-
kafka⽇志管理⼦系统的⼊⼝。⽇志管理器负责⽇志的创建、抽取、和清理。
-
所有的读写操作都代理给具体的Log实例。
-
⽇志管理器在⼀个或多个⽬录维护⽇志。新的⽇志创建到拥有最少log的⽬录中。
-
分区不移动。
-
通过⼀个后台线程通过定期截断多余的⽇志段来处理⽇志保留。
启动Kafka服务器的脚本。

main⽅法中创建KafkaServerStartable对象。
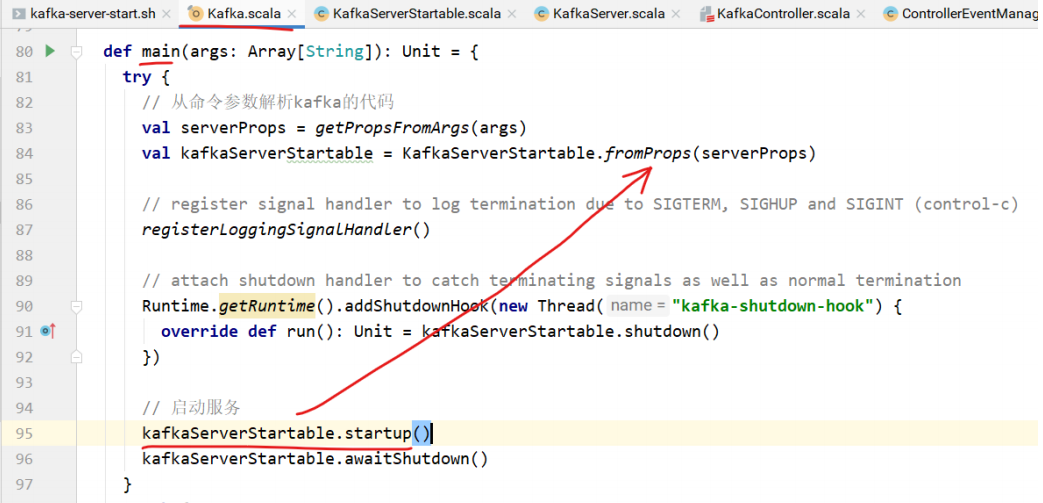
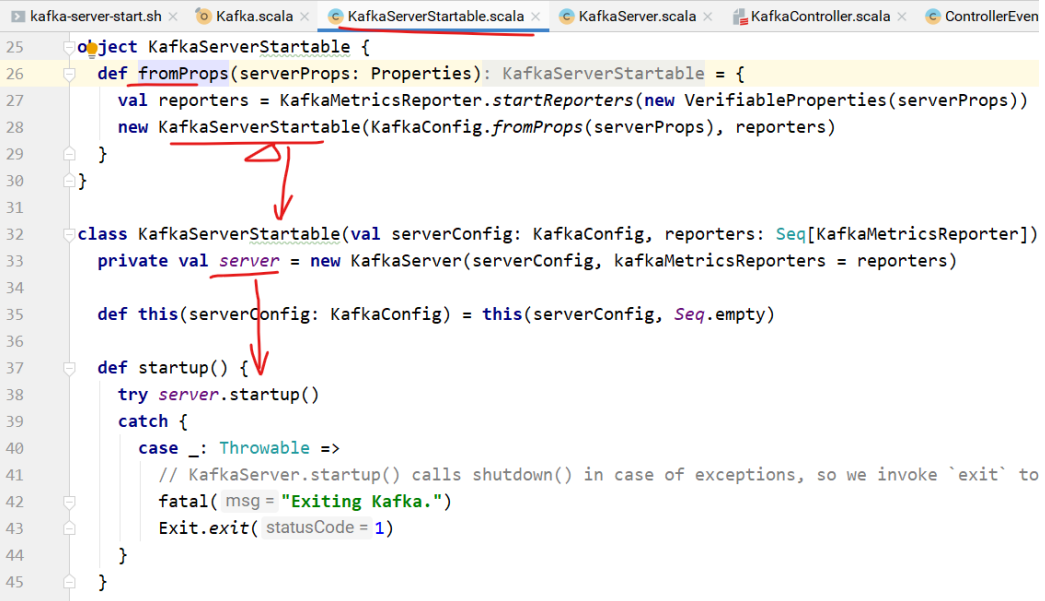
该类中包含KakfaServer对象,startup⽅法调⽤的是KafkaServer的startup⽅法。
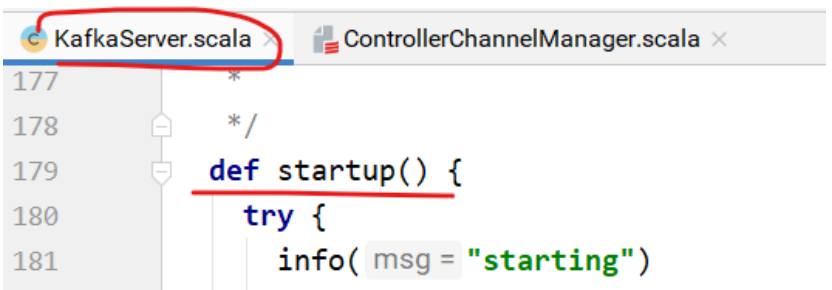
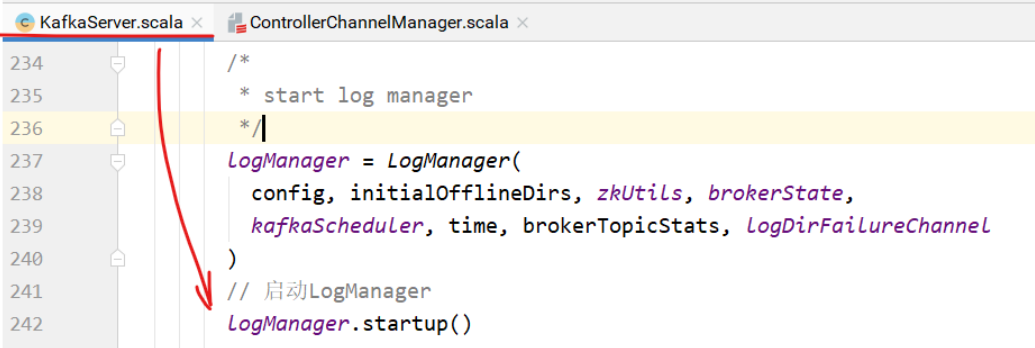
KafkaServer的startup⽅法中,启动了LogManager。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| /**
* @param logDirs 主题分区⽬录的File对象
* @param initialOfflineDirs
* @param topicConfigs 主题配置
* @param defaultConfig 主题的默认配置
