
Spark-Streaming之DStream转换与输出
DStream转换操作
DStream上的操作与RDD的类似,分为 Transformations(转换)和 Output Operations(输出)两种,此外转换操作中还有一些比较特殊的方法,如:updateStateByKey、transform 以及各种 Window 相关的操作。
| Transformation | Meaning |
|---|---|
| map(func) | 将源DStream中的每个元素通过一个函数func从而得到新的DStreams |
| flatMap(func) | 和map类似,但是每个输入的项可以被映射为0或更多项 |
| filter(func) | 选择源DStream中函数func判为true的记录作为新DStreams |
| repartition(numPartitions) | 通过创建更多或者更少的partition来改变此DStream的并行级别 |
| union(otherStream) | 联合源DStreams和其他DStreams来得到新DStream |
| count() | 统计源DStreams中每个RDD所含元素的个数得到单元素RDD的新DStreams |
| reduce(func) | 通过函数func(两个参数一个输出)来整合源 DStreams中每个RDD元素得到单元素RDD的DStreams。这个函数需要关联从而可以被并行计算 |
| countByValue() | 对于DStreams中元素类型为K调用此函数,得到包含(K,Long)对的新DStream,其中Long值表明相应的K在源DStream中每个RDD出现的频率 |
| reduceByKey(func,[numTasks]) | 对(K,V)对的DStream调用此函数,返回同样(K,V)的新DStream,新DStream中的对应V为使用reduce函数整合而来。默认情况下,这个操作使用Spark默认数量的并行任务(本地模式为2,集群模式中的数量取决于配置参数spark.default.parallelism)。也可以传入可选的参数numTasks来设置不同数量的任务 |
| join(otherStream,[numTasks]) | 两DStream分别为(K,V)和(K,W)对,返回(K,(V,W))对的新DStream |
| cogroup(otherStream,[numTasks]) | 两DStream分别为(K,V)和(K,W)对,返回(K,(Seq[V],Seq[W])对新DStreams |
| transform(func) | 将RDD到RDD映射的函数func作用于源DStream中每个RDD上得到新DStream。这个可用于在DStream的RDD上做任意操作 |
| updateStateByKey(func) | 得到”状态”DStream,其中每个key状态的更新是通过将给定函数用于此key的上一个状态和新值而得到。这个可用于保存每个key值的任意状态数据 |
备注:
-
在DStream与RDD上的转换操作非常类似(无状态的操作)
-
DStream有自己特殊的操作(窗口操作、追踪状态变化操作)
-
在DStream上的转换操作比RDD上的转换操作少
DStream 的转化操作可以分为 无状态(stateless) 和 有状态(stateful) 两种:
-
无状态转化操作。每个批次的处理不依赖于之前批次的数据。常见的 RDD 转化操作,例如 map、filter、reduceByKey 等
-
有状态转化操作。需要使用之前批次的数据 或者是 中间结果来计算当前批次的数据。有状态转化操作包括:基于滑动窗口的转化操作 或 追踪状态变化的转化操作
无状态转换
无状态转化操作就是把简单的 RDD 转化操作应用到每个批次上,也就是转化 DStream 中的每一个 RDD。
常见的无状态转换包括:map、flatMap、filter、repartition、reduceByKey、groupByKey;直接作用在DStream上
重要的转换操作:transform。通过对源DStream的每个RDD应用RDD-to-RDD函数,创建一个新的DStream。支持在新的DStream中做任何RDD操作

这是一个功能强大的函数,它可以允许开发者直接操作其内部的RDD。也就是说开发者,可以提供任意一个RDD到RDD的函数,这个函数在数据流每个批次中都被调用,生成一个新的流。
示例:黑名单过滤
1 | 假设:arr1为黑名单数据(自定义),true表示数据生效,需要被过滤掉;false表示数据未生效 |
方法一:使用外连接
1 | package cn.lagou.streaming.basic |
方法二:使用SQL
1 | package cn.lagou.streaming.basic |
