
Azkaban使⽤
Azkaban可能遇到虚拟机内存不⾜情况:
- 增⼤机器内存
1 | # 查看内存大小 |
- 使⽤清除系统缓存命令,暂时释放⼀些内存
1 | [root@linux123 mapreduce]# echo 1 >/proc/sys/vm/drop_caches |
- 关闭web的最大最小内存过滤器
1 | [root@Linux122 ~]# cd /opt/lagou/servers/azkaban/azkaban-web-server-0.1.0-SNAPSHOT/conf/ |
shell 调度
创建job描述⽂件,vi command.job
1 | type=command |
将job资源⽂件打包成zip⽂件, command.zip
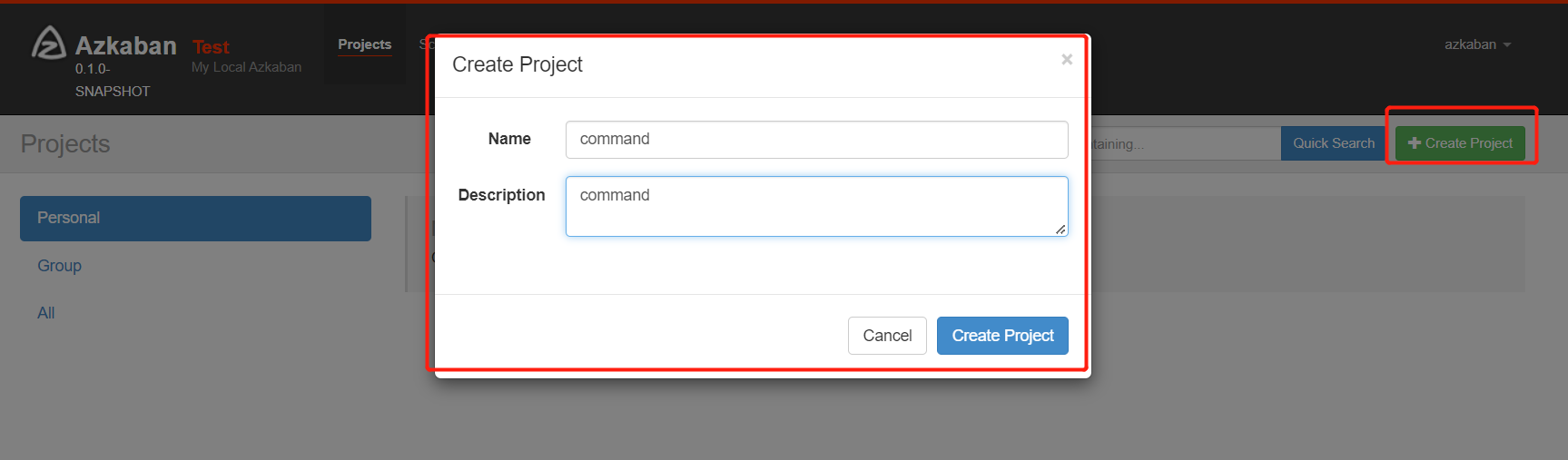
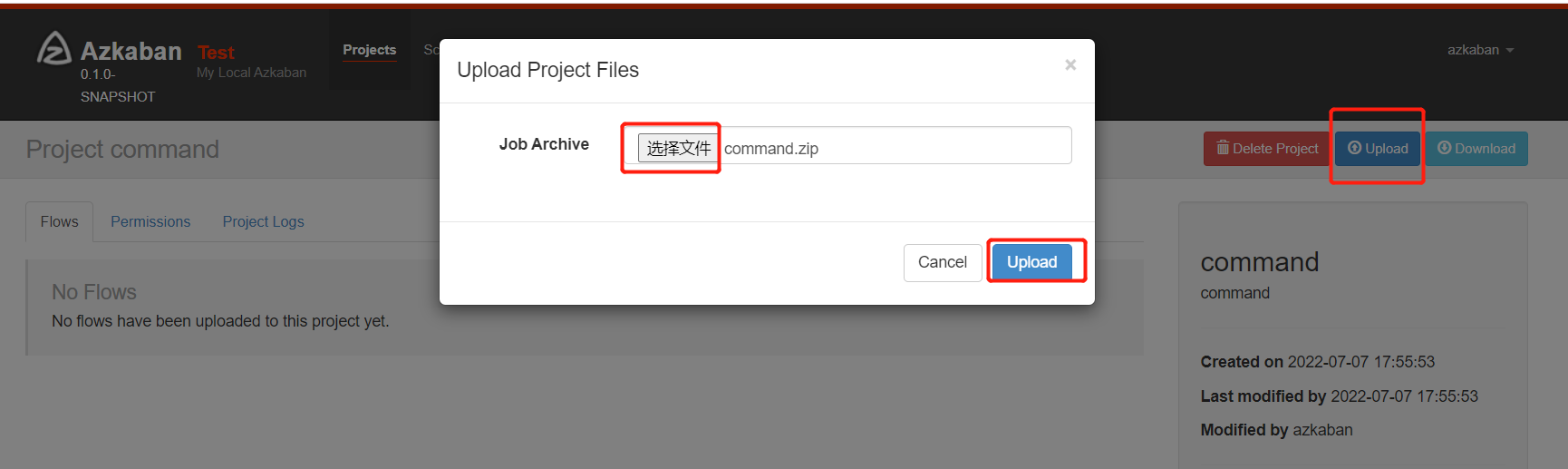
通过azkaban的web管理平台创建project并上传job压缩包
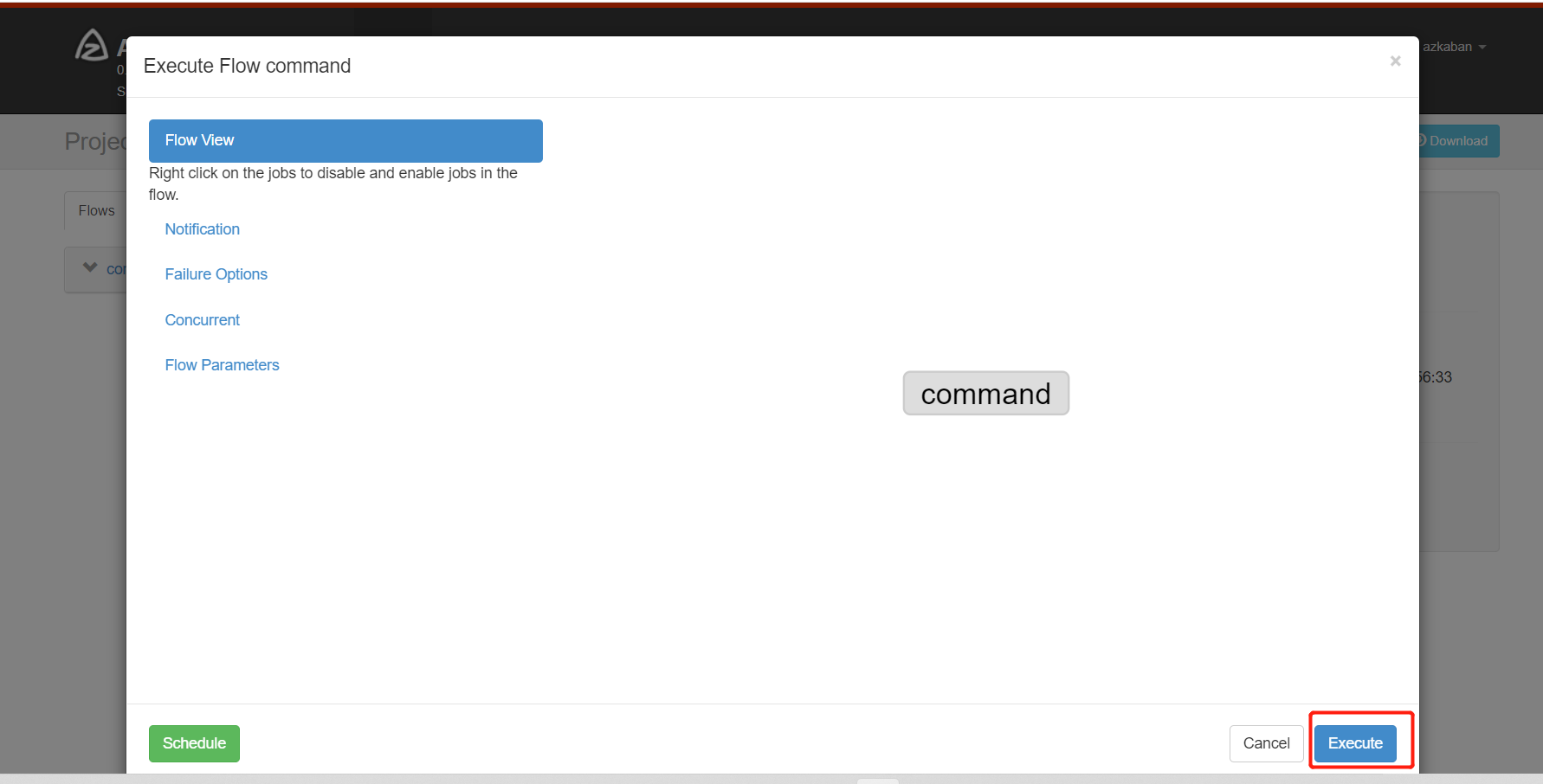
启动执⾏该job
job依赖调度
创建有依赖关系的多个job描述