* @param cleanerConfig ⽇志清理器配置
* @param ioThreads IO线程数
* @param flushCheckMs
* @param flushRecoveryOffsetCheckpointMs
* @param flushStartOffsetCheckpointMs
* @param retentionCheckMs 检查⽇志保留的时间
* @param maxPidExpirationMs
* @param scheduler
* @param brokerState
* @param brokerTopicStats
* @param logDirFailureChannel
* @param time 时间
*/
|
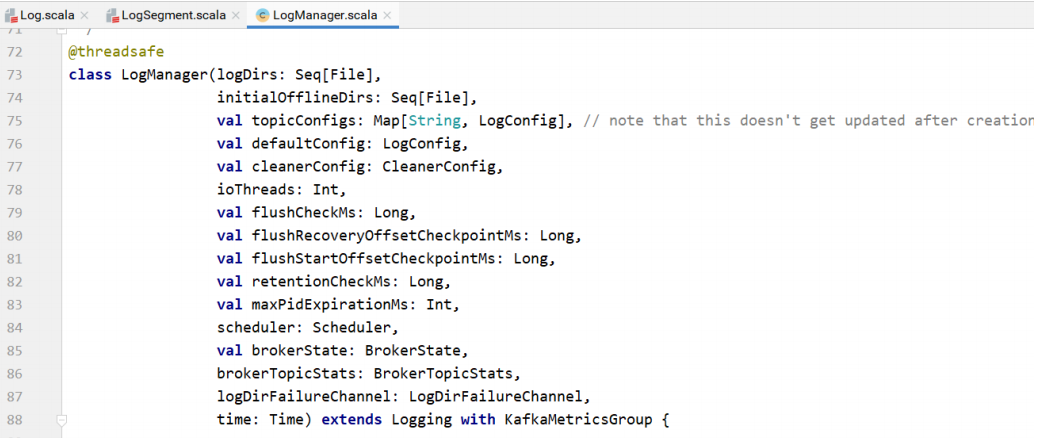
LogManager的startup⽅法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| /**
* 启动后台线程们⽤于将⽇志刷盘以及⽇志的清理
*/
def startup() {
if (scheduler != null) {
info("Starting log cleanup with a period of %d ms.".format(retentionCheckMs))
