
RDD编程之Key-Value操作与输入与输出
Key-Value RDD操作
RDD整体上分为 Value 类型和 Key-Value 类型。
前面介绍的是 Value 类型的RDD的操作,实际使用更多的是 key-value 类型的RDD,也称为 PairRDD。
Value 类型RDD的操作基本集中在 RDD.scala 中;
key-value 类型的RDD操作集中在 PairRDDFunctions.scala 中;
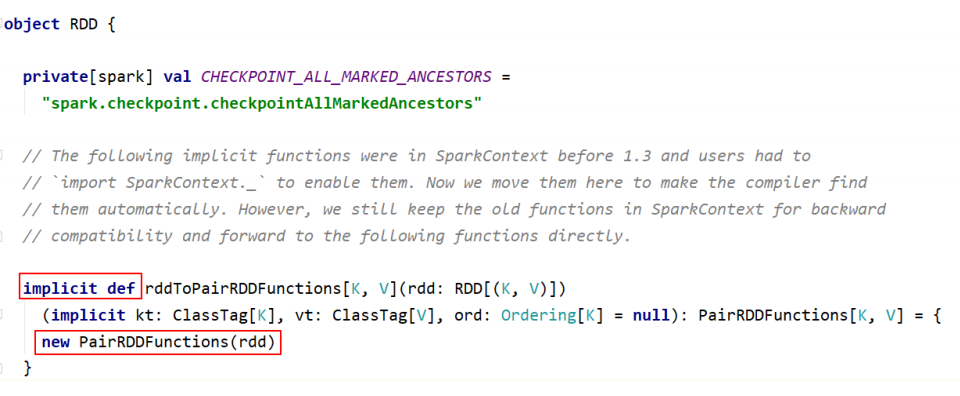
前面介绍的大多数算子对 Pair RDD 都是有效的。Pair RDD还有属于自己的Transformation、Action 算子;
创建Pair RDD
1 | scala> val arr = (1 to 10).toArray |
Transformation操作
类似 map 操作
mapValues / flatMapValues / keys / values,这些操作都可以使用 map 操作实现,是简化操作。
1 | scala> val a = sc.parallelize(List((1,2),(3,4),(5,6))) |
聚合操作【重要、难点】
**PariRDD(k, v)**使用范围广,聚合
groupByKey / reduceByKey / foldByKey / aggregateByKey
combineByKey(OLD) / combineByKeyWithClassTag(NEW) => 底层实现
subtractByKey:类似于subtract,删掉 RDD 中键与 other RDD 中的键相同的元素
小案例:给定一组数据:(“spark”, 12), (“hadoop”, 26), (“hadoop”, 23), (“spark”, 15), (“scala”, 26), (“spark”, 25), (“spark”, 23), (“hadoop”, 16), (“scala”, 24), (“spark”, 16), 键值对的key表示图书名称,value表示某天图书销量。计算每个键对应的平均值,也就是计算每种图书的每天平均销量。