方法三:直接过滤
1 | package cn.lagou.streaming.basic |
有状态转换
有状态的转换主要有两种:窗口操作、状态跟踪操作
窗口操作
Window Operations可以设置窗口大小和滑动窗口间隔来动态的获取当前Streaming的状态。
基于窗口的操作会在一个比 StreamingContext 的 batchDuration(批次间隔)更长的时间范围内,通过整合多个批次的结果,计算出整个窗口的结果。
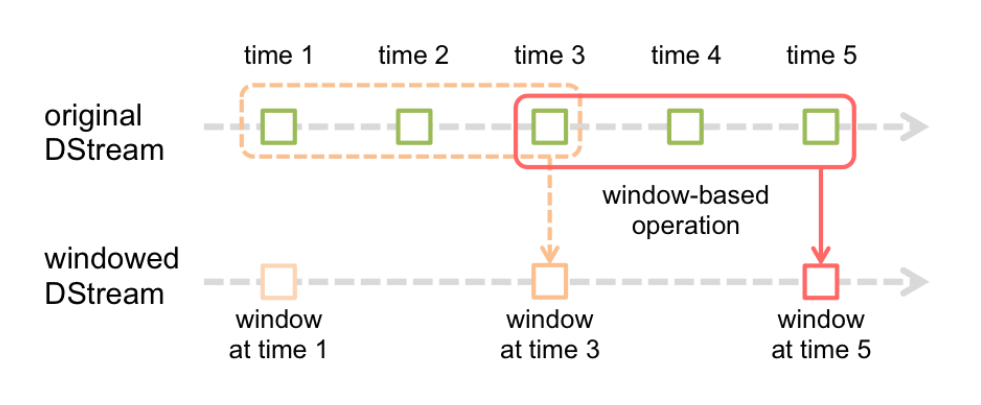
基于窗口的操作需要两个参数:
-
窗口长度(windowDuration)。控制每次计算最近的多少个批次的数据
-
滑动间隔(slideDuration)。用来控制对新的 DStream 进行计算的间隔
两者都必须是 StreamingContext 中批次间隔(batchDuration)的整数倍。
每秒发送1个数字:
1 | package cn.lagou.streaming.basic |
-
案例一
-
观察窗口的数据;
-
观察 batchDuration、windowDuration、slideDuration 三者之间的关系;
-
使用窗口相关的操作;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42package cn.lagou.streaming.basic
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.DStream
object WindowDemo {
def main(args: Array[String]): Unit = {
// 初始化
Logger.getLogger("org").setLevel(Level.ERROR)
val conf = new SparkConf().setAppName("FileDStream").setMaster("local[*]")
val ssc = new StreamingContext(conf, Seconds(5))
// 创建DStream
val lines: DStream[String] = ssc.socketTextStream("localhost", 9999)
// DStream转换和输出
// foreachRDD输出
// lines.foreachRDD{(rdd, time) =>
// println(s"rdd = ${rdd.id}; time = $time")
// rdd.foreach(println)
// }
// 窗口操作
val res1: DStream[String] = lines.reduceByWindow(_ + " " + _, Seconds(20), Seconds(10))
res1.print()
val res2: DStream[String] = lines.window(Seconds(20), Seconds(10))
res2.print()
val res3: DStream[Int] = res2.map(_.toInt).reduce(_ + _)
res3.print()
val res4: DStream[Int] = lines.map(_.toInt).reduceByWindow(_+_, Seconds(20), Seconds(10))
res4.print()
// 启动作业
ssc.start()
ssc.awaitTermination()
}
} -
-
案例二:热点搜索词实时统计。每隔 10 秒,统计最近20秒的词出现的次数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40package cn.lagou.streaming.basic
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.DStream
object HotWordStats {
def main(args: Array[String]): Unit = {
// 初始化
Logger.getLogger("org").setLevel(Level.ERROR)
val conf = new SparkConf().setAppName("FileDStream").setMaster("local[*]")
val ssc = new StreamingContext(conf, Seconds(5))
// 设置检查点,保存状态。在生产中目录应该设置到HDFS
ssc.checkpoint("data/checkpoint")
// 创建DStream
val lines: DStream[String] = ssc.socketTextStream("localhost", 9999)