第⼀个job:foo.job
1 | type=command |
第⼆个job:bar.job依赖foo.job
1 | type=command |
将所有job资源⽂件打到⼀个zip包中
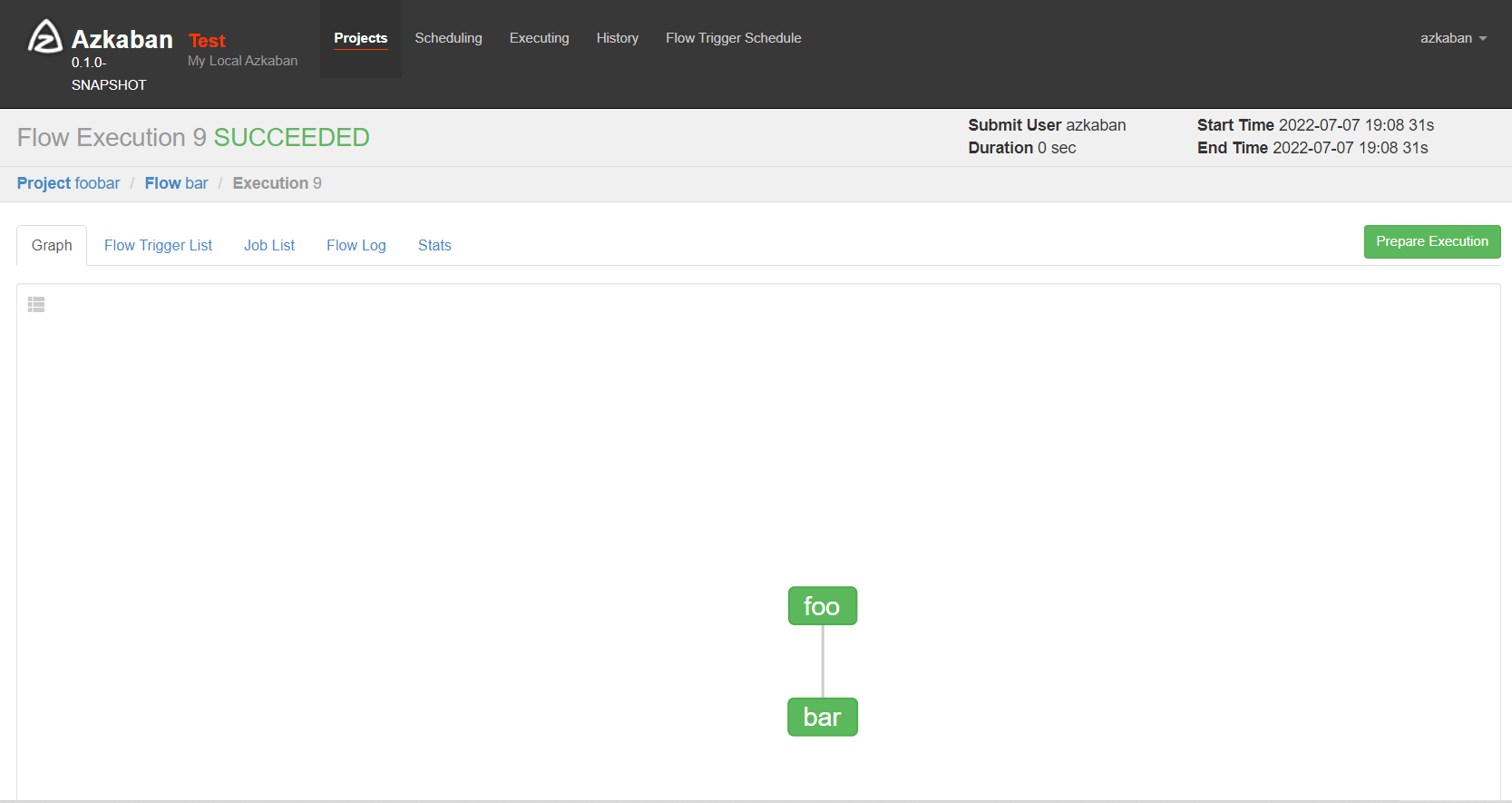
在azkaban的web管理界⾯创建⼯程并上传zip包,启动⼯作流flow
MAPREDUCE任务调度
mr任务依然可以使⽤command的job类型来执⾏
创建job描述⽂件mrwc.job,使用mr程序jar包(示例中直接使⽤hadoop⾃带的example jar)
