
Flume基础应用
Flume 支持的数据源种类有很多,可以来自directory、http、kafka等。Flume提供了Source组件用来采集数据源。
常见的 Source 有:
- avro source:监听 Avro 端口来接收外部 avro 客户端的事件流。
avro-source接收到的是经过avro序列化后的数据,然后反序列化数据继续传输。如果是avrosource的话,源数据必须是经过avro序列化后的数据。利用 Avro source可以实现多级流动、扇出流、扇入流等效果。接收通过flume提供的avro客户端发送的日志信息。
Avro是Hadoop的一个数据序列化系统,由Hadoop的创始人Doug Cutting(也是 Lucene,Nutch等项目的创始人)开发,设计用于支持大批量数据交换的应用。
它的主要特点有:支持二进制序列化方式,可以便捷,快速地处理大量数据;动态语言友好,Avro提供的机制使动态语言可以方便地处理Avro数据;
-
exec source:可以将命令产生的输出作为source。如ping 192.168.234.163、tail -f hive.log。
-
netcat source:一个NetCat Source用来监听一个指定端口,并接收监听到的数据。
-
spooling directory source:将指定的文件加入到“自动搜集”目录中。flume会持续监听这个目录,把文件当做source来处理。注意:一旦文件被放到目录中后,便不能修改,如果修改,flume会报错。此外,也不能有重名的文件。
-
Taildir Source(Flume 1.7):监控指定的多个文件,一旦文件内有新写入的数据,就会将其写入到指定的sink内,本来源可靠性高,不会丢失数据。其不会对于跟踪的文件有任何处理,不会重命名也不会删除,不会做任何修改。目前不支持Windows系统,不支持读取二进制文件,支持一行一行的读取文本文件。
采集到的日志需要进行缓存,Flume提供了Channel组件用来缓存数据。
常见的Channel 有:
-
memory channel:缓存到内存中(最常用)
-
file channel:缓存到文件中
-
