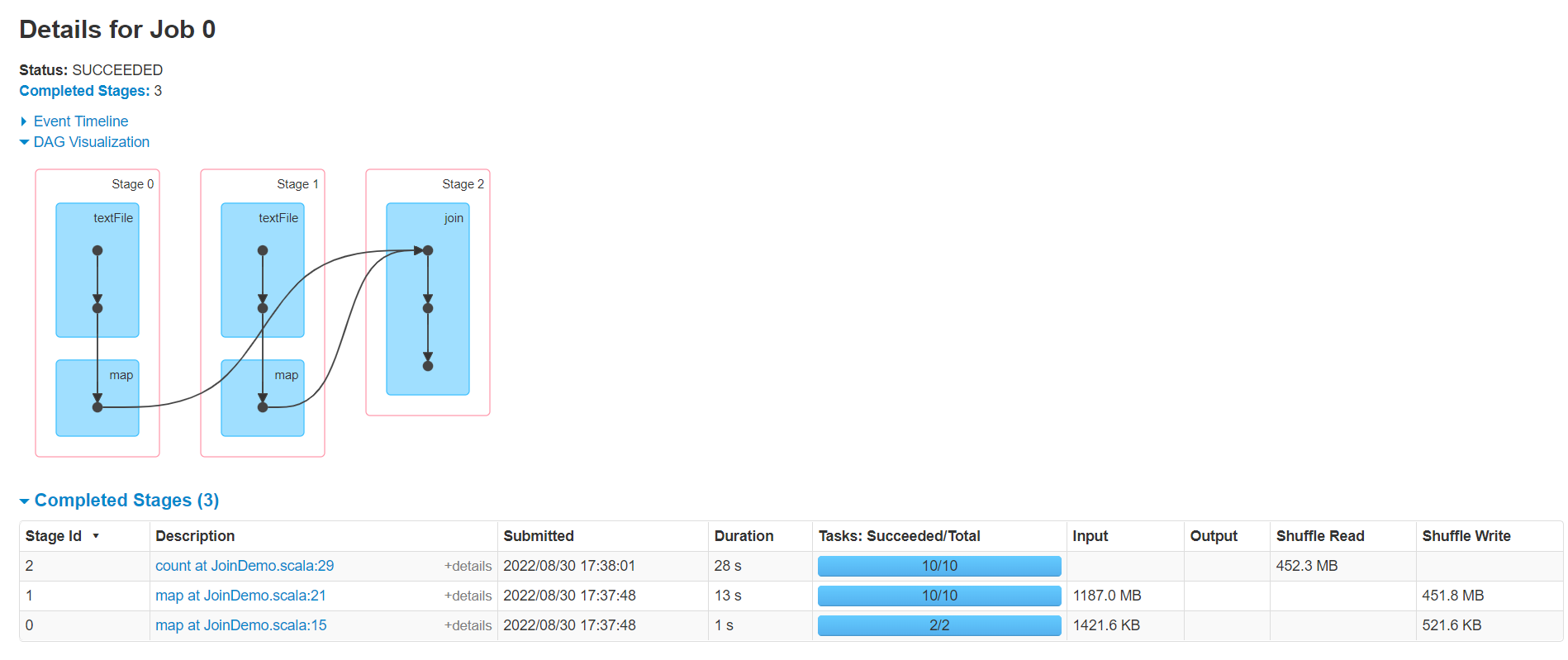
普通的Join操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 package cn.lagou.sparkcoreimport org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object JoinDemo def main Array [String ]): Unit = { val conf = new SparkConf ().setMaster("local[*]" ).setAppName(this .getClass.getCanonicalName.init) val sc = new SparkContext (conf) sc.hadoopConfiguration.setLong("fs.local.block.size" , 128 *1024 *1024 ) val productRDD: RDD [(String , String )] = sc.textFile("file:///C:\\Users\\Administrator\\IdeaProjects\\sparkcoreDemo\\data\\lagou_product_info.txt" ) .map { line => val fields = line.split(";" ) (fields(0 ), line) } val orderRDD: RDD [(String , String )] = sc.textFile("file:///C:\\Users\\Administrator\\IdeaProjects\\sparkcoreDemo\\data\\orderinfo.txt" ,8 ) .map { line => val fields = line.split(";" ) (fields(2 ), line) } val resultRDD: RDD [(String , (String , String ))] = productRDD.join(orderRDD) println(resultRDD.count()) Thread .sleep(1000000 ) sc.stop() } }
执行时间42s,shuffle read 450M
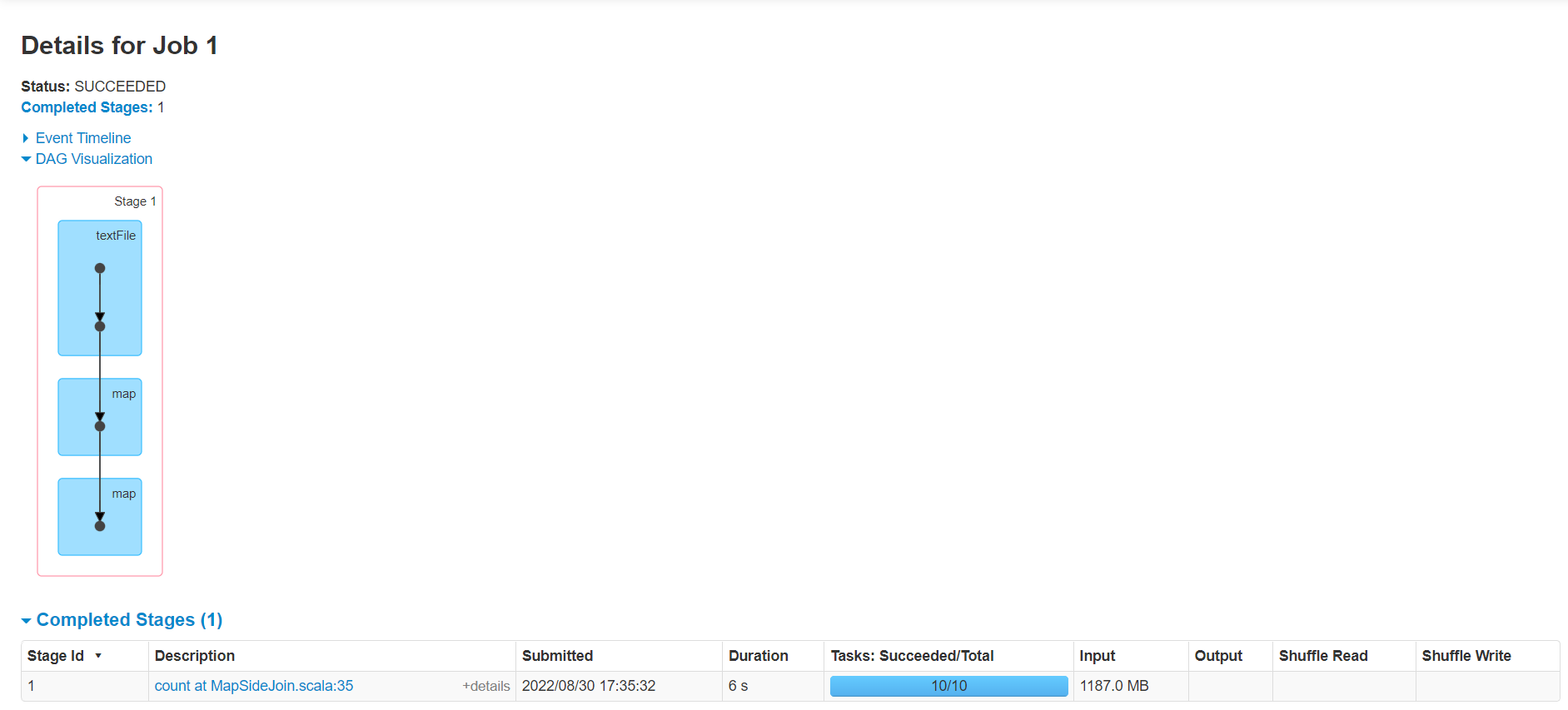
Map Side Join:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 package cn.lagou.sparkcoreimport org.apache.spark.broadcast.Broadcast import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object MapSideJoin def main Array [String ]): Unit = { val conf = new SparkConf ().setMaster("local[*]" ).setAppName(this .getClass.getCanonicalName.init) val sc = new SparkContext (conf) sc.hadoopConfiguration.setLong("fs.local.block.size" , 128 *1024 *1024 ) val productMap: collection.Map [String , String ] = sc.textFile("file:///C:\\Users\\Administrator\\IdeaProjects\\sparkcoreDemo\\data\\lagou_product_info.txt" ) .map { line => val fields = line.split(";" ) (fields(0 ), line) }.collectAsMap() val productBC: Broadcast [collection.Map [String , String ]] = sc.broadcast(productMap) val orderRDD: RDD [(String , String )] = sc.textFile("file:///C:\\Users\\Administrator\\IdeaProjects\\sparkcoreDemo\\data\\orderinfo.txt" ,8 ) .map { line => val fields = line.split(";" ) (fields(2 ), line) } val resultRDD: RDD [(String , (String , String ))] = orderRDD.map { case (pid, orderInfo) => val productInfoMap: collection.Map [String , String ] = productBC.value val produceInfoString: String = productInfoMap.getOrElse(pid, null ) (pid, (produceInfoString, orderInfo)) } println(resultRDD.count()) Thread .sleep(1000000 ) sc.stop() } }
执行时间6s,没有shuffle
累加器
累加器的作用:可以实现一个变量在不同的 Executor 端能保持状态的累加;
累计器在 Driver 端定义,读取;在 Executor 中完成累加;
累加器也是 lazy 的,需要 Action 触发;Action触发一次,执行一次,触发多次,执行多次;
累加器一个比较经典的应用场景是用来在 Spark Streaming 应用中记录某些事件的数量;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 scala> val data = sc.makeRDD(Seq("hadoop map reduce", "spark mllib")) data: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[39] at makeRDD at <console>:24 // 方式1 scala> val count1 = data.flatMap(line => line.split("\\s+")).map(word => 1).reduce(_ + _) count1: Int = 5 scala> println(count1) 5 // 方式2。错误的方式 scala> var acc = 0 acc: Int = 0 scala> data.flatMap(line => line.split("\\s+")).foreach(word => acc += 1) scala> println(acc) 0 // 在Driver中定义变量,每个运行的Task会得到这些变量的一份新的副本,但在 Task中更新这些副本的值不会影响Driver中对应变量的值
Spark内置了三种类型的累加器,分别是
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 scala> val data = sc.makeRDD("hadoop spark hive hbase java scala hello world spark scala java hive".split("\\s+")) data: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[43] at makeRDD at <console>:24 scala> val acc1 = sc.longAccumulator("totalNum1") acc1: org.apache.spark.util.LongAccumulator = LongAccumulator(id: 600, name: Some(totalNum1), value: 0) scala> val acc2 = sc.doubleAccumulator("totalNum2") acc2: org.apache.spark.util.DoubleAccumulator = DoubleAccumulator(id: 601, name: Some(totalNum2), value: 0.0) scala> val acc3 = sc.collectionAccumulator[String]("allWords") acc3: org.apache.spark.util.CollectionAccumulator[String] = CollectionAccumulator(id: 602, name: Some(allWords), value: []) scala> val rdd = data.map{ word => acc1.add(word.length) acc2.add(word.length) acc3.add(word) word } rdd: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[44] at map at <console>:31 scala> rdd.count res43: Long = 12 scala> rdd.collect res44: Array[String] = Array(hadoop, spark, hive, hbase, java, scala, hello, world, spark, scala, java, hive) scala> println(acc1.value) 114 scala> println(acc2.value) 114.0 scala> println(acc3.value) [hive, scala, spark, hive, hadoop, hbase, hello, world, spark, scala, java, java, hadoop, scala, hbase, hello, spark, scala, hive, hive, spark, java, java, world]
TopN的优化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 package cn.lagou.sparkcoreimport org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }import scala.collection.immutableobject TopN def main Array [String ]): Unit = { val conf = new SparkConf ().setAppName(this .getClass.getCanonicalName.init).setMaster("local[*]" ) val sc = new SparkContext (conf) sc.setLogLevel("WARN" ) val N = 9 val random = scala.util.Random val scores: immutable.IndexedSeq [String ] = (1 to 50 ).flatMap { idx => (1 to 2000 ).map { id => f"group$idx %2d,${random.nextInt(100000)} " } } val scoresRDD: RDD [(String , Int )] = sc.makeRDD(scores).map { line => val fields: Array [String ] = line.split("," ) (fields(0 ), fields(1 ).toInt) } scoresRDD.cache() scoresRDD.groupByKey() .mapValues(buf => buf.toList.sorted.takeRight(N ).reverse) .sortByKey() .collect.foreach(println) println("******************************************" ) scoresRDD.aggregateByKey(List [Int ]())( (lst, score) => (lst :+ score).sorted.takeRight(N ), (lst1, lst2) => (lst1 ++ lst2).sorted.takeRight(N ) ).mapValues(buf => buf.reverse) .sortByKey() .collect.foreach(println) sc.stop() } }

 wechat
wechat alipay
alipay