// ⽤于清除⽇志⽚段的调度任务,没有压缩,周期性执⾏
scheduler.schedule("kafka-log-retention",
cleanupLogs _,
delay = InitialTaskDelayMs,
period = retentionCheckMs,
TimeUnit.MILLISECONDS)
info("Starting log flusher with a default period of %d ms.".format(flushCheckMs))
// ⽤于⽇志⽚段刷盘的调度任务,周期性执⾏
scheduler.schedule("kafka-log-flusher",
flushDirtyLogs _,
delay = InitialTaskDelayMs,
period = flushCheckMs,
TimeUnit.MILLISECONDS)
// ⽤于将当前broker上各个分区的恢复点写到⽂本⽂件的调度任务,周期性执⾏
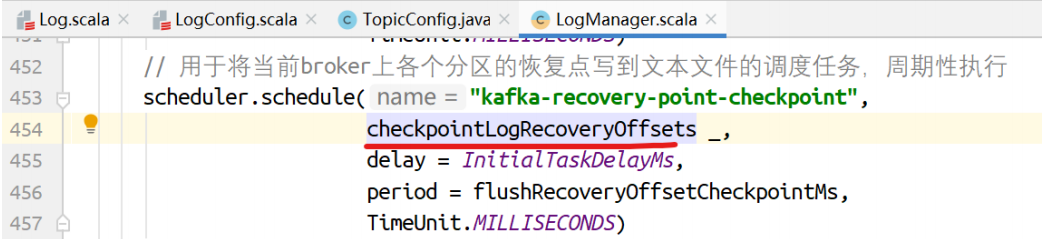
scheduler.schedule("kafka-recovery-point-checkpoint",
checkpointLogRecoveryOffsets _,
delay = InitialTaskDelayMs,