JDBC channel:通过JDBC缓存到关系型数据库中
-
kafka channel:缓存到kafka中
缓存的数据最终需要进行保存,Flume提供了Sink组件用来保存数据。
常见的 Sink 有:
-
logger sink:将信息显示在标准输出上,主要用于测试
-
avro sink:Flume events发送到sink,转换为Avro events,并发送到配置好的hostname/port。从配置好的channel按照配置好的批量大小批量获取events
-
null sink:将接收到events全部丢弃
-
HDFS sink:将 events 写进HDFS。支持创建文本和序列文件,支持两种文件类型压缩。文件可以基于数据的经过时间、大小、事件的数量周期性地滚动
-
Hive sink:该sink streams 将包含分割文本或者JSON数据的events直接传送到Hive表或分区中。使用Hive 事务写events。当一系列events提交到Hive时,它们马上可以被Hive查询到
-
HBase sink:保存到HBase中
-
kafka sink:保存到kafka中
日志采集就是根据业务需求选择合适的Source、Channel、Sink,并将其组合在一起。
案例
监听本机端口数据实时显示输出
业务需求:监听本机 8888 端口,Flume将监听的数据实时显示在控制台
需求分析:
-
使用 telnet 工具可以向 8888 端口发送数据
-
监听端口数据,选择 netcat source
-
channel 选择 memory
-
数据实时显示,选择 logger sink
环境为刚才已装Flume的Linux123
1. 安装 telnet 工具
1 | yum install telnet |
2. 检查 8888 端口是否被占用
如果该端口被占用,可以选择使用其他端口完成任务
1 | lsof -i:8888 |
3. 创建 Flume Agent 配置文件
1 | -- 进入Flume安装目录的conf目录下创建flume-netcat-logger.conf文件,并添加配置 |