// DStream转换&输出
// 每隔 10 秒,统计最近20秒的词出现的次数
// window1 = t1 + t2 + t3
// window2 = t3 + t4 + t5
val wordCounts1: DStream[(String, Int)] = lines.flatMap(_.split("\\s+"))
.map((_, 1))
.reduceByKeyAndWindow((x: Int, y: Int) => x+y, Seconds(20), Seconds(10))
wordCounts1.print()
// window2 = w1 - t1 - t2 + t4 + t5
// 需要checkpoint支持
val wordCounts2: DStream[(String, Int)] = lines.flatMap(_.split("\\s+"))
.map((_, 1))
.reduceByKeyAndWindow(_+_, _-_, Seconds(20), Seconds(10))
wordCounts2.print()
// 启动作业
ssc.start()
ssc.awaitTermination()
}
}
updateStateByKey(状态追踪操作)
UpdateStateByKey的主要功能:
-
为Streaming中每一个Key维护一份state状态,state类型可以是任意类型的,可以是自定义对象;更新函数也可以是自定义的
-
通过更新函数对该key的状态不断更新,对于每个新的batch而言,Spark Streaming会在使用updateStateByKey 的时候为已经存在的key进行state的状态更新
-
使用 updateStateByKey 时要开启 checkpoint 功能

流式程序启动后计算wordcount的累计值,将每个批次的结果保存到文件
1 | package cn.lagou.streaming.basic |
统计全局的key的状态,但是就算没有数据输入,也会在每一个批次的时候返回之前的key的状态。
这样的缺点:如果数据量很大的话,checkpoint 数据会占用较大的存储,而且效率也不高。
mapWithState:也是用于全局统计key的状态。如果没有数据输入,便不会返回之前的key的状态,有一点增量的感觉。
这样做的好处是,只关心那些已经发生的变化的key,对于没有数据输入,则不会返回那些没有变化的key的数据。即使数据量很大,checkpoint也不会像updateStateByKey那样,占用太多的存储。
1 | package cn.lagou.streaming.basic |
DStream输出操作
输出操作定义 DStream 的输出操作。
与 RDD 中的惰性求值类似,如果一个 DStream 及其派生出的 DStream 都没有被执行输出操作,那么这些 DStream 就都不会被求值。
如果 StreamingContext 中没有设定输出操作,整个流式作业不会启动。
| Output Operation | Meaning |
|---|---|
| print() | 在运行流程序的Driver上,输出DStream中每一批次数据的最开始10个元素。用于开发和调试 |
| saveAsTextFiles(prefix, [suffix]) | 以text文件形式存储 DStream 的内容。每一批次的存储文件名基于参数中的prefix和suffix |
| saveAsObjectFiles(prefix, [suffix]) | 以 Java 对象序列化的方式将Stream中的数据保存为 Sequence Files。每一批次的存储文件名基于参数中的为"prefix-TIME_IN_MS[.suffix]" |
| saveAsHadoopFiles(prefix, [suffix]) | 将Stream中的数据保存为 Hadoop files。每一批次的存储文件名基于参数中的为"prefix-TIME_IN_MS[.suffix]" |
| foreachRDD(func) | 最通用的输出操作。将函数 func 应用于DStream 的每一个RDD上 |
通用的输出操作 foreachRDD,用来对 DStream 中的 RDD 进行任意计算。在foreachRDD中,可以重用 Spark RDD 中所有的 Action 操作。需要注意的:
-
连接不要定义在 Driver 中
-
连接定义在 RDD的 foreach 算子中,则遍历 RDD 的每个元素时都创建连接,得不偿失
-
应该在 RDD的 foreachPartition 中定义连接,每个分区创建一个连接可以考虑使用连接池
 wechat
wechat alipay
alipay