period = flushRecoveryOffsetCheckpointMs,
TimeUnit.MILLISECONDS)
// ⽤于将当前broker上各个分区起始偏移量写到⽂本⽂件的调度任务,周期性执⾏
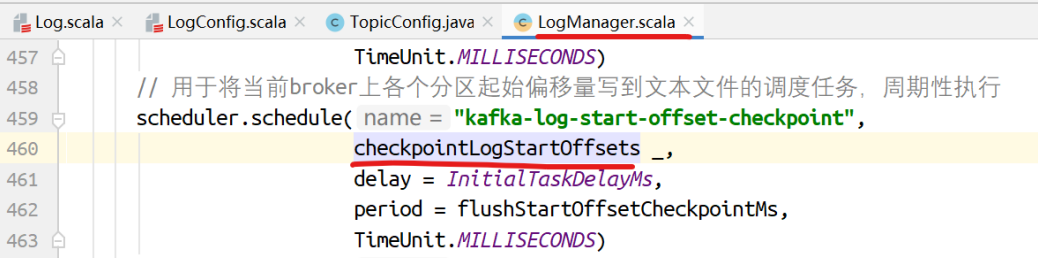
scheduler.schedule("kafka-log-start-offset-checkpoint",
checkpointLogStartOffsets _,
delay = InitialTaskDelayMs,
period = flushStartOffsetCheckpointMs,
TimeUnit.MILLISECONDS)
scheduler.schedule("kafka-delete-logs",
deleteLogs _,
delay = InitialTaskDelayMs,
period = defaultConfig.fileDeleteDelayMs,
TimeUnit.MILLISECONDS)
}
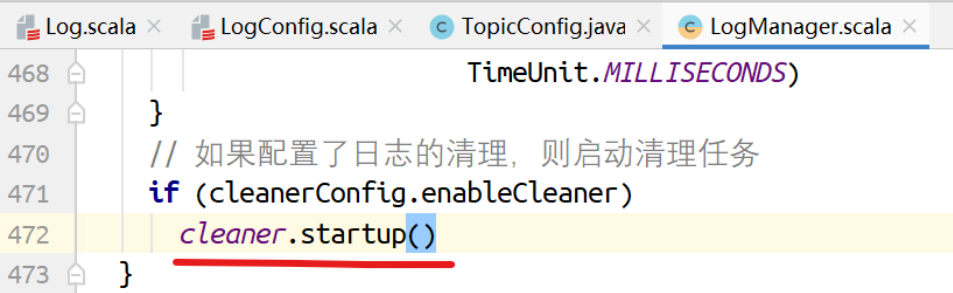
// 如果配置了⽇志的清理,则启动清理任务
if (cleanerConfig.enableCleaner)
cleaner.startup()
}
|
清除⽇志⽚段
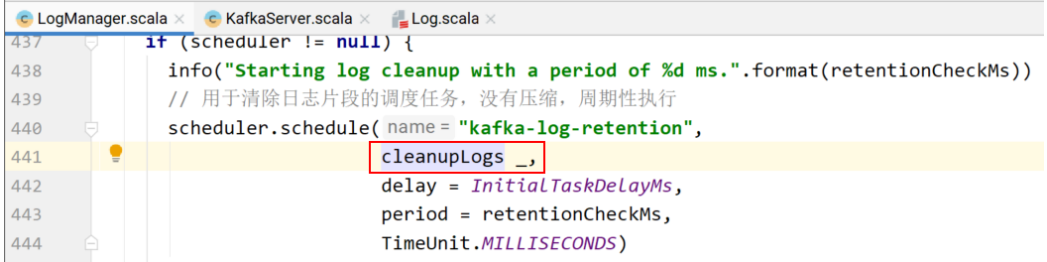