Memory Channel 是使用内存缓冲Event的Channel实现。速度比较快速,容量会受到 jvm 内存大小的限制,可靠性不够高。适用于允许丢失数据,但对性能要求较高的日志采集业务。
4. 启动Flume Agent,进入日志监听页面
1 | flume-ng agent --name a1 --conf-file $FLUME_HOME/conf/flume-netcat-logger.conf -Dflume.root.logger=INFO,console |
-
name。定义agent的名字,要与参数文件一致
-
conf-file。指定参数文件位置
-
-D表示flume运行时动态修改 flume.root.logger 参数属性值,并将控制台日志打印级别设置为INFO级别。日志级别包括:log、info、warn、error
5. 再打开一个Linux123的窗口,使用 telnet 向本机的 8888 端口发送消息
1 | telnet Linux123 8888 |

6. 在 Flume 日志监听页面查看数据接收情况

监控日志文件信息到HDFS
业务需求:监控本地日志文件,收集内容实时上传到HDFS
需求分析:
-
使用 tail -F 命令即可找到本地日志文件产生的信息
-
source 选择 exec。exec 监听一个指定的命令,获取命令的结果作为数据源。
-
source组件从这个命令的结果中取数据。当agent进程挂掉重启后,可能存在数据丢失
-
channel 选择 memory
-
sink 选择 HDFS
1 | tail -f 等同于--follow=descriptor,根据文件描述符进行追踪,当文件改名或被删除,追踪停止 |
环境为刚才已装Flume的Linux123
1. 环境准备。
Flume要想将数据输出到HDFS,必须持有Hadoop相关jar包。
将commons-configuration-1.6.jar hadoop-auth-2.9.2.jar hadoop-common-2.9.2.jar hadoop-hdfs-2.9.2.jar commons-io-2.4.jar htrace-core4-4.1.0-incubating.jar拷贝到 $FLUME_HOME/lib 文件夹下