1 | type=command |
将所有job资源⽂件打到⼀个zip包中
在azkaban的web管理界⾯创建⼯程并上传zip包,启动job
注意: Hadoop和yarn集群要开启
HIVE脚本任务调度
创建hive脚本test.sql
1 | use default; |
创建Job描述⽂件:hivef.job
1 | type=command |
将所有job资源⽂件打到⼀个zip包中创建⼯程并上传zip包,启动job,即test.sql和hivef.job一起打包
定时任务调度
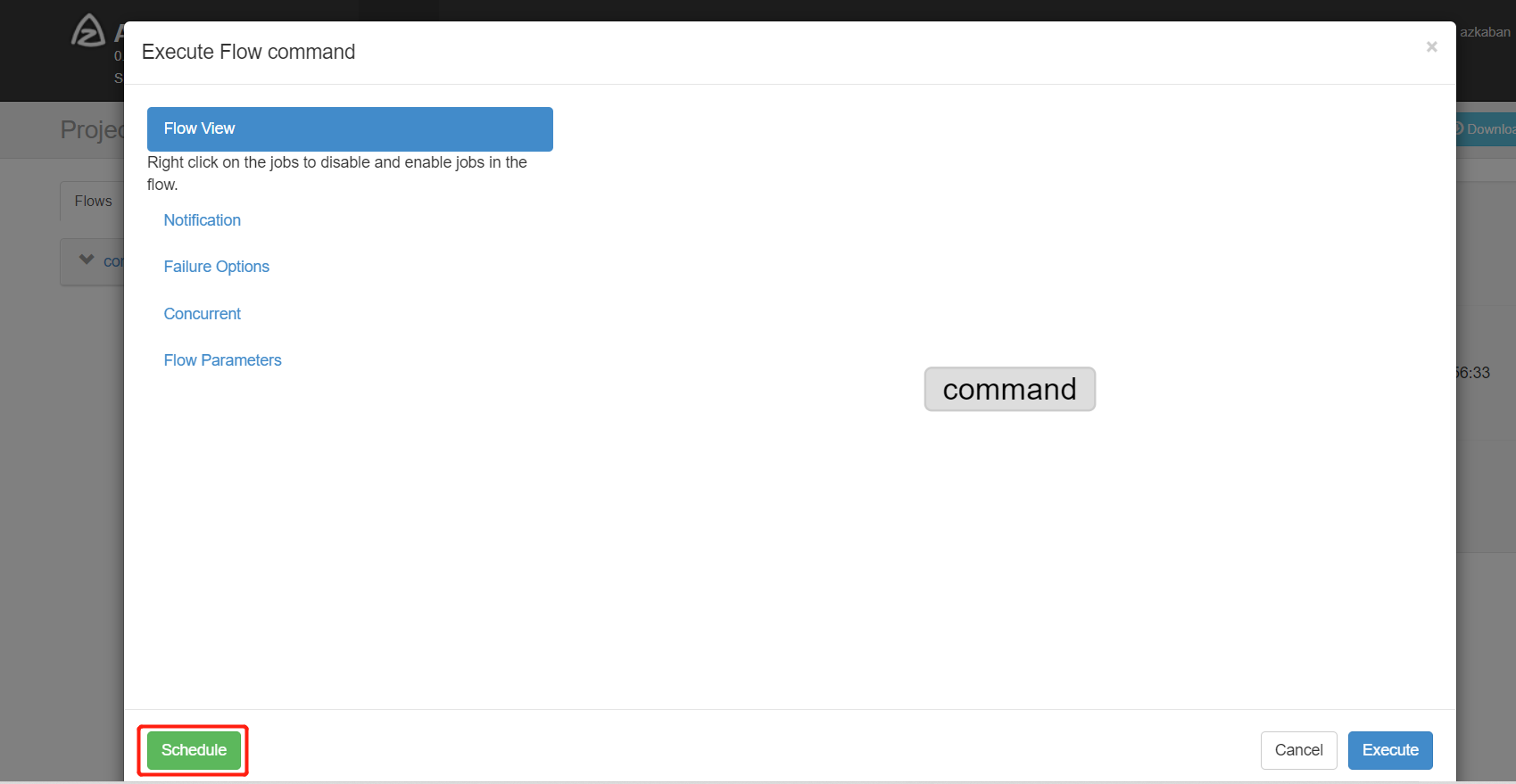
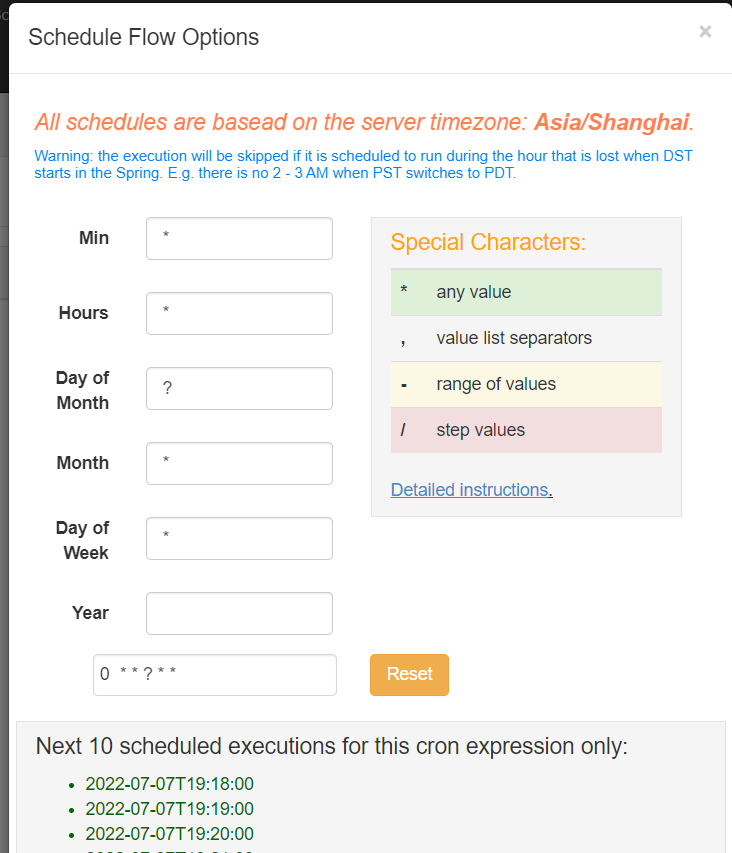
除了⼿动⽴即执⾏⼯作流任务外,azkaban也⽀持配置定时任务调度。开启⽅式如下:
⾸⻚选择待处理的project,选择左边schedule表示配置定时调度信息,选择右边execute表示⽴即执⾏⼯作流任务。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 WeiJia_Rao!
 wechat
wechat alipay
alipay