cleanupLogs的具体实现。
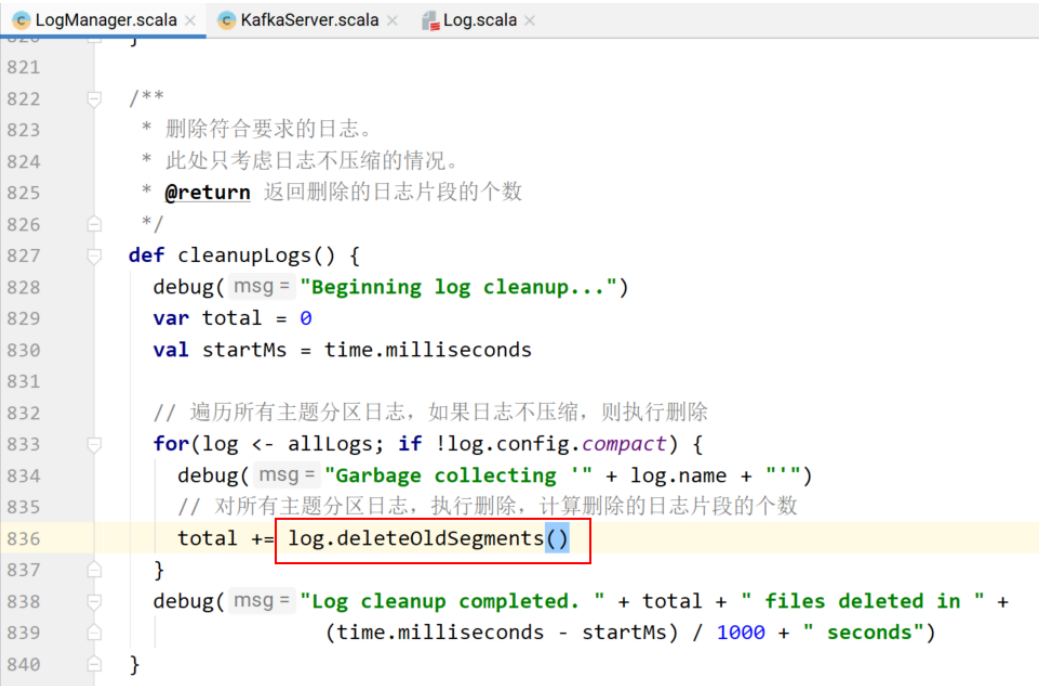
deleteOldSegments()的实现。
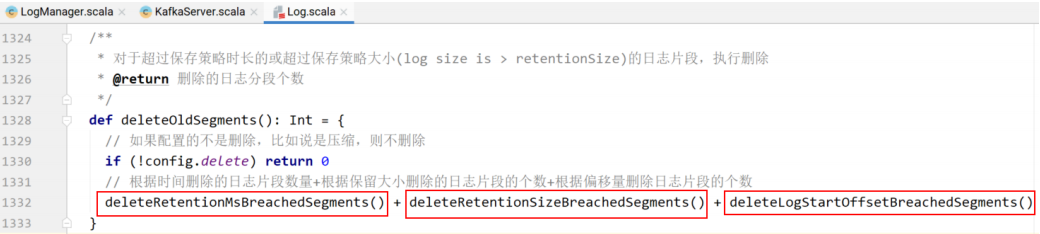
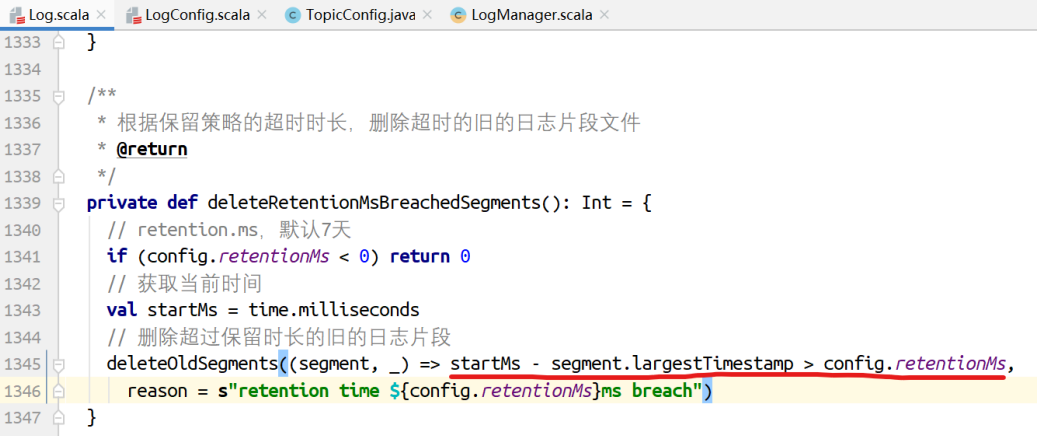
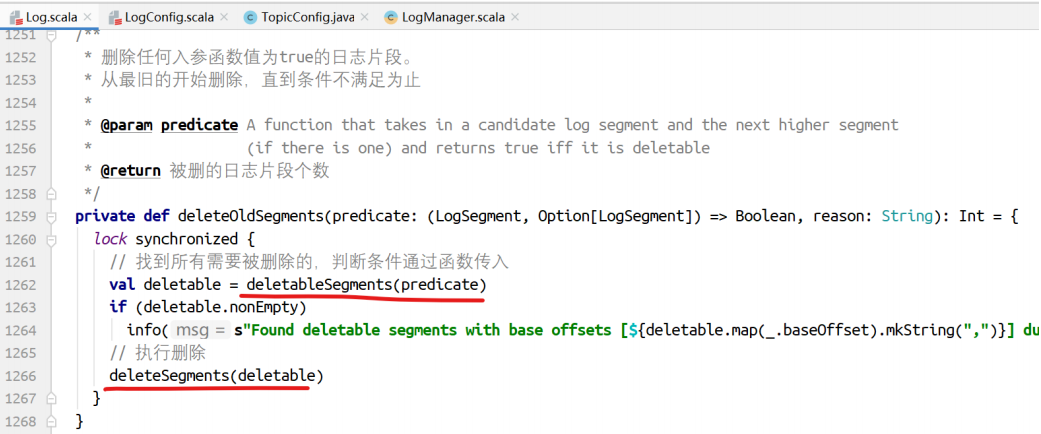
⾸先找到所有可以删除的⽇志⽚段,然后执⾏删除。
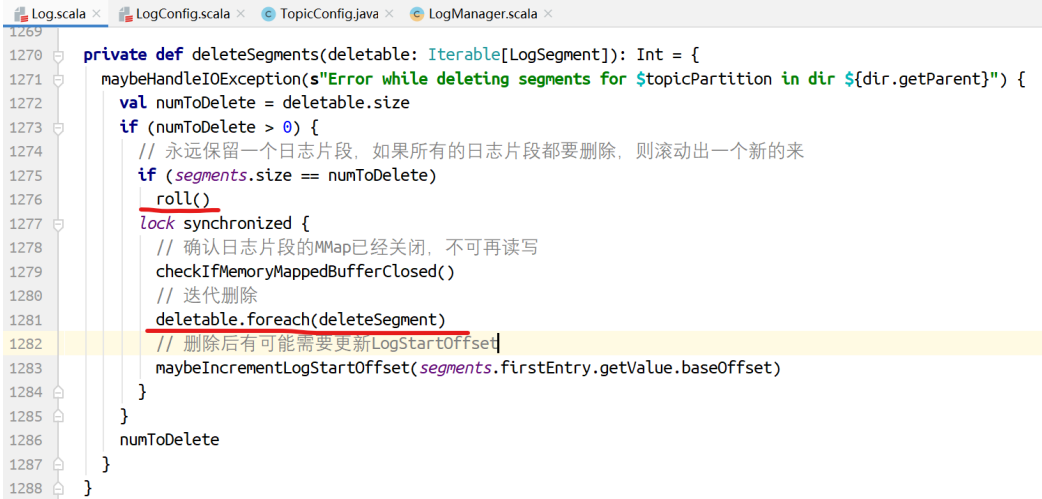
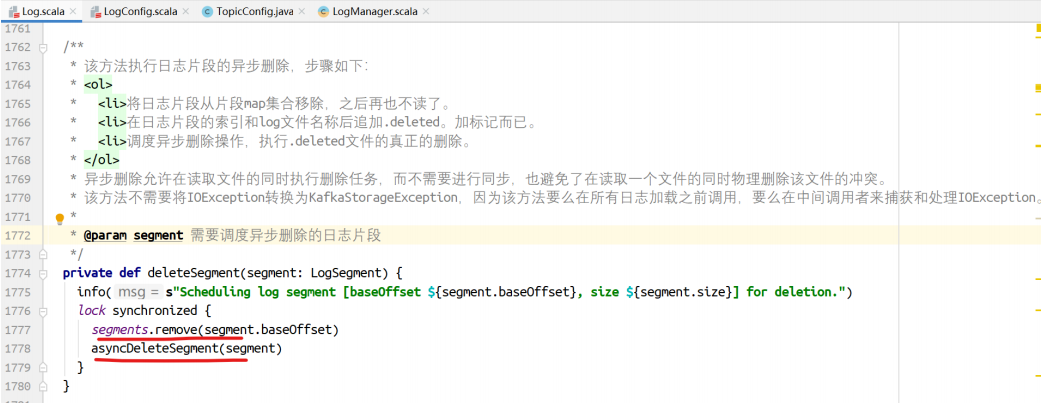
该⽅法执⾏⽇志⽚段的异步删除。步骤如下:
-
将⽇志⽚段的信息从map集合移除,之后再也不读了
-
在⽇志⽚段的索引和log⽂件名称后追加.deleted,加标记⽽已
-
调度异步删除操作,执⾏.deleted⽂件的真正删除。
异步删除允许在读取⽂件的同时执⾏删除,⽽不需要进⾏同步,避免了在读取⼀个⽂件的同时物理删除引起的冲突。
该⽅法不需要将IOException转换为KafkaStorageException,因为该⽅法要么在所有⽇志加载之前调⽤,要么在使⽤中由调⽤者处理IOException。
根据⽇志⽚段⼤⼩进⾏删除。