1 | cd $HADOOP_HOME/share/hadoop/httpfs/tomcat/webapps/webhdfs/WEB-INF/lib |
2. 创建配置文件
1 | -- 进入Flume安装目录的conf目录下创建flume-exec-hdfs.conf文件,并添加配置 |
3. 启动Agent
1 | flume-ng agent --name a2 --conf-file $FLUME_HOME/conf/flume-exec-hdfs.conf -Dflume.root.logger=INFO,console |
4. 启动Hadoop和Hive,操作Hive产生日志
1 | start-dfs.sh |
5. 在HDFS上查看文件
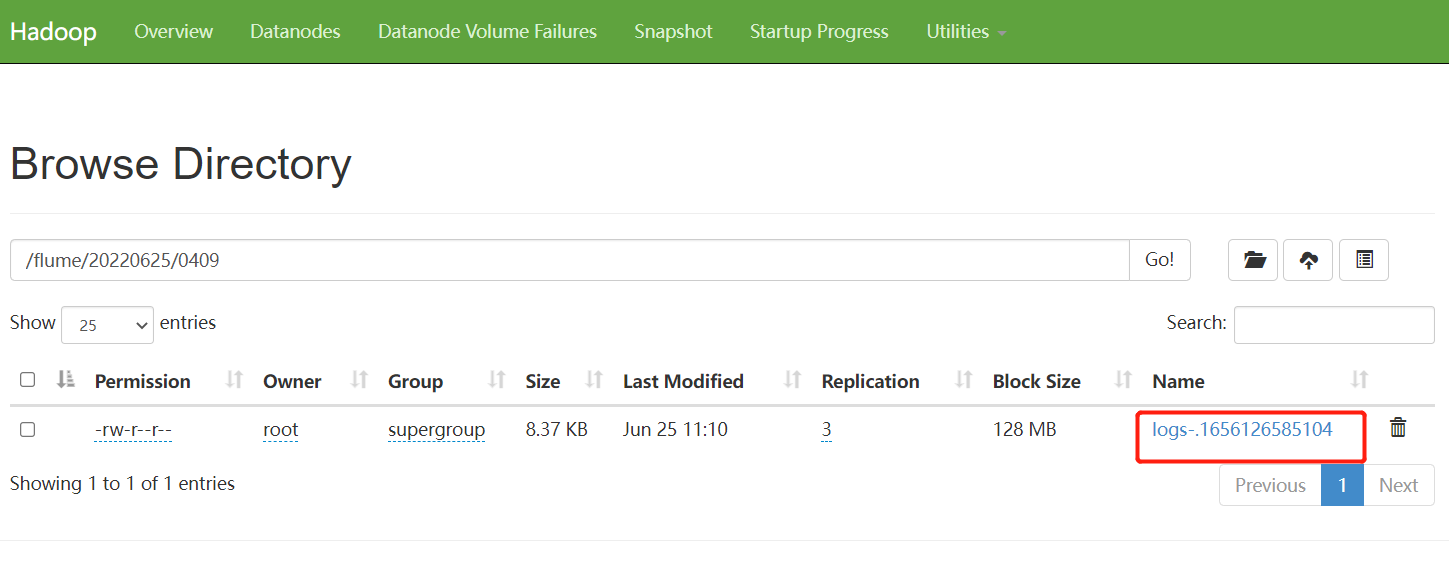
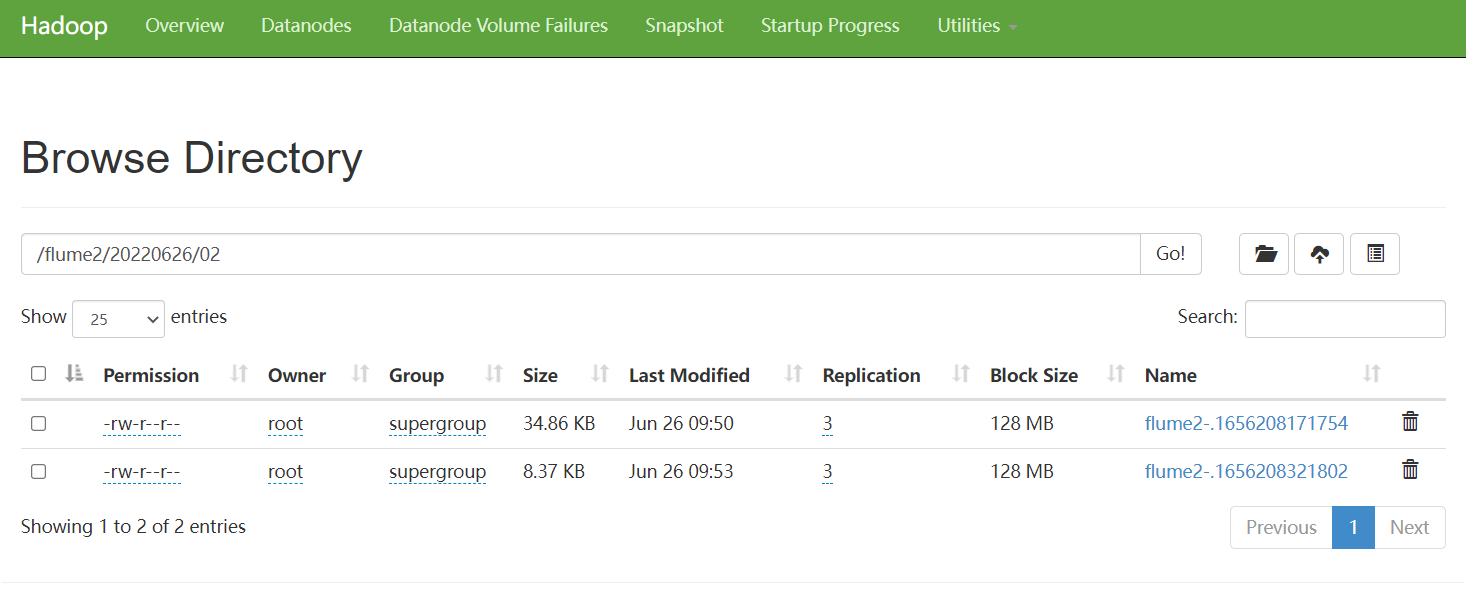
监控目录采集信息到HDFS
业务需求:监控指定目录,收集信息实时上传到HDFS
需求分析:
-
source 选择 spooldir。spooldir 能够保证数据不丢失,且能够实现断点续传,但延迟较高,不能实时监控
-
channel 选择 memory
-
sink 选择 HDFS
spooldir Source监听一个指定的目录,即只要向指定目录添加新的文件,source组件就可以获取到该信息,并解析该文件的内容,写入到channel。sink处理完之后,标记该文件已完成处理,文件名添加 .completed 后缀。虽然是自动监控整个目录,但是只能监控文件,如果以追加的方式向已被处理的文件中添加内容,source并不能识别。
需要注意的是:
-
拷贝到spool目录下的文件不可以再打开编辑
-
无法监控子目录的文件夹变动
-
被监控文件夹每500毫秒扫描一次文件变动
-
适合用于同步新文件,但不适合对实时追加日志的文件进行监听并同步
环境为刚才已装Flume的Linux123
1. 创建配置文件
1 | -- 进入Flume安装目录的conf目录下创建flume-spooldir-hdfs.conf文件,并添加配置 |
2. 启动Agent