1 | scala> val rdd = sc.makeRDD(Array(("spark", 12), ("hadoop", 26), ("hadoop", 23), ("spark", 15), ("scala", 26), ("spark", 25), ("spark", 23), ("hadoop", 16), ("scala", 24), ("spark", 16))) |
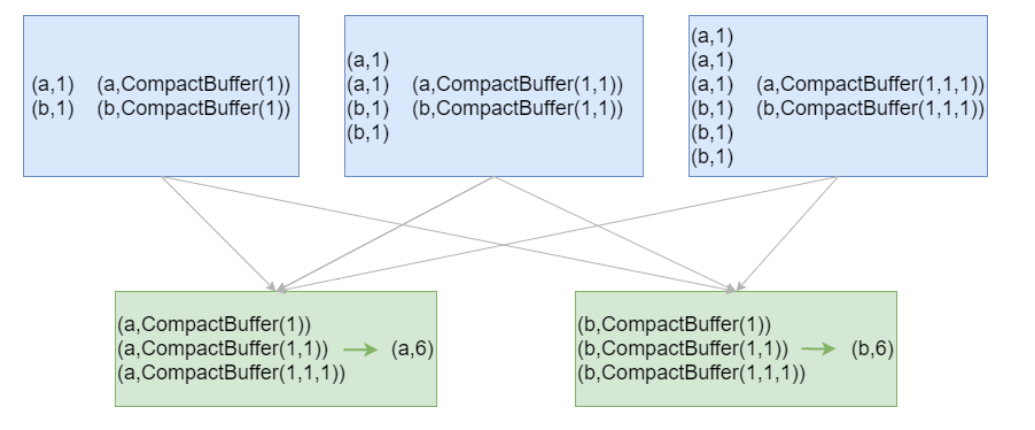
结论:效率相等用最熟悉的方法;groupByKey在一般情况下效率低,尽量少用
初学:最重要的是实现;如果使用了groupByKey,寻找替换的算子实现;
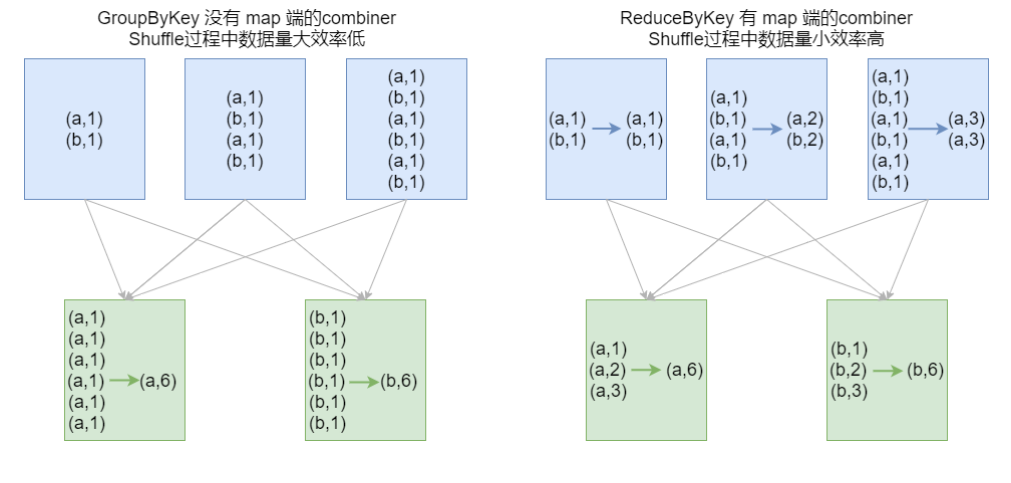
groupByKey Shuffle过程中传输的数据量大,效率低
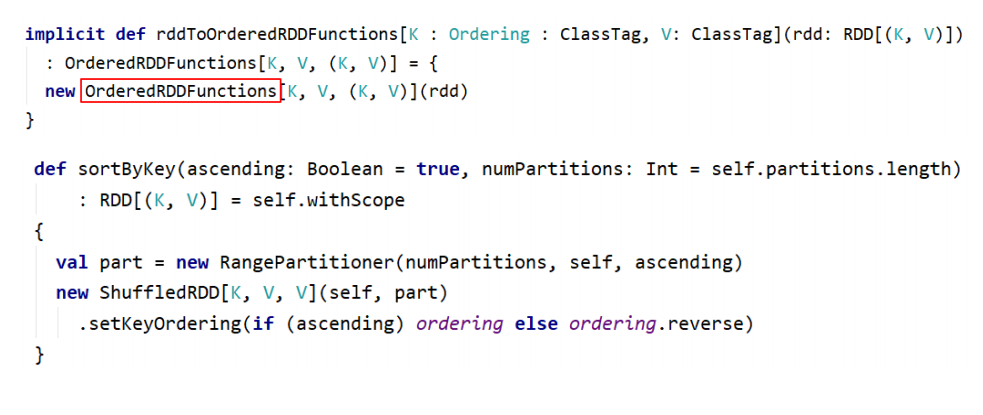
排序操作
sortByKey:sortByKey函数作用于PairRDD,对Key进行排序。在 org.apache.spark.rdd.OrderedRDDFunctions 中实现:
1 | scala> val a = sc.parallelize(List("wyp", "iteblog", "com", "397090770", "test")) |
join操作
cogroup / join / leftOuterJoin / rightOuterJoin / fullOuterJoin

1 | scala> val rdd1 = sc.makeRDD(Array((1,"Spark"), (2,"Hadoop"), (3,"Kylin"), (4,"Flink"))) |
Action操作
collectAsMap / countByKey / lookup(key)
countByKey源码:

lookup(key):高效的查找方法,只查找对应分区的数据(如果RDD有分区器的话)
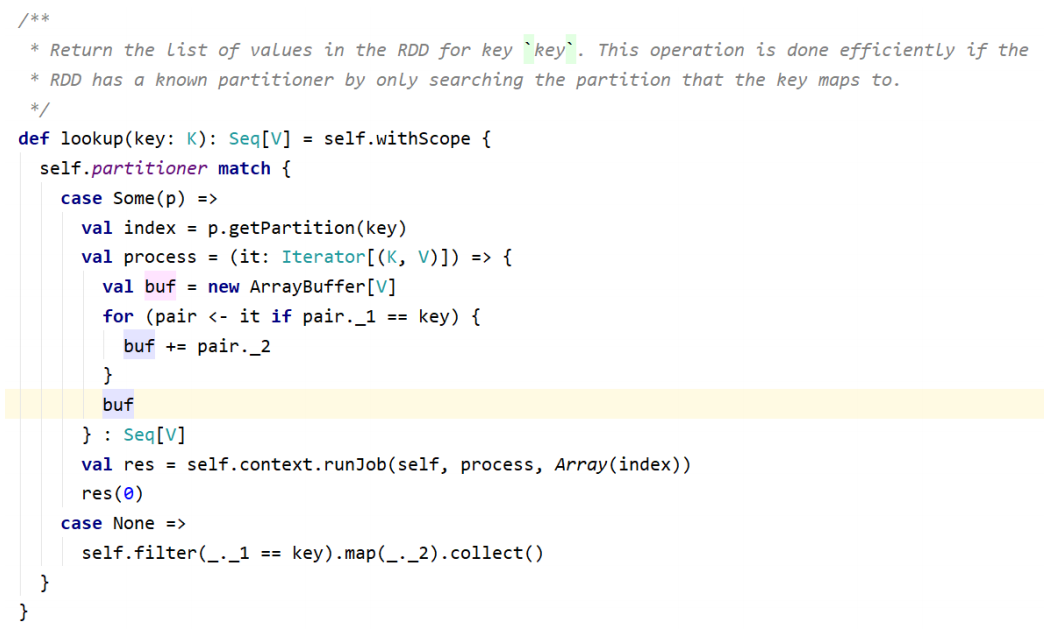
1 | scala> val rdd1 = sc.makeRDD(Array(("1","Spark"),("2","Hadoop"), ("3","Scala"),("1","Java"))) |
输入与输出
文件输入与输出
文本文件
数据读取:textFile(String)。可指定单个文件,支持通配符。