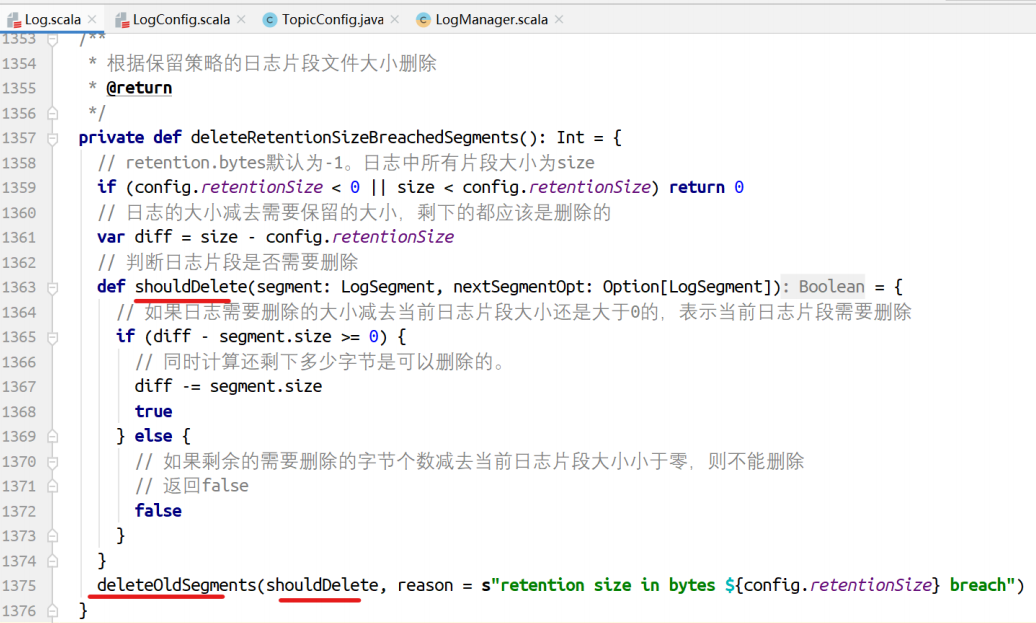
shouldDelete是⼀个函数,作为deleteOldSegments删除⽇志⽚段的判断条件。
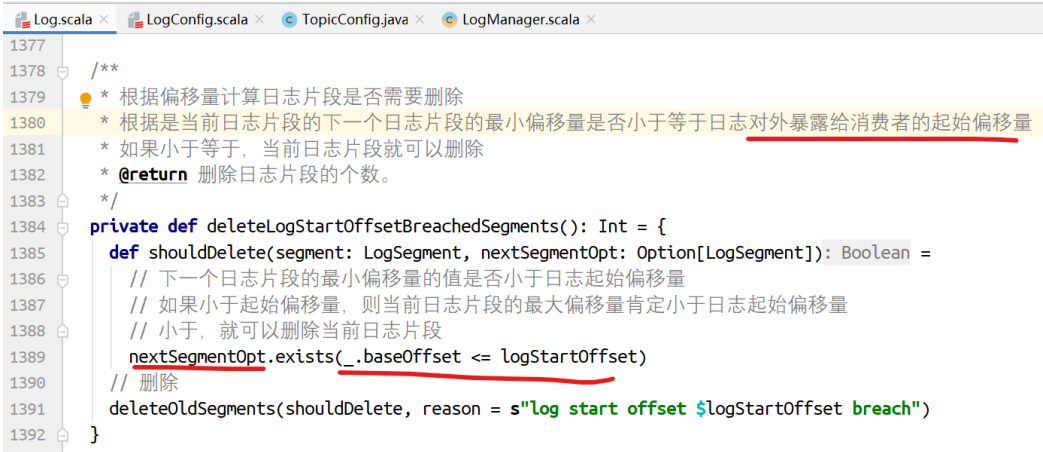
根据偏移量删除⽇志⽚段:对于当前⽇志⽚段是否需要删除,要看它的下⼀个⽇志⽚段的baseOffset是否⼩于等于⽇志对外暴露给消费者的⽇志偏移量,如果⼩,消费者不⽤读取,当前⽇志⽚段就可以删除。
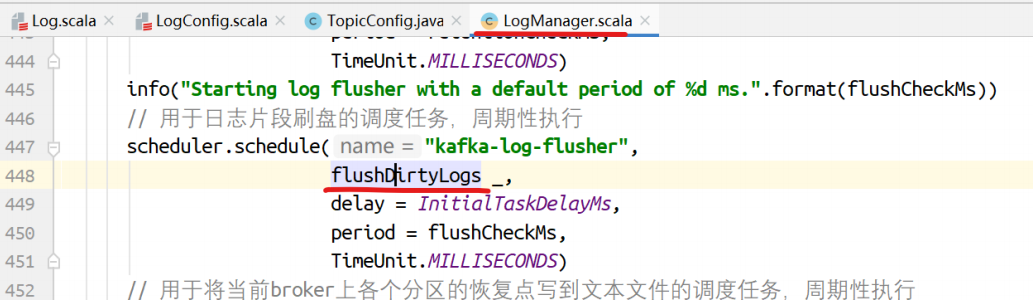
⽇志⽚段刷盘
在LogManager的startup中,启动了刷盘的线程:调⽤flushDirtyLogs⽅法进⾏⽇志刷盘处理。
Kafka推荐让操作系统后台进⾏刷盘,使⽤副本保证数据⾼可⽤,这样效率更⾼。
因此此种⽅式不推荐。
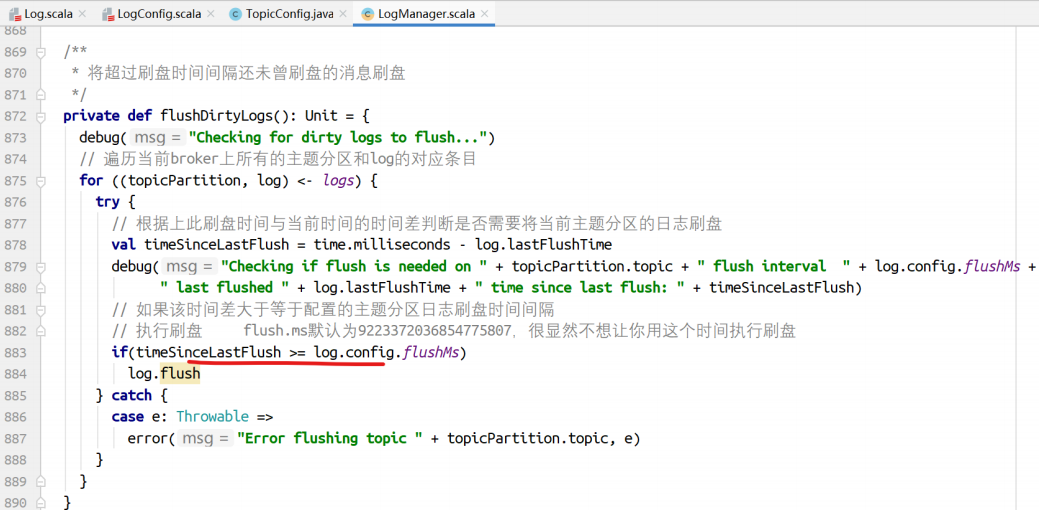
执⾏刷盘的⽅法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| /**
* ⽇志⽚段刷盘到offset-1的偏移量位置。
*
* @param offset 从上⼀个恢复点开始刷盘到该偏移量-1的位置。offset偏移量的不刷盘。
* offset是新的恢复点值。
*/
def flush(offset: Long) : Unit = {