1 | flume-ng agent --name a3 --conf-file $FLUME_HOME/conf/flume-spooldir-hdfs.conf -Dflume.root.logger=INFO,console |
3. 向upload文件夹中添加文件
1 | cp nohup.out /root/upload/a.log |
4. 查看HDFS上的数据
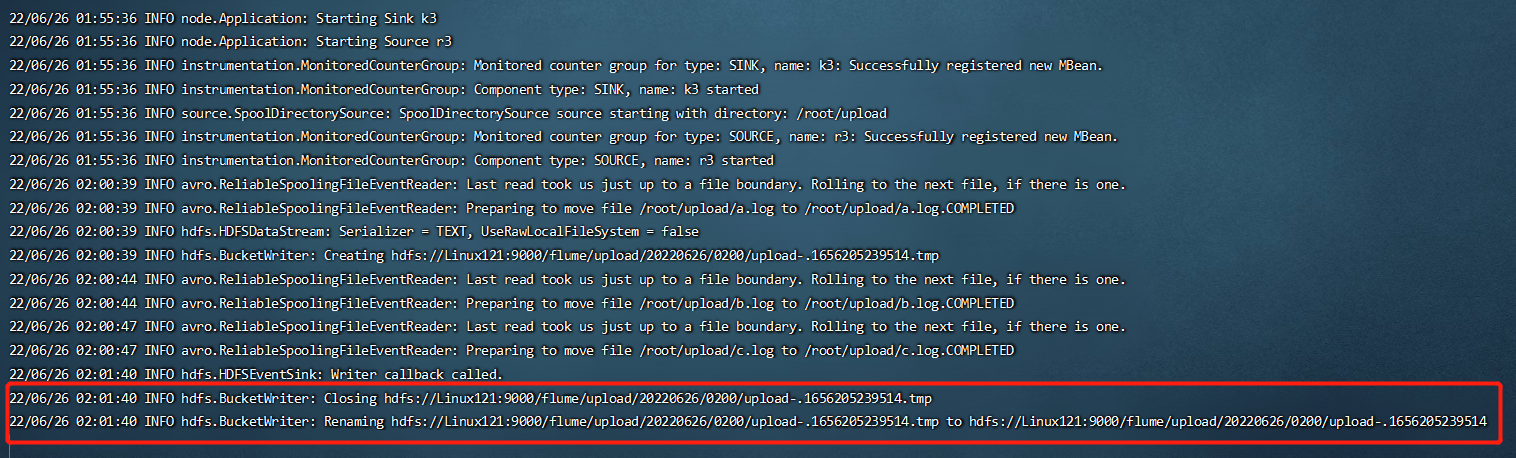
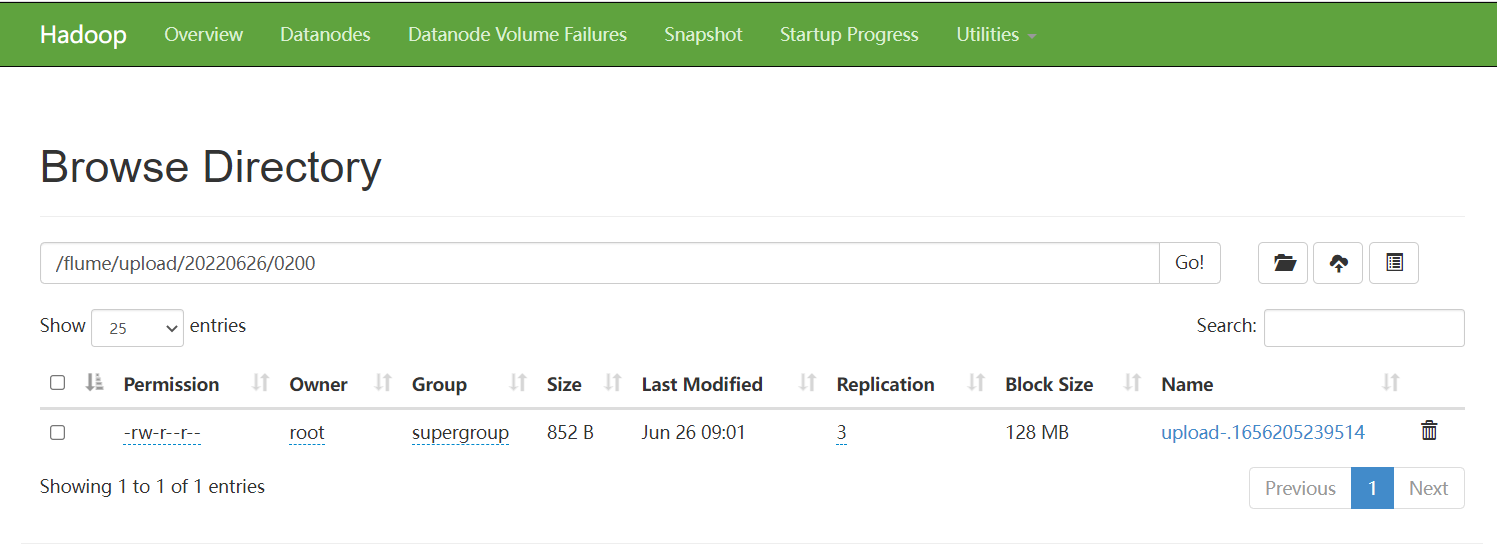
一般使用 HDFS Sink 都会采用滚动生成文件的方式,滚动生成文件的策略有:
-
基于时间
hdfs.rollInterval
缺省值:30,单位秒
0禁用
-
基于文件大小
hdfs.rollSize
缺省值:1024字节
0禁用
-
基于event数量
hdfs.rollCount
10
0禁用
-
基于文件空闲时间
hdfs.idleTimeout
缺省值:0。禁用
-
基于HDFS文件副本数
hdfs.minBlockReplicas
默认:与HDFS的副本数一致
要将该参数设置为1;否则HFDS文件所在块的复制会引起文件滚动
HDFS Sink 其他重要配置:
-
hdfs.useLocalTimeStamp
使用本地时间,而不是event header的时间戳
默认值:false
-
hdfs.round
时间戳是否四舍五入
默认值false
如果为true,会影响所有的时间,除了t%
-
hdfs.roundValue
四舍五入的最高倍数(单位配置在hdfs.roundUnit),但是要小于当前时间
默认值:1
-
hdfs.roundUnit
可选值为:second、minute、hour
默认值:second
如果要避免HDFS Sink产生小文件,参考如下参数设置:
1 | a1.sinks.k1.type=hdfs |
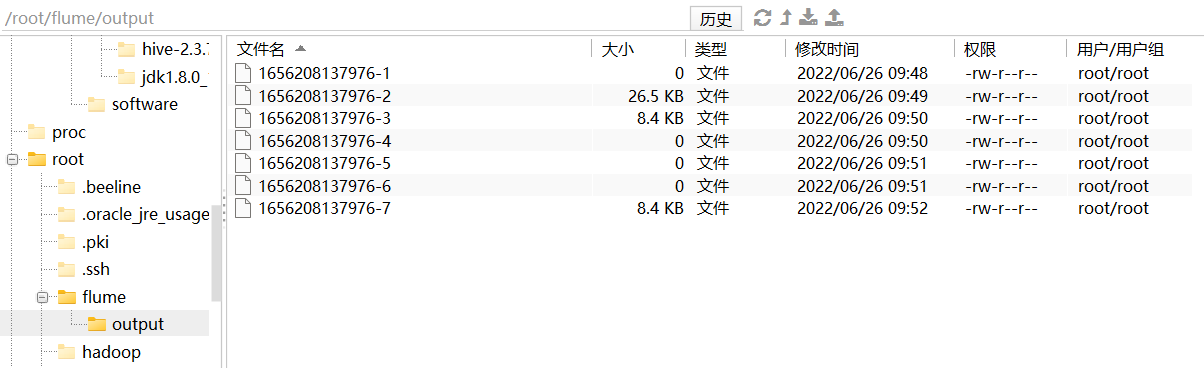
监控日志文件采集数据到HDFS、本地文件系统
业务需求:监控日志文件,收集信息上传到HDFS 和 本地文件系统
需求分析:
-
需要多个Agent级联实现
-
source 选择 taildir
-