这样对于大量的小文件读取效率并不高,应该使用 wholeTextFiles
def wholeTextFiles(path: String, minPartitions: Int = defaultMinPartitions):RDD[(String, String)])
返回值RDD[(String, String)],其中Key是文件的名称,Value是文件的内容
数据保存:saveAsTextFile(String)。指定的输出目录。
csv文件
读取 CSV(Comma-Separated Values)/TSV(Tab-Separated Values) 数据和读取 JSON 数据相似,都需要先把文件当作普通文本文件来读取数据,然后通过将每一行进行解析实现对CSV的读取。
CSV/TSV 数据的输出也是需要将结构化RDD通过相关的库转换成字符串RDD,然后使用 Spark 的文本文件 API 写出去。
json文件
如果 JSON 文件中每一行就是一个JSON记录,那么可以通过将JSON文件当做文本文件来读取,然后利用相关的JSON库对每一条数据进行JSON解析。
JSON数据的输出主要是通过在输出之前将由结构化数据组成的 RDD 转为字符串RDD,然后使用 Spark 的文本文件 API 写出去。
json文件的处理使用SparkSQL最为简洁。
SequenceFile
SequenceFile文件是Hadoop用来存储二进制形式的key-value对而设计的一种平面文件(Flat File)。 Spark 有专门用来读取 SequenceFile 的接口。在 SparkContext中,可以调用:sequenceFile[keyClass, valueClass];
调用 saveAsSequenceFile(path) 保存PairRDD,系统将键和值能够自动转为Writable类型。
对象文件
对象文件是将对象序列化后保存的文件,采用Java的序列化机制。
通过 objectFilek,v 接收一个路径,读取对象文件,返回对应的 RDD,也可以通过调用saveAsObjectFile() 实现对对象文件的输出。因为是序列化所以要指定类型。
JDBC
详见Scala算子综合应用案例博客文档
 wechat
wechat alipay
alipay