maybeHandleIOException(s"Error while flushing log for $topicPartition in dir ${dir.getParent} with offset $offset") {
// 如果偏移量⼩于等于该⽇志的恢复点,则不需要刷盘
if (offset <= this.recoveryPoint)
return
debug(s"Flushing log up to offset $offset, last flushed: $lastFlushTime,
current time: ${time.milliseconds()}, " + s"unflushed: $unflushedMessages")
// 遍历需要刷盘的⽇志⽚段
for (segment <- logSegments(this.recoveryPoint, offset))
// 执⾏刷盘
segment.flush()
lock synchronized {
// 检查MMAP是否关闭
checkIfMemoryMappedBufferClosed()
// 如果偏移量⼤于恢复点
if (offset > this.recoveryPoint) {
// 设置新的恢复点,表示到达这个偏移量位置的消息都已经刷盘了
this.recoveryPoint = offset
// 设置当前时间为刷盘的时间
lastflushedTime.set(time.milliseconds)
}
}
}
}
|
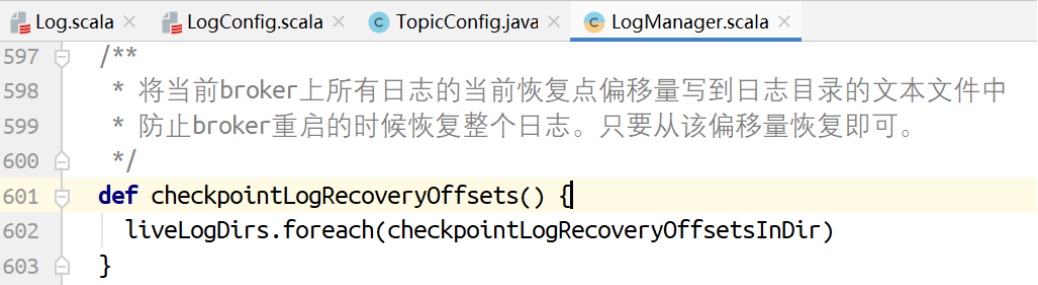
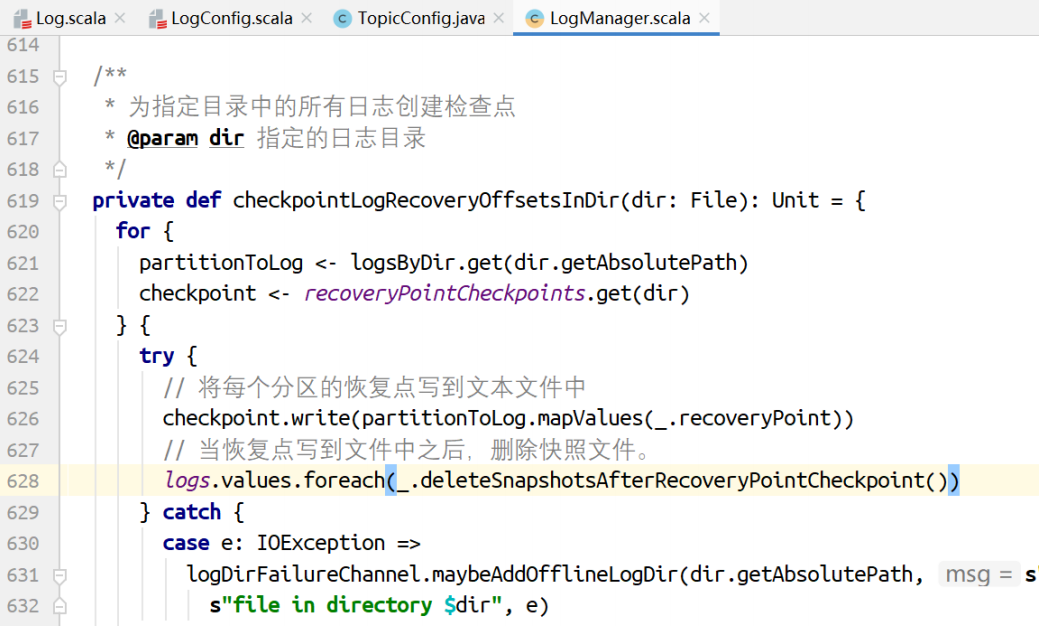
将当前broker上各个分区的恢复点写到⽂本⽂件
将当前broker上各个分区起始偏移量写到⽂本⽂件
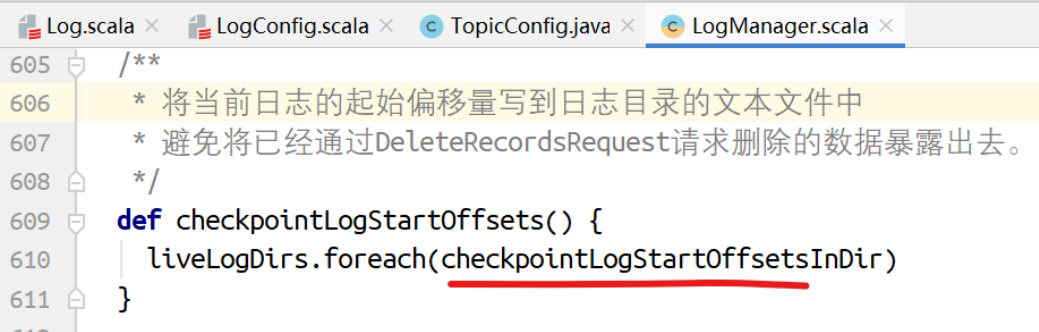
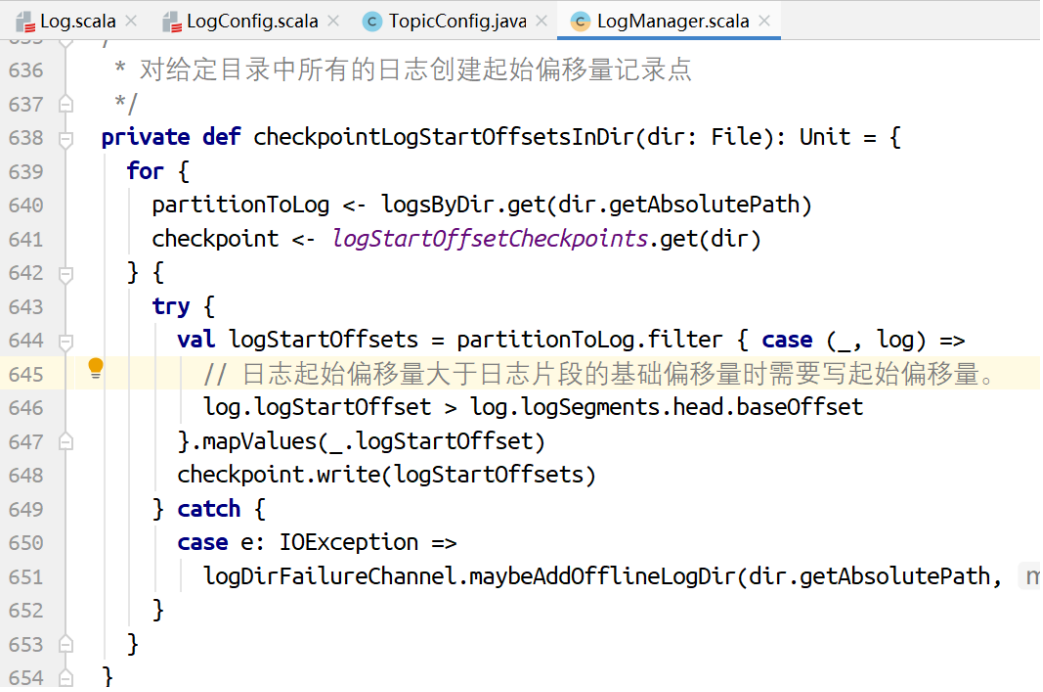
删除⽇志⽚段
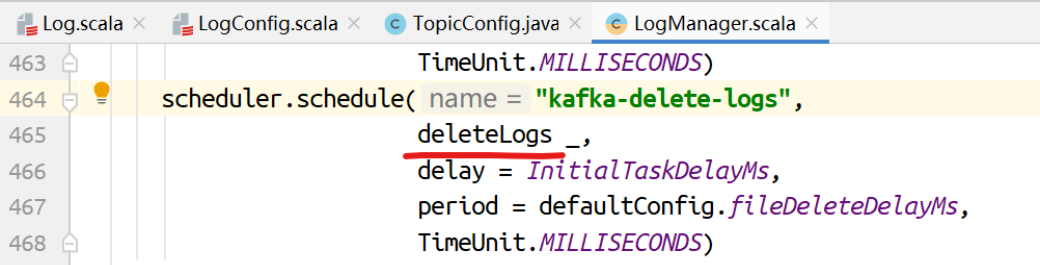
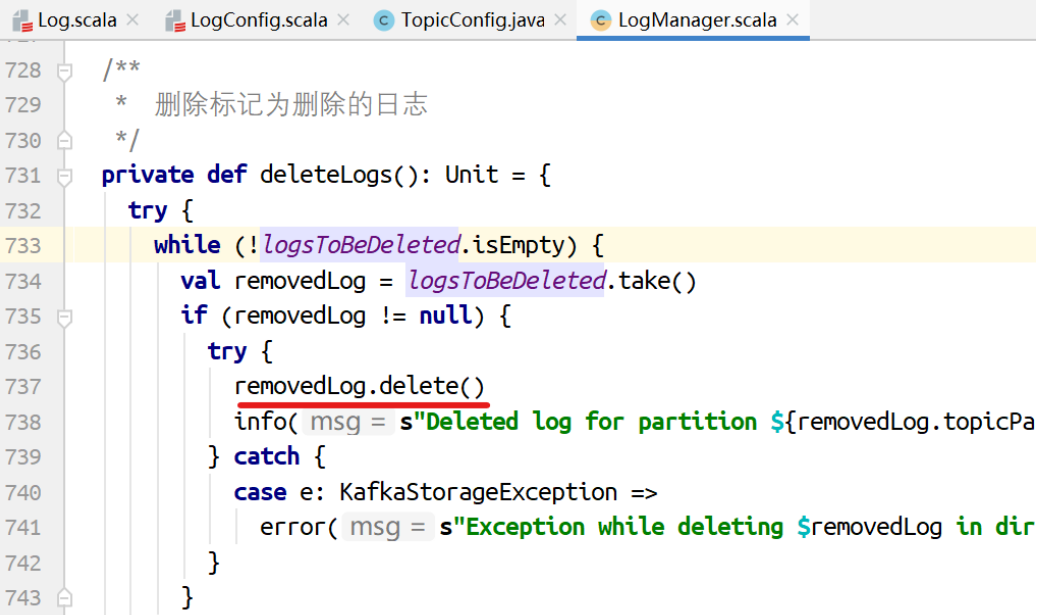
对标记为删除的⽇志执⾏删除的动作。
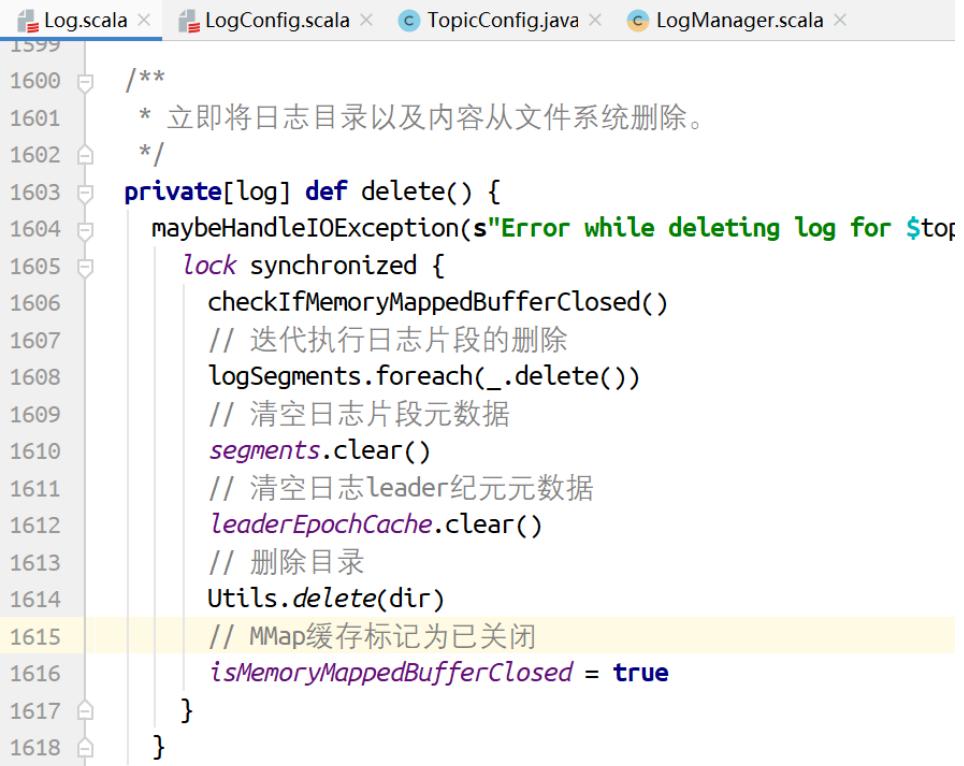
clearner
如果配置了⽇志清理,则启动清理任务。
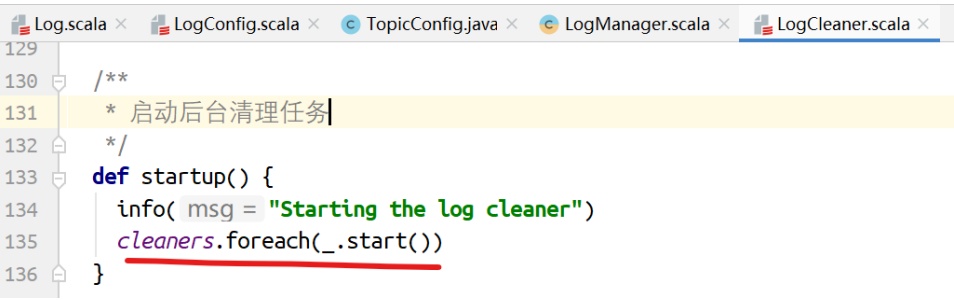
cleaners是多个CleanerThread集合。

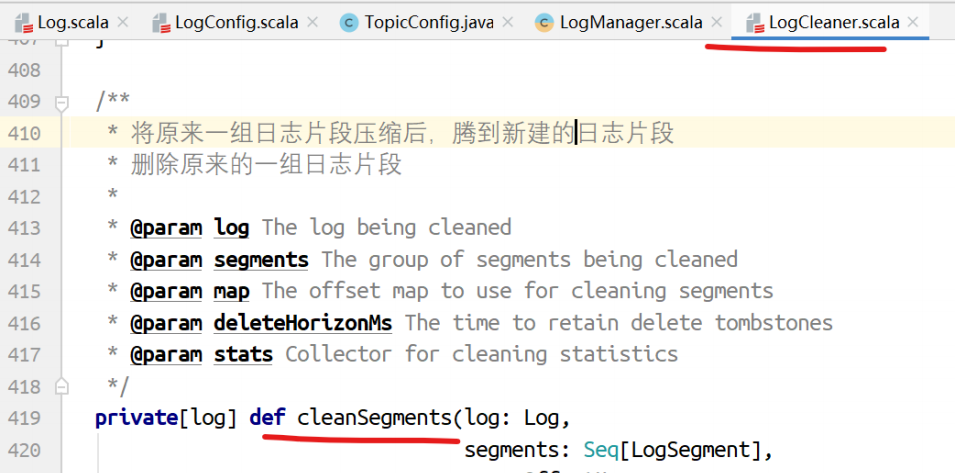
最终执⾏清理的是,压缩。

 wechat
wechat alipay
alipay