channel 选择 memory
-
最终的 sink 分别选择 hdfs、file_roll
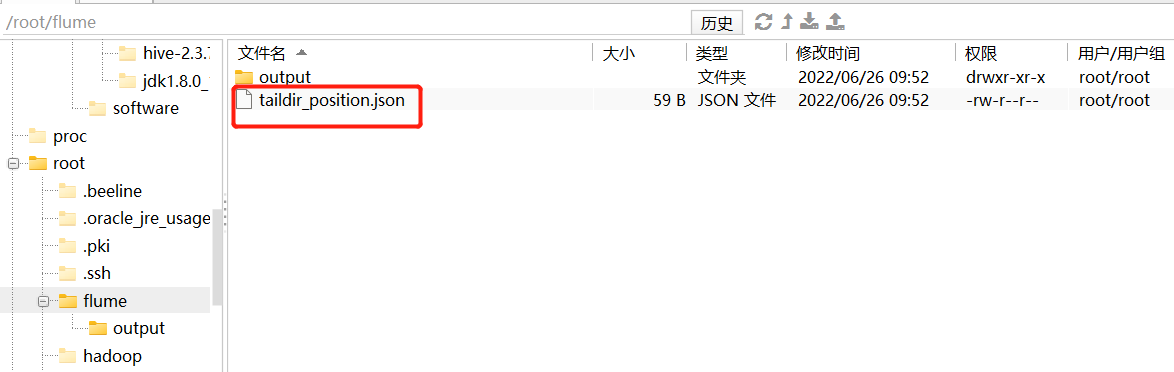
taildir Source。Flume 1.7.0加入的新Source,相当于 spooldir source + exec source。可以监控多个目录,并且使用正则表达式匹配该目录中的文件名进行实时收集。实时监控一批文件,并记录每个文件最新消费位置,agent进程重启后不会有数据丢失的问题。
目前不适用于Windows系统;其不会对于跟踪的文件有任何处理,不会重命名也不会删除,不会做任何修改。不支持读取二进制文件,支持一行一行的读取文本文件。
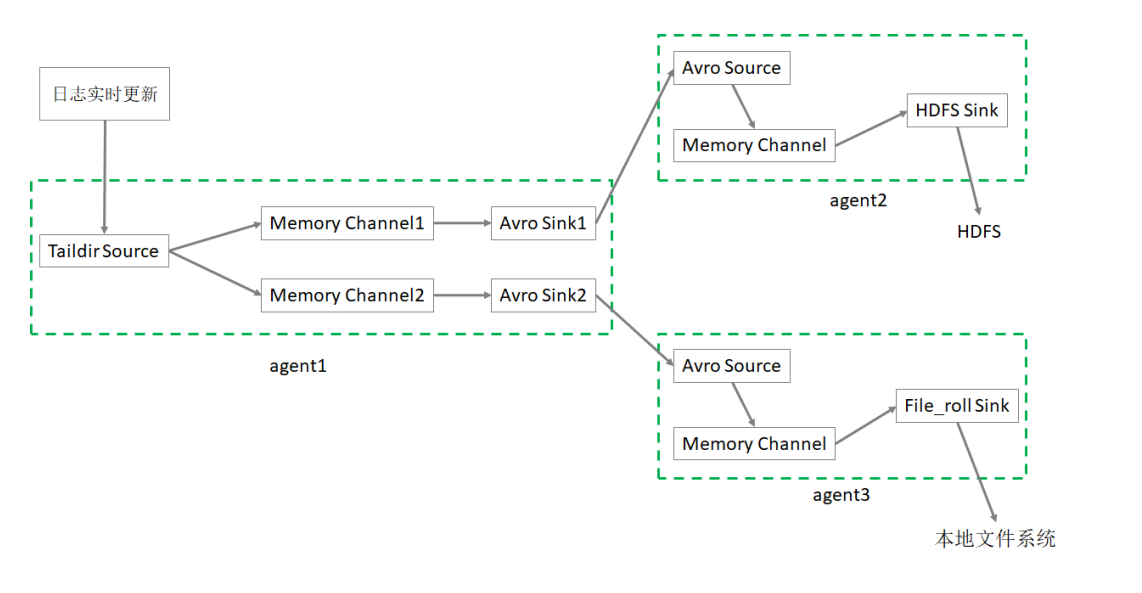
环境为刚才已装Flume的Linux123
1. 创建第一个配置文件
flume-taildir-avro.conf 配置文件包括:1个 taildir source,2个 memory channel,2个 avro sink
1 | -- 进入Flume安装目录的conf目录下创建flume-taildir-avro.conf文件,并添加配置 |
2. 创建第二个配置文件
flume-avro-hdfs.conf配置文件包括:1个 avro source,1个 memory channel,1个 hdfs sink
1 | -- 进入Flume安装目录的conf目录下创建flume-avro-hdfs.conf文件,并添加配置 |
3. 创建第三个配置文件
flume-avro-file.conf配置文件包括:1个 avro source,1个 memory channel,1个 file_roll sink
1 | -- 进入Flume安装目录的conf目录下创建flume-avro-file.conf文件,并添加配置 |
4. 分别启动3个Agent
1 | # 创建所需文件目录 |
5. 执行hive命令产生日志
1 | hive -e "show databases" |
6. 分别检查HDFS文件、本地文件、以及消费位置文件
 wechat
wechat alipay
alipay

